




 本文介绍源自频率主义学派的极大似然估计,这是根据数据采样来估计概率分布参数的经典方法。概率模型训练是参数估计过程,极大似然估计是寻找使数据出现“可能性”最大的参数值。不过,参数化方法的估计准确性依赖假设的概率分布形式。
本文介绍源自频率主义学派的极大似然估计,这是根据数据采样来估计概率分布参数的经典方法。概率模型训练是参数估计过程,极大似然估计是寻找使数据出现“可能性”最大的参数值。不过,参数化方法的估计准确性依赖假设的概率分布形式。
估计类条件概率的一种常用策略是先假定其具有某种确定的概率分布形式,再基于训练样本对概率分布的参数进行估计。具体地,记关于类别c的类条件概率为P(x|c),假设P(x|c)具有确定形式并且被参数向量θc唯一确定,则我们的任务就是利用训练集D估计参数θc。为了明确起见,我们将P(x|c)记为P(x|θc)。
事实上,概率模型的训练过程就是参数估计(parameter estimation)过程。对于参数估计,统计学界的两个学派分别提供了不同的解决方案:频率主义学派认为参数虽然未知,但却是客观存在的固定值,因此,可通过优化似然函数等准则来确定参数值;贝叶斯学派则认为参数是未观察到的随机变量,其本身也可有分布,因此,可假定参数服从一个先验分布,然后基于观测到的数据来计算参数的后验分布。本文介绍源自频率主义学派的极大似然估计,是根据数据采样来估计概率分布参数的经典方法。(亦称极大似然法)
令Dc表示训练集D种第c类样本组成的的集合,假设这些样本是独立同分布的,则参数θc对于数据集Dc的似然是:
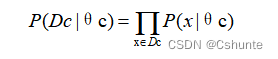
对θc进行极大似然估计,就是去寻找能最大化似然P(Dc|θc)的参数值θ'c。直观上看,极大似然估计是试图在θc所有可能的取值中,找到一个能使数据出现的“可能性”最大的值。
不过上式的连乘操作容易造成下溢,通常使用对数似然(log-likelihood):
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









