






1.前置条件:需要提前安装 mysql 8 , elasticsearch-7.16.3
2. flink-1.13.6 及其依赖包 下载链接:分别需要下载
flink-1.13.6 tar包 https://archive.apache.org/dist/flink/flink-1.13.6/flink-1.13.6-bin-scala_2.11.tgz
flink-sql依赖包:Central Repository: com/alibaba/ververica/flink-sql-connector-mysql-cdc/1.4.0 (apache.org)
flink-elasticsearch依赖包:
Central Repository: org/apache/flink/flink-sql-connector-elasticsearch7_2.11/1.13.5
如果连接丢失,或者无法下载,可以私信我,免费提供。
这两个依赖包下载下来之后需要放置到flink-1.13.6的lib目录下,如图:
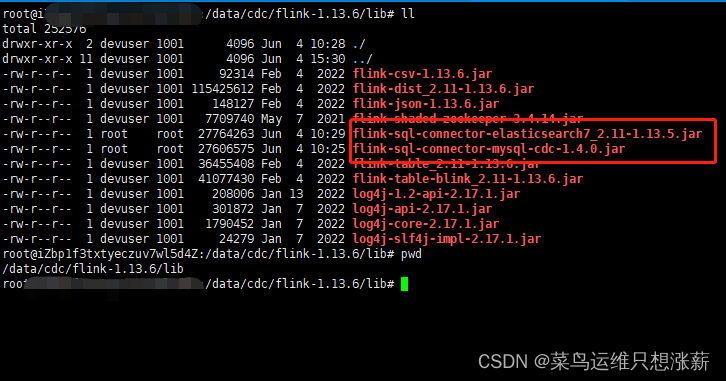
2.1下面启动flink
cd /data/flink-1.13.6
vim conf/flink-conf.yaml
#找到以下几行,进行内存的修改
jobmanager.memory.process.size: 4096m #44行
taskmanager.memory.process.size: 5120m #51行
taskmanager.memory.flink.size: 4096m #56行 防止内存过小导致服务无法启动。
2.2.启动flink及配置相关表结构、关联表、es索引等。
cd /data/flink-1.13.6/bin
./start-cluster.sh
#可通过IP+8081端口的方式访问,可视化面板
./sql-client.sh
#进入到flink-sql命令行界面,在这里可以创建任务
SET 'table.local-time-zone' = 'Asia/Shanghai';
#设置时区
set execution.checkpointing.interval = 3s;
#每3秒做一次 checkpoint,用于测试,生产配置建议5到10分钟
#mysql数据库原始表的sql
CREATE TABLE `表名` (
`id` int NOT NULL AUTO_INCREMENT,
`name` varchar(255) DEFAULT NULL,
`description` varchar(255) DEFAULT NULL,
`create_time` datetime DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=13 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
#flink 创建source数据库关联表
CREATE TABLE mysql (
id INT NOT NULL,
name STRING,
description STRING, create_time timestamp,
PRIMARY KEY(id) NOT ENFORCED
) WITH (
'connector' = 'mysql-cdc',
'hostname' = '192.168.*.*', #mysql的地址IP
'port' = '3306', #mysql的端口
'username' = 'root', #mysql的用户名
'password' = '****', #mysql的密码
'database-name' = '***', #数据库的名称
'table-name' = '***' #表名
);
#flink创建数据库关联表elasticsearch
CREATE TABLE es (
id INT,
name STRING, description STRING,
createTime timestamp,
PRIMARY KEY (id) NOT ENFORCED
) WITH (
'connector' = 'elasticsearch-7',
'hosts' = 'http://192.168.*.*:9200', #es的地址加端口
'index' = 'index', #索引名
'username' = '***', #es账号
'password' = '***' #es密码(如果没设置账号密码删除这两项即可)
);
还需在es上建立索引,以下为我的索引为例。
test #索引名 PUT 请求
{
"settings": {
"number_of_shards": 12, #12个分片
"number_of_replicas": 0, #副本数为0
"analysis": {
"analyzer": {
"ik": {
"tokenizer": "ik_max_word" #ik分词器,没有的话删掉即可,注意格式
}
}
}
},
"mappings": {
"properties": {
"createTime": { #字段名
"type": "date", #类型
"format": "yyyy-MM-dd HH:mm:ss"
},
"description": { #字段名
"type": "text" #类型
},
"id": { #字段名
"type": "integer" #类型
},
"name": { #字段名
"type": "keyword" #类型
}
}
}
}
}
建完以上的这些 数据库和表、flink mysql关联表、flink es关联表、es索引 后,就可以起同步的任务
3.3开始启动同步。
SELECT
t.id AS id,
t.`name` AS name,
t.description AS description,
t.create_time AS createTime
FROM
mysql t;
#在同步之前可以执行这个语句看是否能从库里查出数据。(Q退出)
#查完之后就可以执行同步的语句
insert into es
SELECT
t.id AS id,
t.`name` AS name,
t.description AS description,
t.create_time AS createTime
FROM
mysql t;
#es=刚刚建的es关联表的名字,这个可自行定义。
#mysql=刚刚建的mysql关联表的名字,这个可自行定义。
#同时可以在flink可视化的页面上查看数据同步状态。
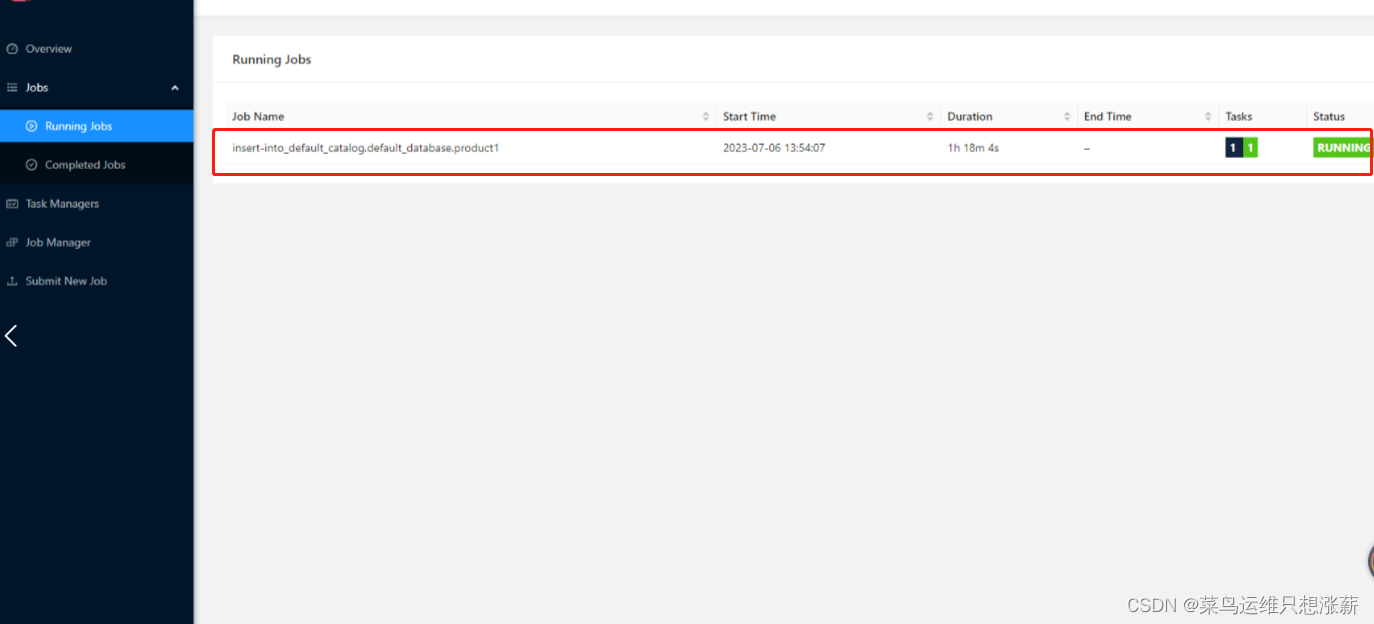
如图所示,绿色就代表正在运行,此时可以在mysql的表里加一条数据,然后去ES查看,就会发现有数据了。
关闭同步,只需要点击对应任务进去,右上角有个Job点击选取yes即可取消。
flink mysql es时间字段对应关系

3.4 持久化同步,防止同步服务挂掉之后,重头开始同步的操作。
#可以将模版写在一个sql文件里,方便每次调用,如果服务异常 他会记录下最近一次的时间点,恢复时很方便
#下面是我的整个文件的语句
set pipeline.name = test;
set execution.checkpointing.interval = 300s;
set state.checkpoints.dir = file:///tmp/checkpoint-dir;
set state.checkpoints.custom-name = flink-job-checkpoint-%d-%s;
set execution.checkpointing.externalized-checkpoint-retention=RETAIN_ON_CANCELLATION;
CREATE TABLE mysql (
id INT NOT NULL,
name STRING,
description STRING, create_time timestamp,
PRIMARY KEY(id) NOT ENFORCED
) WITH (
'connector' = 'mysql-cdc',
'hostname' = '192.168.*.*',
'port' = '3306',
'username' = 'root',
'password' = '***',
'database-name' = '***',
'table-name' = '***'
);
CREATE TABLE es (
id INT,
name STRING, description STRING,
createTime timestamp,
PRIMARY KEY (id) NOT ENFORCED
) WITH (
'connector' = 'elasticsearch-7',
'hosts' = 'http://192.168.*.*:9200',
'index' = '***',
'username' = '***',
'password' = '***'
'sink.buffer-flush.max-rows' = '1000',
'sink.buffer-flush.interval' = '10s',
'scan.startup.mode' = 'initial',
'server-time-zone' = 'Asia/Shanghai'
);
BEGIN STATEMENT SET;
insert into es
SELECT
t.id AS id,
t.`name` AS name,
t.description AS description,
t.create_time AS createTime
FROM
mysql t;
#保存并退出
#flink sql -f ./template.sql
#即可执行sql文件内定义好的同步上面3.4这个步骤,只是理论可以,但是还没有实际操作过,等我这边实际操作过后,在来更新后续文档
文章参考连接:flink-cdc同步mysql数据到elasticsearch - 技术人的菜园子 - 博客园 (cnblogs.com)

















 1659
1659

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









