




论文介绍:Graph-BERT 和语言模型在蛋白质-蛋白质交互 (PPI) 识别中的应用
这篇论文提出了一种利用 Graph-BERT 和语言模型的框架,用于蛋白质-蛋白质交互 (PPI) 的预测。以下是其主要内容和模型架构的详细介绍:
研究背景
- 蛋白质是所有生物过程中不可或缺的分子,许多功能依赖于蛋白质之间的交互(如细胞信号传递、DNA 复制等)。
- PPI 数据通常通过实验获得,但实验方法成本高且时间耗费大,且可能产生较高的假阳性和假阴性。
- 为弥补这一不足,基于计算的 PPI 预测方法得到了广泛应用,特别是深度学习模型。
- 现有基于图神经网络(如 GCN)的 PPI 方法可能存在过平滑和悬置动画问题。为此,论文提出了基于 Transformer 的 Graph-BERT 模型,专注于无连接子图(linkless subgraph)学习。
主要贡献
- 将 PPI 预测问题设计为节点分类问题,每个节点表示一个蛋白质对,边定义为共享一个蛋白质的节点对。
- 使用语言模型 (SeqVec) 从蛋白质序列中直接提取节点特征向量,生成 2048 维嵌入。
- 采用 Graph-BERT 学习节点的低维嵌入表示,避免了传统 GCN 的局限。
- 在多个 PPI 数据集上展示了模型的优越性能,相比现有方法取得了更高的准确率。
实验与结果
- 数据集包括人类蛋白质 PPI 数据以及其他物种(E. coli, Drosophila, C. elegan)的数据。
- 实验结果表明,该方法在多个数据集上的准确率均超过 99%,优于现有方法(如 GCN 和 S-VGAE)。
总结与优势
- 创新点:引入语言模型提取蛋白质特征,并结合 Graph-BERT 处理图数据,解决了传统图神经网络的过平滑和悬置动画问题。
- 性能优势:在多个基准数据集上取得了比现有方法更高的预测精度。
未来研究方向包括探索其他预训练语言模型,以及利用更多蛋白质信息(如基因共表达数据)增强节点特征。
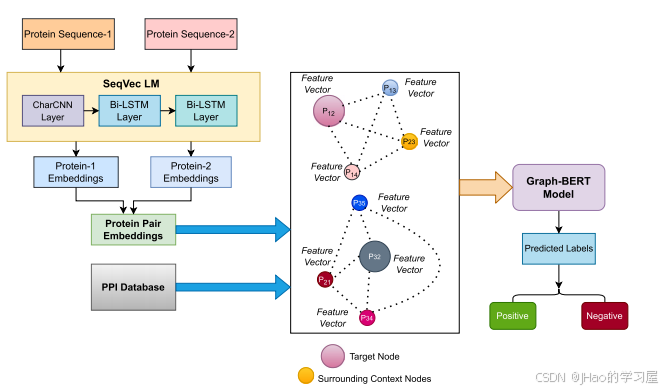
1. 数据输入与图构建
- 输入数据:蛋白质序列和 PPI 网络。
- 图构建:
- 图 ( G_{PPI} = (V, E) ),其中:
- ( V ):节点集,每个节点表示蛋白质对(交互或不交互)。
- ( E ):边集,表示两个节点共享一个蛋白质。
- 每个节点的特征由语言模型 SeqVec 生成,形成 2048 维嵌入向量。
- 图 ( G_{PPI} = (V, E) ),其中:
2. 节点特征嵌入
-
节点的输入特征包含以下四部分:
- 原始特征嵌入:
e x = Embed ( x ) ∈ R d h × 1 e_x = \text{Embed}(x) \in \mathbb{R}^{d_h \times 1} ex=Embed(x)∈Rdh×1
将节点的输入特征 ( x ) 映射到共享特征空间。 - Weisfeiler-Lehman (WL) 绝对角色嵌入:
e r = Position-Embed ( WL ( v ) ) ∈ R d h × 1 e_r = \text{Position-Embed}(\text{WL}(v)) \in \mathbb{R}^{d_h \times 1} er=Position-Embed(WL(
- 原始特征嵌入:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









