



题目:为学生登陆系统新增搜索功能
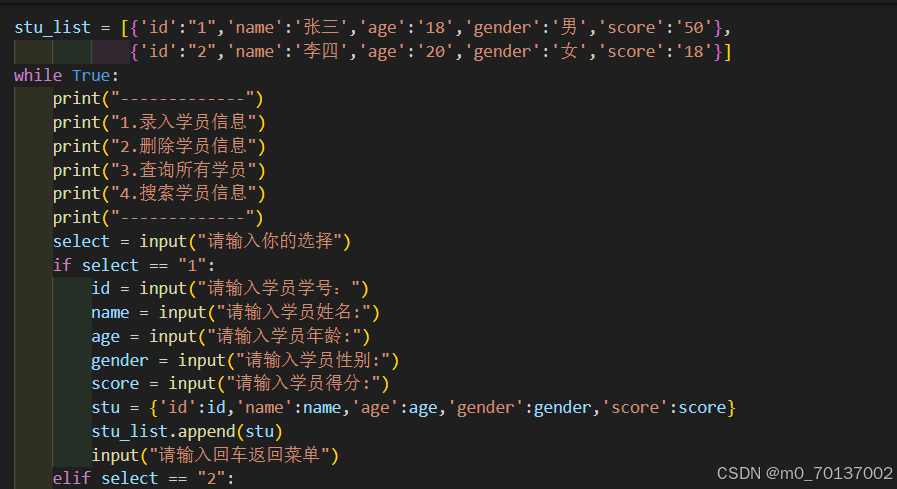
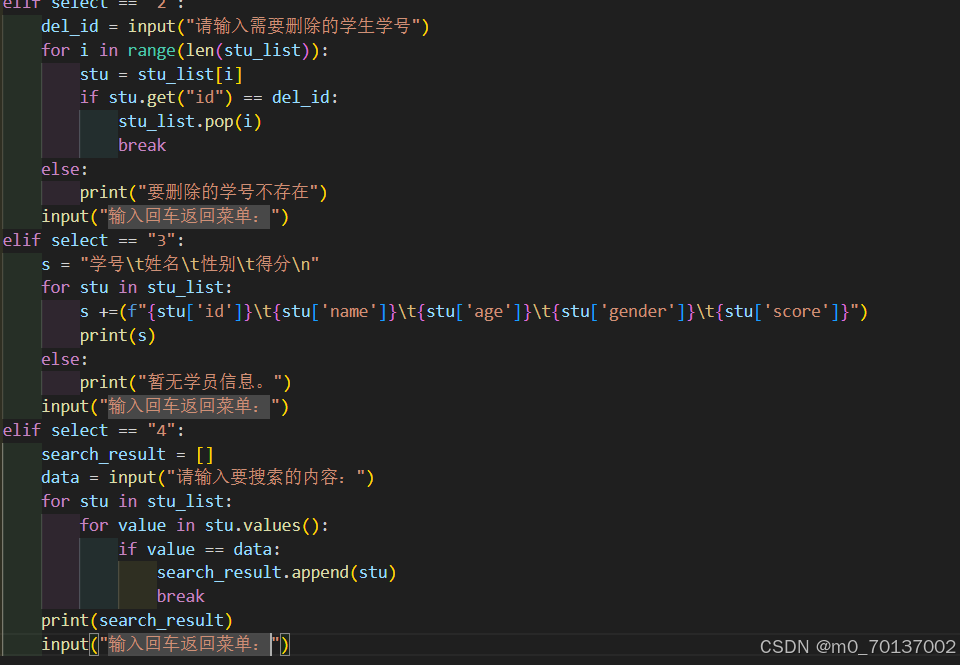
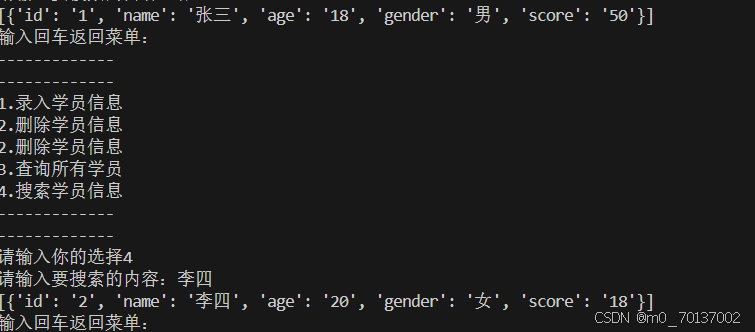
笔记:
一.容器
1.列表
增删改查:
增append(尾部),insert(插入),extend(扩)
删remove(根据元素),pop(根据序号),clear(清空列表)
改ls[4]=500
查print(ls),print(ls[-3])负数
深浅拷贝
浅拷贝:列表中的每一个元素本质上 是数据所在的内存地址 而非数据本身
所以浅拷贝拷贝出来的新数组每一个元素也是原数组内存地址
深拷贝:从头到尾完整将整个数组复制一份
切片技术:切片就是将序列(list,str,tuple)中指定的子序列提取出来
2、元组
元组(tuple)使用小括号创建
元组是一种特殊的列表,他是一旦复制就不可以变化的列
元组是number(int、float)、bool、str、None之后有一个不可变数据类型
元组不支持元素的修改
index 查询某元素的序号
count 统计某元素的出现次数
元组也是支持切片的
print(tp[-1:-4:-1])
"修改"元组:修改的只是元组中的可变数据
二、函数
值传递:传参数的时候,实参将自己 副本 传递到函数中参与运算
引用传递:传参数的时候,实参将自己传递到函数中参与运算
值传递:所有的不可变数据类型都是值传递(number(int,float),str,bool,tuple)
1、匿名函数
lambda函数
语法结构:lambda:参数1,参数2....参数n:一行代码
整个lambda函数只能有一行代码
自动返回代码的运行结果
lambda函数一般会直接作为实参传递其他函数
map函数,他会将传入的序列中的每一个元素 通过一个lambda函数进行修改
filter函数,他会根据lambda函数过滤条件对序列进行筛选
sort函数,根据lambda函数进行排序
2、函数参数
函数的语法结构
def 函数名([参数1,参数2....参数n]):
函数的代码片段
[return 值]
def add(a, b): # a,b叫做形式参数
return a + b # return关键字 不仅仅会返回运算结果 同时他还会立即结束函数
result = add(10, 20) # 10,20 叫做实际参数
print(result)
可变参数:可以0~n个实际参数,会将实际参数打包成元组交给函数运算
在函数 可变参数就是一个元组
def add(*args, a, b, c): # 此时a,b,c出现在可变参数之后,他们不再是位置参数而是 命名参数
命名参数:就是必须指名道姓传参的参数,他一般出现在*args之后或者 * 之后
避免参数过多时,出现传参错误的情况,同时也可以提升代码清晰度,一眼就能知道那个实参传给了哪个形参
关键字参数
关键字参数的自由度非常高,参数的名称可以在传入实参是临时赋予
3、递归函数
递归函数:自己调用自己的函数就叫递归函数,递归本质分治思想,它的思路通常跟我们正常思维不一样
递归必须具备两个条件
1.自己调用自己
2.要有终止递归的条件
4、局部变量和全局变量
内聚性:内聚性越高表示代码对外界以来越低,耦合性越低,内聚性的代码一定程度上会消耗更多的系统资源。所以使用高内聚还是高耦合的代码取决于,你开发的系统他的追求是高性能,易于开发
function()
全局变量可以在程序的任意位置使用
也因为全局变量作用域太大,如果某个脚本,错误的修改了该全局变量,可能会导致程序的问题。
# print(name)
局部变量只能在函数中使用,出了函数无法使用
当我们要使用的数据,就在函数范围内有意义,我们应该使用局部变量。
局部变量可以提升代码的内聚性
如果要在函数中"修改"全局变量,需要使用global对全局变量进行声明


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









