






博主介绍:
✌我是阿龙,一名专注于Java技术领域的程序员,全网拥有10W+粉丝。作为优快云特邀作者、博客专家、新星计划导师,我在计算机毕业设计开发方面积累了丰富的经验。同时,我也是掘金、华为云、阿里云、InfoQ等平台的优质作者。通过长期分享和实战指导,我致力于帮助更多学生完成毕业项目和技术提升。技术范围:
我熟悉的技术领域涵盖SpringBoot、Vue、SSM、HLMT、Jsp、PHP、Nodejs、Python、爬虫、数据可视化、小程序、安卓app、大数据、物联网、机器学习等方面的设计与开发。如果你有任何技术难题,我都乐意与你分享解决方案。主要内容:
我的服务内容包括:免费功能设计、开题报告、任务书、中期检查PPT、系统功能实现、代码编写、论文撰写与辅导、论文降重、长期答辩答疑辅导。我还提供腾讯会议一对一的专业讲解和模拟答辩演练,帮助你全面掌握答辩技巧与代码逻辑。🍅获取源码请在文末联系我🍅
温馨提示:文末有 优快云 平台官方提供的阿龙联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的阿龙联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的阿龙联系方式的名片!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人

目录:
源码获取文章下方名片联系我即可~大家点赞、收藏、关注、评论啦 、查看👇🏻获取联系方式👇🏻精彩专栏推荐订阅:在下方专栏
一、详细操作演示视频
在文章的尾声,您会发现一张电子名片👤,欢迎通过名片上的联系方式与我取得联系,以获取更多关于项目演示的详尽视频内容。视频将帮助您全面理解项目的关键点和操作流程。期待与您的进一步交流!

摘 要
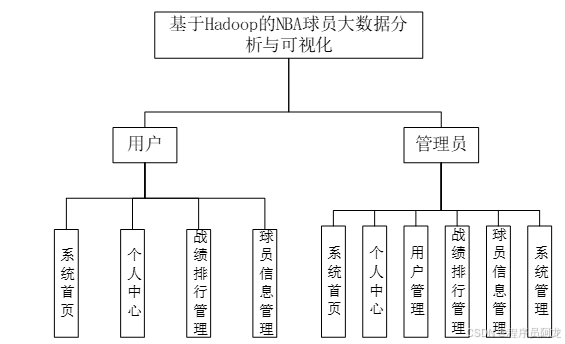
科学技术日新月异,人们的生活都发生了翻天覆地的变化,NBA球员大数据分析与可视化系统当然也不例外。过去的信息管理都使用传统的方式实行,既花费了时间,又浪费了精力。在信息如此发达的今天,可以通过网络这个媒介,快速的查找自己想要的信息,更加全方面的了解自己的网站信息。而且人们也可以突破传统信息管理的僵硬模式,制定属于自己的个性化的管理方案。基于现代人们的需求,设计并开发了一款NBA球员大数据分析与可视化。
本文基于Hadoop平台,针对NBA球员的大数据进行了分析和可视化。首先,通过数据采集和清洗,获取了包括球员个人信息、比赛数据、进球数据等多维度数据。然后,利用Hadoop集群进行数据处理和计算,包括统计各球员在不同场次中的表现指标,比如得分、篮板、助攻等。接着,通过数据可视化工具,如Tableau或matplotlib,对数据进行可视化展示,包括图表、雷达图、热力图等形式,以便进一步的数据分析和挖掘。通过这样的大数据分析与可视化方法,可以帮助球队教练和管理者更好地了解球员个人表现和团队整体水平,以做出更有效的战术和人员调整。
2.1系统的开发环境与开发工具
本系统在开发时选用Windows10中文家庭版为操作系统,选用了JAVA语言,与此同时选用了Mysql为数据库开发工具,两者的兼容性能是最佳的,所以很适合用来开发这款系统。
网页制作以及代码的编写,运用IDEA开发工具,它不仅可以清晰的整理代码。而且还具有可视化的操作界面,提高了编写代码的效率。数据库采用MySQL,与编程开发工具兼容,易于管理维护。
2.2 JAVA技术概述
Java主要采用CORBA技术和安全模型,可以在互联网应用的数据保护。它还提供了对EJB(Enterprise JavaBeans)的全面支持,java servlet API,SSM(java server pages),和XML技术。Java是一种计算机编程语言,具有封装、继承和多态性三个主要特性,广泛应用于企业Web应用程序开发和移动应用程序开发。Java语言和一般编译器以及直译的区别在于,Java首先将源代码转换为字节码,然后将其转换为JVM的可执行文件,JVM可以在各种不同的JVM上运行。因此,实现了它的跨平台特性。虽然这使得Java在早期非常缓慢,但是随着Java的开发,它已经得到了改进。
2.3 Springboot 框架
现如今后台开源框架主流的有SSH、SSM、SSpringboot,但是SSH、SSM框架的环境配置项较多,而SSpringboot主要的设计思想就是约定大于配置,故而SpingBoot在设计时几乎达到零配置。SSpringboot整合了业界上的开源框架。具体采用技术框架描述如下:
(1)Mybatis:Mybatis:提供自动映射,动态SQL,级联,缓存,注解,代码和SQL分离等特性,使用方便,同时也对SQL进行优化。
(2)SpringMVC:通过一套MVC注解,让POJO成为处理请求的控制器,无需实现任何接口,同时,SpringMVC还支持REST风格的URL请求。
(3)SSpringboot:从本质上来说,Spring Boot就是Spring,它做了那些没有它你也会去做的Spring Bean配置。
SSpringboot是一款非常强大后台框架,因为SSpringboot开发时可以基本不用写配置文件,所以使用SSpringboot搭建网站的后台环境,在SSpringboot的yml配置文件中写入项目启动端口,项目就可以启动。项目的Java文件还有静态文件都是由SSpringboot来管理。
2.4 Vue.js技术
Vue.js是一款轻量级的JAVAScript框架,用于构建用户界面。它采用了组件化的开发方式,使得代码更加模块化、易于维护和复用。Vue.js还提供了数据双向绑定的功能,使得开发者可以更加方便地管理页面的状态。此外,Vue.js还支持虚拟DOM技术,可以提高页面渲染的性能。Vue.js的学习曲线较为平缓,适合初学者入门。目前,Vue.js已经成为了国内最热门的前端框架之一,被广泛应用于各种类型的项目中。
2.5 Mysql数据库技术
MySQL是一种关系型数据库管理系统,由瑞典MySQL AB公司开发,目前属于Oracle公司。MySQL是一种通用的、开源的关系型数据库管理系统,广泛应用于各种类型的项目中,如网站、企业级应用等。MySQL支持多种存储引擎,包括InnoDB、MyISAM等,可以根据项目需求选择合适的存储引擎。MySQL具有高性能、高可靠性、易用性等特点,被广泛应用于各种类型的项目中。
2.6 Hadoop介绍
Hadoop是一个由Apache基金会维护的开源框架,它允许分布式处理大数据集在计算集群中的大规模数据。它的核心设计哲学是将应用程序带到数据所在的位置,而不是将大量数据传输到应用程序所在的服务器。Hadoop主要由两个组件组成:Hadoop Distributed File System(HDFS)和MapReduce。HDFS提供了高度可靠、高吞吐量的数据存储解决方案,而MapReduce则是一个编程模型,用于处理这些大量数据。Hadoop的优势在于其可扩展性、经济性和灵活性,使其成为大数据分析的首选工具。
2.7 WebCollector介绍
WebCollector是一款强大的网络爬虫工具,能够帮助用户方便快捷地提取网页上的信息。它支持多线程下载、并发控制、断点续传等功能,可以有效地提高网页爬取的效率和稳定性。使用WebCollector,用户可以轻松地实现自动化数据收集和信息提取,为各种数据分析和挖掘任务提供了便利。
WebCollector的设计十分灵活,用户可以根据自己的需求定制爬虫程序。它支持多种数据格式的解析,包括HTML、XML、JSON等,可以根据网页的特点选择合适的解析方式。此外,WebCollector还提供了丰富的插件接口,用户可以根据需要扩展其功能,实现更加强大的数据处理和分析。
除了提供强大的功能和灵活的设计,WebCollector还具有良好的稳定性和可靠性。它经过长时间的实际应用和不断的优化,已经被广泛应用于各种领域,包括搜索引擎优化、数据挖掘、信息监控等。无论是个人用户还是企业用户,都可以通过WebCollector轻松地实现网络数据的收集和处理,节省时间和精力,提高工作效率。
2.8 B/S结构
B/S结构(Browser/Server,浏览器/服务器结构)是一种网络应用模式,它将软件的功能分为客户端和服务器端两部分。在这种结构中,用户通过浏览器访问服务器端的应用程序,而应用程序的数据处理和逻辑运算则由服务器端完成。
B/S结构的优点是易于维护和升级,因为所有的功能都在服务器端实现,客户端只需安装浏览器即可。B/S结构具有较高的可扩展性和跨平台性,用户无需安装专门的客户端软件,只要有网络连接就可以访问应用程序。在B/S结构中,用户界面是关键,因为它直接影响到用户的使用体验。为了提供良好的用户体验,开发者需要关注界面设计、交互设计和响应速度等方面。安全性也是B/S结构中不可忽视的问题,开发者需要采取一定的安全措施来保护用户数据和系统资源。
测试用例
(1)登录测试
登录功能是用户进入系统的校验窗口,其中需要填写的信息包括用户账号和用户密码,下面将根据此功能设计具体测试用例来验证登录功能的实现与否。具体测试用例见表6-1。
表6-1 登录功能测试用例
| 用例序号 | 用例描述 | 测试步骤 | 期望输出 | 测试结果 |
| Test_01 | 页面展示 | 浏览器输入登录地址 | 进入登录页面 | 成功 |
| Test_02 | 账号非空检验 | 账号为空,点击“登录”按钮 | 提示“用户账号必须输入” | 成功 |
| Test_03 | 账号存在性检验 | 输入不存在的账号 | 提示“输入的账号不存在” | 成功 |
| Test_04 | 密码非空检验 | 输入正确的账号,密码为空 | 提示“用户密码必须输入” | 成功 |
| Test_05 | 密码正确性检验 | 输入正确的账号和不正确的密码 | 提示“输入的密码错误” | 成功 |
| Test_06 | 登录成功检验 | 输入正确的账号和密码 | 登录成功,进入首页 | 成功 |
(2)修改密码测试
更改密码功能需要用户输入原始密码、修改后的密码、修改后的确认密码,方可更换密码。具体测试用例见表6-2。
表6-2 修改密码测试用例
| 用例描述 | 测试步骤 | 期望输出 | 测试结果 | |
| Test_01 | 页面跳转 | 点击“密码修改”按钮 | 进入密码修改页面 | 成功 |
| Test_02 | 原始密码非空检验 | 原始密码为空,点击“提交”按钮 | 提示“原始密码必须输入” | 成功 |
| Test_03 | 原始密码正确性检验 | 输入错误原始密码 | 提示“原始密码输入错误” | 成功 |
| Test_04 | 修改密码非空检验 | 输入正确的原始密码,修改密码为空,点击“提交”按钮 | 提示“修改密码必须输入” | 成功 |
| Test_05 | 确认密码非空检验 | 输入正确的原始密码,修改密码非空,确认密码为空,点击“提交”按钮 | 提示“确认密码必须输入” | 成功 |
| Test_06 | 两次新密码输入一致性检验 | 输入正确的原始密码,修改密码非空,确认密码与修改密码不一致,点击“提交”按钮 | 提示“两次密码输入不一致” | 成功 |
| Test_07 | 修改成功检验 | 输入正确的原始密码,修改密码非空,确认密码与修改密码一致,点击“提交”按钮 | 提示“处理成功” | 成功 |

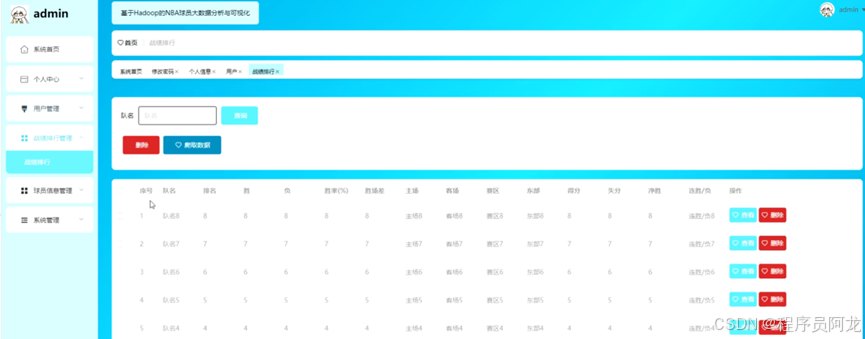
系统实现界面:

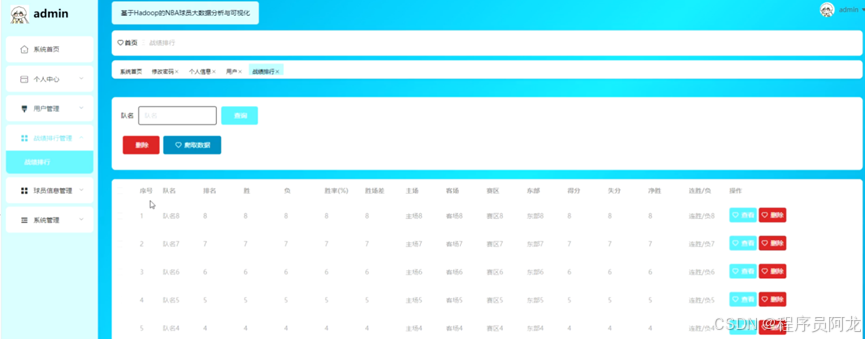
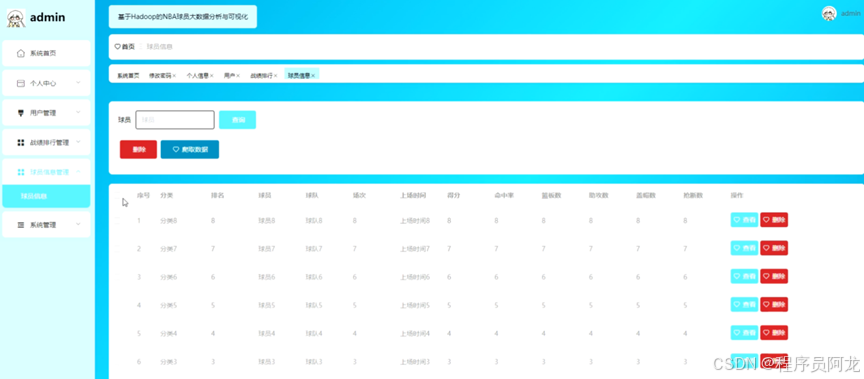


核心代码介绍:
package com.service;
import com.baomidou.mybatisplus.mapper.Wrapper;
import com.baomidou.mybatisplus.service.IService;
import com.utils.PageUtils;
import com.entity.SystemintroEntity;
import java.util.List;
import java.util.Map;
import com.entity.vo.SystemintroVO;
import org.apache.ibatis.annotations.Param;
import com.entity.view.SystemintroView;
/**
* 系统简介
*
* @author
* @email
* @date 2024-02-06 13:55:31
*/
public interface SystemintroService extends IService<SystemintroEntity> {
PageUtils queryPage(Map<String, Object> params);
List<SystemintroVO> selectListVO(Wrapper<SystemintroEntity> wrapper);
SystemintroVO selectVO(@Param("ew") Wrapper<SystemintroEntity> wrapper);
List<SystemintroView> selectListView(Wrapper<SystemintroEntity> wrapper);
SystemintroView selectView(@Param("ew") Wrapper<SystemintroEntity> wrapper);
PageUtils queryPage(Map<String, Object> params,Wrapper<SystemintroEntity> wrapper);
}
爬虫核心代码介绍:
port numpy as np
import pandas as pd
from sqlalchemy import create_engine
from selenium.webdriver import ChromeOptions, ActionChains
from scrapy.http import TextResponse
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait
# 球员信息
class QiuyuanxinxiSpider(scrapy.Spider):
name = 'qiuyuanxinxiSpider'
spiderUrl = 'https://nba.hupu.com/stats/players/pts'
start_urls = spiderUrl.split(";")
protocol = ''
hostname = ''
realtime = False
def __init__(self,realtime=False,*args, **kwargs):
super().__init__(*args, **kwargs)
self.realtime = realtime=='true'
# 列表解析
def parse(self, response):
_url = urlparse(self.spiderUrl)
self.protocol = _url.scheme
self.hostname = _url.netloc
plat = platform.system().lower()
if not self.realtime and (plat == 'linux' or plat == 'windows'):
connect = self.db_connect()
cursor = connect.cursor()
if self.table_exists(cursor, '2p2udt0o_qiuyuanxinxi') == 1:
cursor.close()
connect.close()
self.temp_data()
return
list = response.css('table.players_table tr:not(tr[class])')
for item in list:
fields = QiuyuanxinxiItem()
if '(.*?)' in '''div#test''':
try:
fields["fenlei"] = str('得分'+ re.findall(r'''div#test''', item.extract(), re.DOTALL)[0].strip())
except:
pass
else:
try:
fields["fenlei"] = str('得分'+ self.remove_html(item.css('div#test').extract_first()))
except:
pass
if '(.*?)' in '''td:nth-child(1)::text''':
try:
fields["paiming"] = int( re.findall(r'''td:nth-child(1)::text''', item.extract(), re.DOTALL)[0].strip())
except:
pass
else:
try:
fields["paiming"] = int( self.remove_html(item.css('td:nth-child(1)::text').extract_first()))
except:
pass
if '(.*?)' in '''td:nth-child(2) a::text''':
try:
fields["qiuyuan"] = str( re.findall(r'''td:nth-child(2) a::text''', item.extract(), re.DOTALL)[0].strip())
except:
pass
else:
try:
fields["qiuyuan"] = str( self.remove_html(item.css('td:nth-child(2) a::text').extract_first()))
except:
pass
if '(.*?)' in '''td:nth-child(3) a::text''':
try:
fields["qiudui"] = str( re.findall(r'''td:nth-child(3) a::text''', item.extract(), re.DOTALL)[0].strip())
except:
pass
else:
try:
fields["qiudui"] = str( self.remove_html(item.css('td:nth-child(3) a::text').extract_first()))
except:
pass
if '(.*?)' in '''td:nth-child(11)::text''':
try:
fields["changci"] = int( re.findall(r'''td:nth-child(11)::text''', item.extract(), re.DOTALL)[0].strip())
except:
pass
else:
try:
fields["changci"] = int( self.remove_html(item.css('td:nth-child(11)::text').extract_first()))
except:
pass
if '(.*?)' in '''td:nth-child(12)::text''':
try:
fields["scsj"] = str( re.findall(r'''td:nth-child(12)::text''', item.extract(), re.DOTALL)[0].strip())
except:
pass
else:
try:
fields["scsj"] = str( self.remove_html(item.css('td:nth-child(12)::text').extract_first()))
except:
pass
if '(.*?)' in '''td:nth-child(4)::text''':
try:
fields["defen"] = float( re.findall(r'''td:nth-child(4)::text''', item.extract(), re.DOTALL)[0].strip())
except:
pass
else:
try:
fields["defen"] = float( self.remove_html(item.css('td:nth-child(4)::text').extract_first()))
except:
pass
if '(.*?)' in '''td:nth-child(6)::text''':
try:
fields["mzl"] = float( re.findall(r'''td:nth-child(6)::text''', item.extract(), re.DOTALL)[0].strip().replace('%', ''))
except:
pass
else:
try:
fields["mzl"] = float( self.remove_html(item.css('td:nth-child(6)::text').extract_first()).replace('%', ''))
except:
pass
if '(.*?)' in '''''':
try:
fields["lanbanshu"] = float( re.findall(r'''''', item.extract(), re.DOTALL)[0].strip())
except:
pass
else:
try:
fields["lanbanshu"] = float( self.remove_html(item.css('').extract_first()))
except:
pass
if '(.*?)' in '''''':
try:
fields["zhugongshu"] = float( re.findall(r'''''', item.extract(), re.DOTALL)[0].strip())
except:
pass
else:
try:
fields["zhugongshu"] = float( self.remove_html(item.css('').extract_first()))
except:
pass
if '(.*?)' in '''''':
try:
fields["gaimaoshu"] = float( re.findall(r'''''', item.extract(), re.DOTALL)[0].strip())
except:
pass
else:
try:
fields["gaimaoshu"] = float( self.remove_html(item.css('').extract_first()))
except:
pass
if '(.*?)' in '''''':
try:
fields["qiangduanshu"] = float( re.findall(r'''''', item.extract(), re.DOTALL)[0].strip())
except:
pass
else:
try:
fields["qiangduanshu"] = float( self.remove_html(item.css('').extract_first()))
except:
pass
yield fields
# 数据清洗
def pandas_filter(self):
engine = create_engine('mysql+pymysql://root:123456@localhost/spider2p2udt0o?charset=UTF8MB4')
df = pd.read_sql('select * from qiuyuanxinxi limit 50', con = engine)
# 重复数据过滤
df.duplicated()
df.drop_duplicates()
#空数据过滤
df.isnull()
df.dropna()
# 填充空数据
df.fillna(value = '暂无')
# 异常值过滤
# 滤出 大于800 和 小于 100 的
a = np.random.randint(0, 1000, size = 200)
cond = (a<=800) & (a>=100)
a[cond]
# 过滤正态分布的异常值
b = np.random.randn(100000)
# 3σ过滤异常值,σ即是标准差
cond = np.abs(b) > 3 * 1
b[cond]
# 正态分布数据
df2 = pd.DataFrame(data = np.random.randn(10000,3))
# 3σ过滤异常值,σ即是标准差
cond = (df2 > 3*df2.std()).any(axis = 1)
# 不满⾜条件的⾏索引
index = df2[cond].index
# 根据⾏索引,进⾏数据删除
df2.drop(labels=index,axis = 0)
# 去除多余html标签
def remove_html(self, html):
if html == None:
return ''
pattern = re.compile(r'<[^>]+>', re.S)
return pattern.sub('', html).strip()
# 数据库连接
def db_connect(self):
type = self.settings.get('TYPE', 'mysql')
host = self.settings.get('HOST', 'localhost')
port = int(self.settings.get('PORT', 3306))
user = self.settings.get('USER', 'root')
password = self.settings.get('PASSWORD', '123456')
try:
database = self.databaseName
except:
database = self.settings.get('DATABASE', '')
if type == 'mysql':
connect = pymysql.connect(host=host, port=port, db=database, user=user, passwd=password, charset='utf8')
else:
connect = pymssql.connect(host=host, user=user, password=password, database=database)
return connect
# 断表是否存在
def table_exists(self, cursor, table_name):
cursor.execute("show tables;")
tables = [cursor.fetchall()]
table_list = re.findall('(\'.*?\')',str(tables))
table_list = [re.sub("'",'',each) for each in table_list]
if table_name in table_list:
return 1
else:
return 0
# 数据缓存源
def temp_data(self):
connect = self.db_connect()
cursor = connect.cursor()
sql = '''
insert into `qiuyuanxinxi`(
id
,fenlei
,paiming
,qiuyuan
,qiudui
,changci
,scsj
,defen
,mzl
,lanbanshu
,zhugongshu
,gaimaoshu
,qiangduanshu
)
select
id
,fenlei
,paiming
,qiuyuan
,qiudui
,changci
,scsj
,defen
,mzl
,lanbanshu
,zhugongshu
,gaimaoshu
,qiangduanshu
from `2p2udt0o_qiuyuanxinxi`
where(not exists (select
id
,fenlei
,paiming
,qiuyuan
,qiudui
,changci
,scsj
,defen
,mzl
,lanbanshu
,zhugongshu
,gaimaoshu
,qiangduanshu
from `qiuyuanxinxi` where
`qiuyuanxinxi`.id=`2p2udt0o_qiuyuanxinxi`.id
))
'''
cursor.execute(sql)
connect.commit()
connect.close()

1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!



















 2147
2147

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











