



摘要:尽管近期诸如CLIP和SigLIP等图像-文本对比模型取得了成功,但这些模型在处理需要高精度图像理解的视觉中心任务时常常面临挑战,例如计数、深度估计和细粒度物体识别。这些模型通过执行语言对齐,往往更侧重于高层语义而非视觉理解,从而削弱了其图像理解能力。另一方面,专注于视觉的模型在处理视觉信息方面表现出色,但在理解语言方面存在困难,这限制了它们在语言驱动任务中的灵活性。在本研究中,我们引入了TULIP,这是一种开源的、可直接替代现有CLIP类模型的方案。我们的方法利用生成式数据增强、增强的图像-图像和文本-文本对比学习,以及图像/文本重建正则化,来学习细粒度的视觉特征,同时保持全局语义对齐。我们的方法可扩展到超过10亿个参数,在多个基准测试中超越了现有的最先进(SOTA)模型,在ImageNet-1K上建立了新的SOTA零样本性能,在RxRx1的线性探测少样本分类中相较于SigLIP实现了高达2倍的提升,并改进了视觉-语言模型,在MMVP上取得了比SigLIP高3倍以上的分数。我们的代码/检查点可在https://tulip-berkeley.github.io获取。Huggingface链接:Paper page,论文链接:2503.15485
研究背景和目的
研究背景
随着人工智能技术的飞速发展,图像和文本作为两种最基本的信息载体,其交互和理解成为了人工智能研究领域的热点。图像-文本对比学习模型,如CLIP和SigLIP,已经在多个视觉和语言任务中取得了显著的成功。这些模型通过在大规模数据集上学习图像和文本之间的共享嵌入空间,实现了跨模态的语义对齐。然而,尽管这些模型在高层语义任务上表现优异,但它们在处理需要高精度图像理解的视觉中心任务时常常表现不佳。这些任务包括计数、深度估计、细粒度物体识别等,它们要求模型对图像中的细节有深刻的理解。
现有的图像-文本对比模型在处理这些任务时面临两大挑战。首先,这些模型通常通过执行语言对齐来优化全局语义对齐,从而在高层语义任务上表现出色。然而,这种策略往往导致模型在视觉细节上的理解能力不足,无法准确地捕捉图像中的细微差别。其次,专注于视觉的模型虽然擅长处理视觉信息,但在理解语言方面存在困难,这限制了它们在语言驱动任务中的灵活性和应用范围。
因此,开发一种能够同时处理视觉和语言信息,并在两种模态之间实现有效对齐的模型,成为了当前研究的迫切需求。这种模型不仅需要具备强大的全局语义对齐能力,还需要能够捕捉图像中的细粒度视觉特征,以满足各种视觉和语言任务的需求。
研究目的
针对现有图像-文本对比模型在处理视觉中心任务时的局限性,本研究旨在提出一种新型的统一语言-图像预训练方法(TULIP)。TULIP旨在通过结合生成式数据增强、增强的图像-图像和文本-文本对比学习,以及图像/文本重建正则化,来学习细粒度的视觉特征,同时保持全局语义对齐。具体研究目的包括:
- 提升视觉理解能力:通过引入生成式数据增强和增强的图像对比学习,使模型能够捕捉图像中的细粒度视觉特征,提升其在视觉中心任务上的表现。
- 保持全局语义对齐:在提升视觉理解能力的同时,确保模型在全局语义对齐方面不受到影响,保持其在高层语义任务上的优异性能。
- 实现跨模态的灵活应用:通过开发一种统一的预训练方法,使模型能够在视觉和语言两种模态之间实现有效对齐,从而在各种视觉和语言任务中实现灵活应用。
- 推动视觉-语言模型的发展:通过提出一种新型的预训练方法,为视觉-语言模型的发展提供新的思路和方法,推动该领域的研究进步。
研究方法
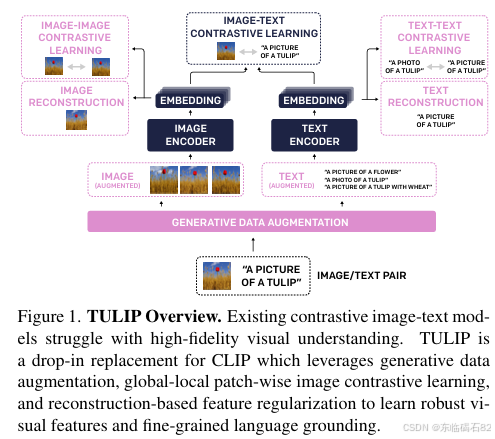
1. 生成式数据增强
为了丰富训练数据,提升模型的泛化能力,本研究引入了生成式数据增强策略。具体来说,我们利用大型生成模型(如语言模型和图像编辑模型)来生成多样化的对比视图。这些视图包括正样本(语义相同但表现形式不同的视图)和负样本(语义不同但视觉相似的视图)。通过将这些生成的数据融入对比学习框架中,我们能够使模型学习到更加鲁棒的视觉和文本表示。
2. 增强的图像-图像和文本-文本对比学习
除了传统的图像-文本对比学习外,本研究还引入了增强的图像-图像和文本-文本对比学习。对于图像对比学习,我们利用生成式数据增强策略生成的正负样本视图进行训练,使模型能够学习到图像在不同视角下的不变性。对于文本对比学习,我们利用大型语言模型生成语义相近和语义相远的文本对,进行文本表示的对比学习。通过这些增强的对比学习任务,我们能够进一步提升模型的跨模态语义对齐能力。
3. 图像/文本重建正则化
为了鼓励模型编码图像和文本中的关键视觉和文本细节,本研究引入了图像/文本重建正则化。具体来说,我们利用掩码自编码器(MAE)和因果解码器(基于T5)来重建输入图像和文本。通过最小化重建误差,我们能够迫使模型在编码过程中保留关键细节信息,从而提升其在视觉和语言任务上的表现。
4. TULIP模型架构
TULIP模型架构由图像编码器和文本编码器组成。图像编码器采用ViT模型作为骨干网络,并结合EMA教师模型进行图像对比学习。文本编码器采用SigLIP的语言编码器,并结合因果解码器进行文本重建。在训练过程中,我们利用生成式数据增强策略生成的正负样本视图进行图像-图像、图像-文本和文本-文本的对比学习,并通过图像/文本重建正则化来保留关键细节信息。
研究结果
1. 零样本分类性能
在ImageNet-1K、ObjectNet等零样本分类基准测试上,TULIP模型取得了显著优于现有最先进模型的结果。特别是在ImageNet-1K上,TULIP模型建立了新的SOTA零样本性能,展示了其强大的跨模态语义对齐能力。
2. 视觉和语言任务性能
在文本到图像检索、图像到文本检索等视觉和语言任务上,TULIP模型也取得了优异的表现。特别是在RxRx1的线性探测少样本分类任务中,TULIP模型相较于SigLIP实现了高达2倍的提升,展示了其在处理视觉中心任务时的优势。
3. 多模态推理能力
在BLINK和Winoground等多模态推理基准测试上,TULIP模型也取得了显著优于现有模型的结果。特别是在Winoground的组分数上,TULIP模型是唯一一个超越随机猜测的CIT模型,展示了其强大的多模态推理能力。
4. 视觉-语言模型性能
作为特征编码器应用于大规模多模态模型(如LLaVA)时,TULIP模型也取得了优于现有视觉和语言模型的结果。特别是在MMVP基准测试上,TULIP模型取得了比SigLIP高3倍以上的分数,展示了其在视觉-语言模型中的广泛应用前景。
研究局限
尽管TULIP模型在多个基准测试上取得了显著优于现有模型的结果,但其仍存在一些局限性。首先,TULIP模型的性能在很大程度上依赖于生成式数据增强策略的有效性。如果生成的数据质量不高或多样性不足,可能会对模型的性能产生负面影响。其次,TULIP模型在训练过程中需要消耗大量的计算资源和时间,这对于普通用户来说可能是一个不小的挑战。此外,TULIP模型在处理某些极端复杂或罕见的视觉和语言任务时可能仍存在不足,需要进一步的改进和优化。
未来研究方向
针对TULIP模型的局限性,未来研究可以从以下几个方面展开:
-
提升生成式数据增强的质量和多样性:通过改进生成模型的架构和训练方法,提升生成数据的质量和多样性,从而进一步提高TULIP模型的性能。
-
优化模型训练过程:通过引入更高效的训练算法和硬件加速技术,降低TULIP模型的训练成本和时间,使其更加易于部署和应用。
-
拓展应用场景:将TULIP模型应用于更多的视觉和语言任务中,探索其在不同领域和场景下的应用潜力和价值。
-
结合其他技术:将TULIP模型与其他先进技术(如自监督学习、强化学习等)相结合,进一步提升其性能和应用范围。
-
解决极端复杂任务:针对某些极端复杂或罕见的视觉和语言任务,进一步改进和优化TULIP模型的架构和训练方法,提升其处理这些任务的能力。
综上所述,TULIP模型作为一种新型的统一语言-图像预训练方法,在提升视觉理解能力、保持全局语义对齐、实现跨模态灵活应用等方面具有显著的优势。未来研究将继续探索其潜力和应用前景,推动视觉-语言模型的发展进步。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









