




一、消息队列(Message Queue)
1. 基本模型
消息队列提供了一个从一个进程向另一个进程发送数据块的方法。与管道不同的是,消息队列是基于消息(数据块)的,且具有类型(Type)的概念。
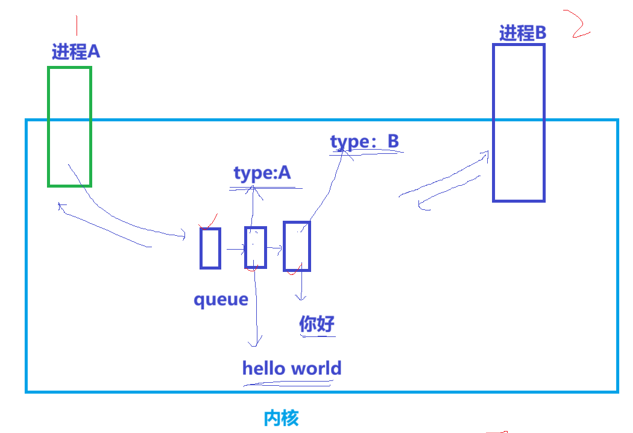
核心概念:
内核管理:消息队列存储在内核中,是一个链表结构。OS需要对这些队列进行管理(先描述,再组织),因此内核中存在描述消息队列的结构体(struct msqid_ds)。
生命周期:消息队列随内核,除非显式删除或系统重启,否则一直存在。
通信方式:
进程A将带有类型(Type: A)的数据块挂入队列。
进程B可以根据类型只读取Type: B的数据,也可以读取Type: A的数据。这使得通信具有了选择性,实现了数据块级别的通信。
唯一标识 (Key):进程A和进程B如何保证看到的是同一个队列?
通过ftok函数,利用相同的路径名(PATHNAME)和项目ID(PROJ_ID)生成同一个key。这个key就是它们握手的凭证。
2. 系统调用接口
2.1 获取/创建队列 (msgget)
#include <sys/types.h>
#include <sys/ipc.h>
#include <sys/msg.h>
int msgget(key_t key, int msgflg);
key:通过ftok生成的键值。
msgflg:
IPC_CREAT:如果不存在则创建,存在则返回ID。
IPC_CREAT | IPC_EXCL:如果不存在则创建,如果存在则报错。这保证了打开的一定是一个全新的队列。
返回值:成功返回消息队列标识符(msqid),失败返回-1。
2.2 控制操作 (msgctl)
用于获取属性或删除队列。
int msgctl(int msqid, int cmd, struct msqid_ds *buf);
cmd:常用 IPC_RMID(立即删除队列)、IPC_STAT(获取队列状态信息)。
struct msqid_ds:内核用来维护队列属性的结构体,包含权限(ipc_perm)、最后发送/接收时间、队列中当前的字节数等信息。
2.3 发送与接收 (msgsnd / msgrcv)

关键结构体 struct msgbuf
由msgp指针指向该结构体,用户必须自己定义这个结构体,且必须遵循以下形式:
struct msgbuf {
long mtype; /* 消息类型,必须 > 0 */
char mtext[1]; /* 消息数据,大小由用户定义 */
};
发送消息:
int msgsnd(int msqid, const void *msgp, size_t msgsz, int msgflg);
msqid (Message Queue ID):
消息队列的标识符(由 msgget 创建或获取后返回的ID)。
msgp (Message Pointer):
指向消息结构体的指针。
图片中的箭头指向了右上角的 struct msgbuf data = {1, "helloworld"};。这意味着你需要把这个结构体的地址传进去(例如 &data)。
msgsz (Message Size):
注意:这是消息正文(mtext)的大小,不包含 消息类型(mtype)的大小。
计算公式通常是:sizeof(struct msgbuf) - sizeof(long)。
msgflg (Message Flag):
控制标记位。通常设置为 0(阻塞发送),或者 IPC_NOWAIT(非阻塞,队列满时立即报错返回)。
接收消息:
ssize_t msgrcv(int msqid, void *msgp, size_t msgsz, long msgtyp, int msgflg);
msgp:
输出型参数。用于存放从队列中取出的消息。
图片右侧有一个 struct msgbuf data;,箭头指向这里,表示接收到的数据会被写入这个变量中。
msgsz:
msgp 指向的缓冲区中,mtext 部分的最大长度。这防止内核写入数据时发生缓冲区溢出。
msgtyp (Message Type):
消息类型过滤器。
图片中手写了一个数字 2 指向这里。这表示:
如果 msgtyp > 0(例如传2):只读取队列中类型为2的第一条消息。
如果 msgtyp == 0:读取队列中的第一条消息(不区分类型)。
如果 msgtyp < 0:读取类型小于等于 msgtyp 绝对值的消息中类型最小的那一条。
msgflg:
控制标记位,如 0(阻塞等待消息)或 IPC_NOWAIT(没消息直接返回)。
二、并发编程与同步互斥
1. 为什么会有并发问题?
当多个执行流(进程)同时运行时,如果它们没有任何交互,那是相安无事的。但实际上,进程间往往需要通信,这就意味着它们需要看到同一份资源(文件、内存块、队列等)。
2. 核心概念定义
-
共享资源:被多个执行流都能看到的资源。
-
临界资源:被保护起来的共享资源。
-
临界区:进程中访问临界资源的那段代码。(临界区+非临界区==咱们的代码)
-
互斥:在任何时刻,只允许一个执行流进入临界区访问资源。
-
原子性:一个操作要么不做,要么做完,中间不能被打断。两态操作。
三、System V 信号量
消息队列解决的是数据传输问题,而信号量解决的是进程同步与互斥问题。
1. 什么是信号量?
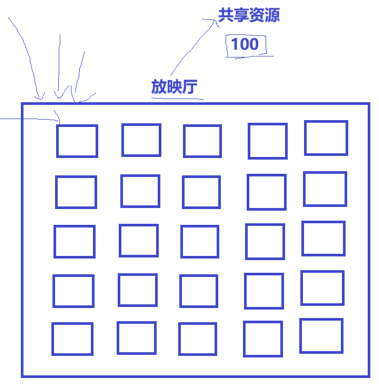
可以将信号量理解为一个计数器,用来描述临界资源的数量。
比喻:电影院买票。
电影院座位 = 临界资源。
票数(如100张) = 信号量的初始值。
买票 = 申请信号量(P操作)。
预定机制:买票的本质是对资源的预定。一旦你买到了票(信号量申请成功),即便你还没进去坐下,那个座位逻辑上已经属于你了。
操作流程:
申请资源(P操作):检查计数器。
如果 sem > 0,则 sem--,允许访问。
如果 sem == 0,则挂起等待(阻塞)。
释放资源(V操作):访问完毕,离开。
sem++,唤醒等待的进程。
2. 二元信号量 vs 多元信号量
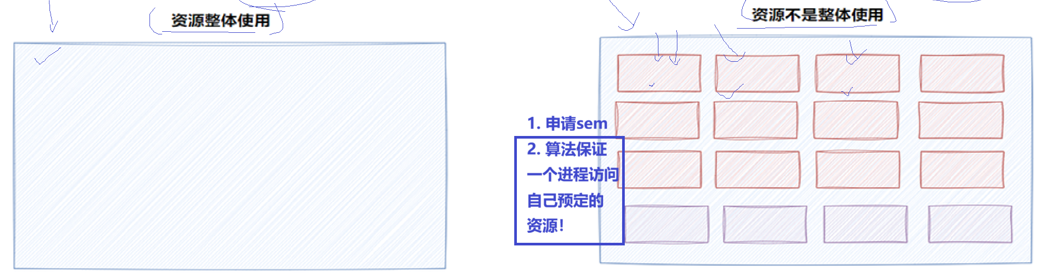
二元信号量 (sem = 1):
计数器只能是0或1。
这相当于互斥锁 (Mutex)。
场景:资源是一个整体,一次只允许一个进程访问(如超级VIP放映厅,只有一个座位)。
多元信号量 (sem = N):
资源被划分为多个小块(如电影院有多个座位)。
场景:允许多个进程并发进入,但需要算法保证它们访问的是资源的不同区域。
3. 问题一:信号量的原子性问题
这里有一个逻辑闭环的难点:
信号量是用来保护临界资源的,但为了让所有进程都能看到信号量,信号量本身也是一个共享资源。那么,谁来保护信号量呢?
必须保证信号量的操作(PV操作)是原子的!
为什么代码中手写的 sem-- 不是原子的?
在C语言中看似一行代码 sem--,在汇编层面对应了三条指令:
Load: 将内存数据加载到CPU寄存器。
Dec: 在CPU内进行减1操作。
Store: 将结果写回内存。
风险:如果进程在执行完第2步被切走了,另一个进程进来读到了旧值,就会导致计数器错误。
解决方案:System V 信号量的底层(P/V操作)由操作系统内核提供支持,确保了其执行的原子性。你不需要担心信号量本身的竞争问题。
总结为能转变成一行汇编语句的操作就是原子操作
4. 问题2:如何保证多个进程看到同一个sem
背景:进程具有独立性(各自有独立的地址空间)。如果进程A在自己的内存里定义了一个变量 int sem = 1,进程B也在自己的内存里定义了一个 int sem = 1,这两个变量虽然名字一样,但互不相关。
问题:如果它们看的是两个不同的计数器,那么互斥保护就失效了
解决方法:
依靠 key_t key(键值)。
所有进程只要约定好使用同一个路径名和项目ID,通过 ftok 函数就能生成同一个唯一的 key。
拿着这个 key 去找操作系统,操作系统就会把内核中维护的同一个信号量集(semid)返回给这些进程。
四、内核是如何组织管理IPC资源的
在Linux系统编程中,System V IPC(Inter-Process Communication)是经典的三大通信机制:消息队列 (Message Queue)、共享内存 (Shared Memory) 和 信号量 (Semaphore)。
当我们学习这三个组件的API时,会发现它们惊人地相似:都有 xxxget 创建/获取接口,都有 xxxctl 控制接口,且参数设计高度一致。为什么它们会长得这么像?内核底层究竟是如何组织和管理这三种截然不同的资源的?
1. 现象:IPC接口的高度相似性
从用户层看,它们的功能截然不同:
-
msg 是一个链表队列。
-
sem 是一个计数器数组。
-
shm 是一块物理内存映射。
但从内核角度看,它们遵循同一个公式:
IPC资源 = 内核数据结构 + 资源本身
操作系统为了管理方便,将“管理”与“资源本身”进行了解耦。无论后面挂的是队列、计数器还是内存块,管理它们的头部数据结构是统一的。
2. 核心设计:C语言实现的“继承与多态”
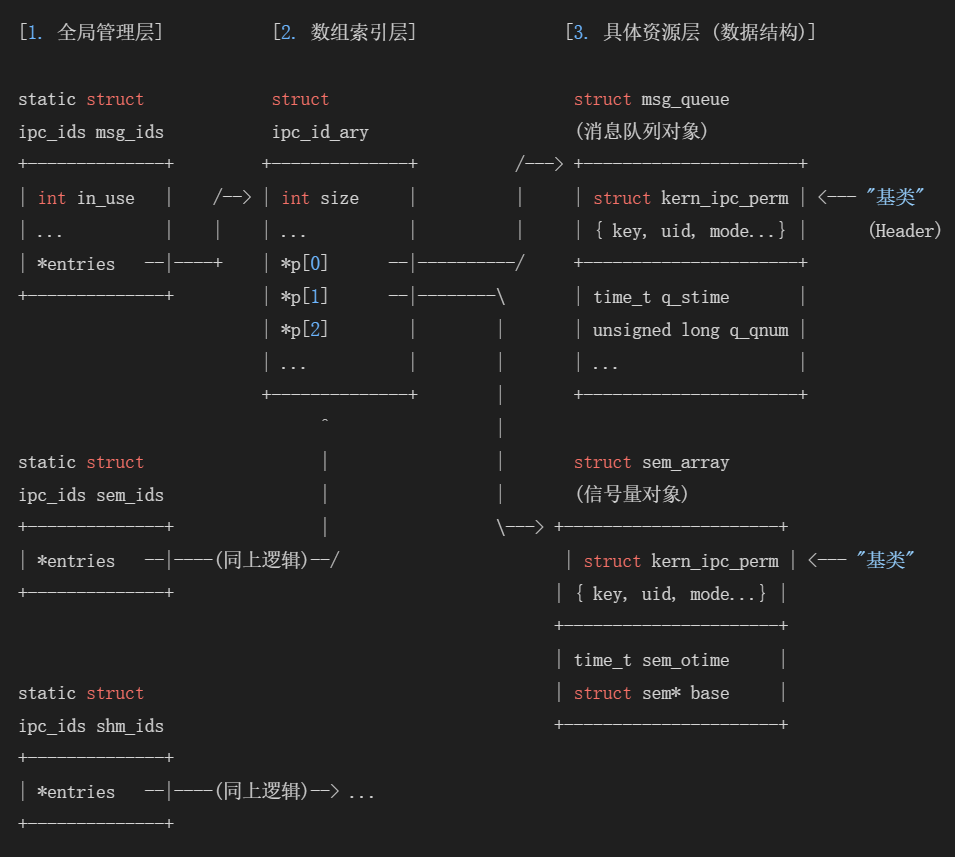
要理解内核的管理方式,必须看懂这张核心架构图(图1)以及其中的结构体嵌套关系。
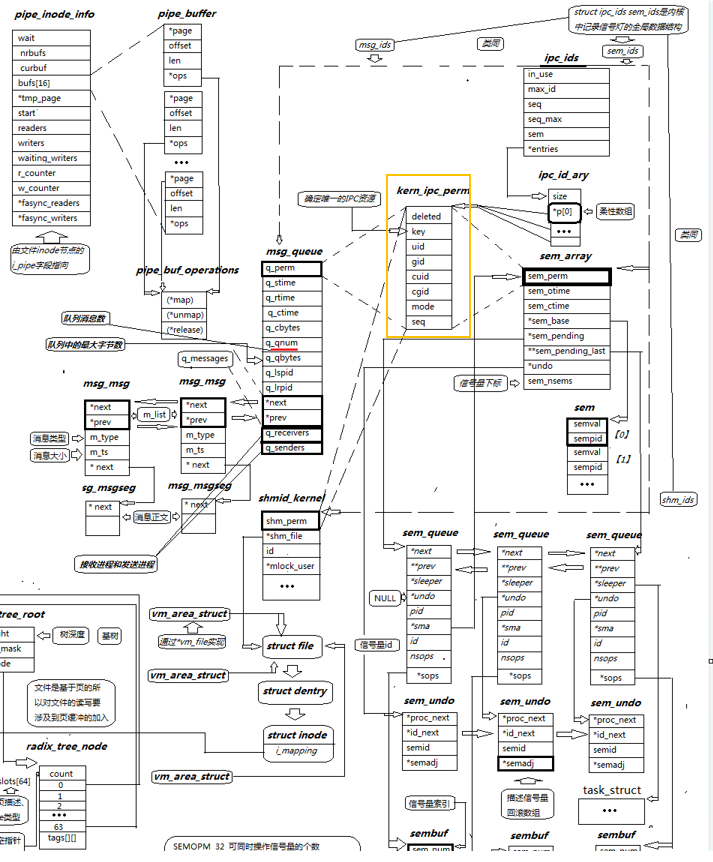
2.1 “基类”:struct kern_ipc_perm
Linux内核中定义了一个核心结构体 struct kern_ipc_perm(在图中黄色标记)。它包含了所有IPC资源共有的属性:
-
key:用户层传递的键值。
-
uid/gid:所有者ID和组ID。
-
mode:读写权限。
-
seq:序列号。
2.2 “子类”:具体资源的结构体
内核在定义具体的IPC资源结构体时,采用了一个极其巧妙的设计:将 kern_ipc_perm 放在结构体的第一个成员位置。
这就是“C语言实现多态”以及“面试题”的核心答案。这种设计使得内核可以用一套通用的算法(ID分配、权限检查、数组扩容)来管理截然不同的资源,极大地降低了代码耦合度。
-
消息队列 (struct msg_queue):
struct msg_queue { struct kern_ipc_perm q_perm; // "基类"在第一位 // ... 队列特有属性:队头、队尾、消息数 ... }; -
信号量 (struct sem_array):
struct sem_array { struct kern_ipc_perm sem_perm; // "基类"在第一位 // ... 信号量特有属性:信号量指针、撤销队列 ... }; -
共享内存 (struct shmid_kernel):
struct shmid_kernel { struct kern_ipc_perm shm_perm; // "基类"在第一位 // ... 共享内存特有属性:文件指针、大小 ... };这种结构体嵌套的方式,在C语言中模拟了面向对象编程中的继承。因为结构体的地址等于其第一个成员的地址,所以指向具体资源(如 msg_queue)的指针,可以无缝强制类型转换为 kern_ipc_perm* 指针。
3. 内核的组织方式:数组与指针
搞清楚了结构体关系,我们再看内核是如何把成千上万个IPC资源管理起来的。
-
3.1 全局管理结构 struct ipc_ids
内核中定义了三个静态全局变量来分别管理三种IPC:
static struct ipc_ids msg_ids; // 管理所有消息队列 static struct ipc_ids sem_ids; // 管理所有信号量 static struct ipc_ids shm_ids; // 管理所有共享内存3.2 柔性数组与动态扩容
在 struct ipc_ids 内部,有一个核心成员 entries,它指向一个 struct ipc_id_ary。这个结构体里包含了一个柔性数组:
struct ipc_id_ary { int size; struct kern_ipc_perm *p[0]; // 柔性数组 };关键点来了: 这个数组 p[] 存放的类型是 struct kern_ipc_perm*。
无论用户创建的是消息队列、信号量还是共享内存,内核只需要把它们统一当成 kern_ipc_perm 类型的指针存入这个数组即可。3.3 访问资源的流程(C语言多态的实现)
当我们调用 msgget 或 shmget 成功后,返回的整数(ID)本质上就是这个数组的下标。
当我们需要访问具体资源时(例如图数组索引层逻辑):
-
内核根据 ID 找到数组下标 p[ID]。
-
获取到的是 struct kern_ipc_perm* 指针。
-
强制类型转换(Downcasting):
-
如果是 msg_ids 里的数组,就强转为 (struct msg_queue*)。
-
如果是 shm_ids 里的数组,就强转为 (struct shmid_kernel*)。
-
4. 总结:内核如何组织IPC?
回答标题的问题,内核组织IPC资源的逻辑可以概括为三层金字塔:
-
最底层(数据结构层):
利用结构体嵌套(struct kern_ipc_perm 在首位),实现了所有IPC资源描述信息的统一,这是C语言层面的“多态”基础。 -
中间层(组织层):
利用 struct ipc_ids 和指针数组,将异构的资源统一存储为基类指针。数组下标即为我们看到的 IPC ID。 -
最上层(接口层):
向用户提供统一风格的 System V 标准接口(get, ctl, op),屏蔽了底层的复杂转换。

















 2791
2791

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









