




论文地址:https://arxiv.org/pdf/2103.00020
模型框架:通过n个图像-文本对输入,然后各自获得特征,n个特征去学习正确的匹配。每一组有n个正样本(正确的匹配),n方-1个负样本(错误匹配)。
模型只学习了正确匹配关系,并没有分类头以及分类操作。
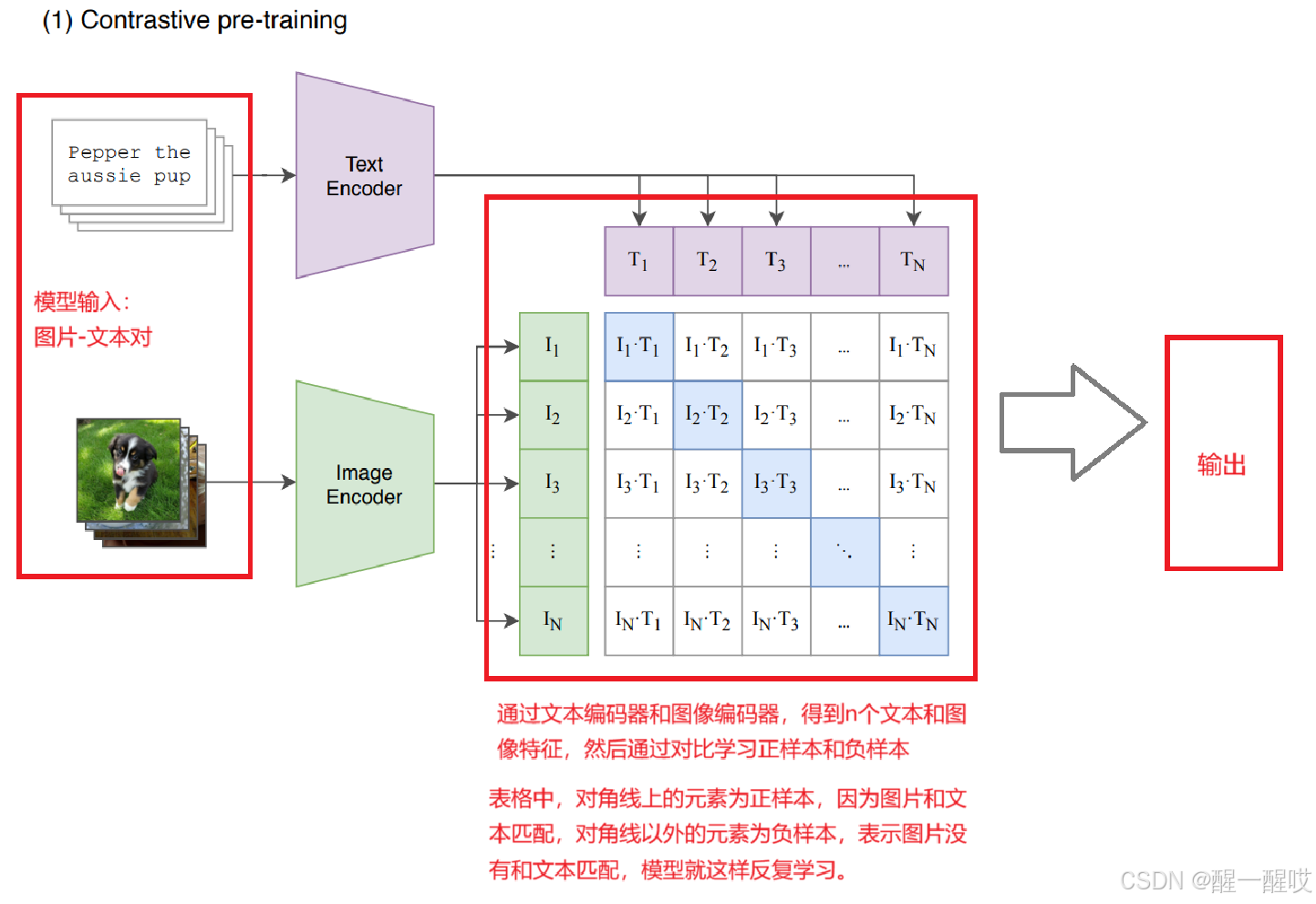
论文指出是模型自监督的学习方式,是指没有标注具体的物体,但是给定了一张图片含有物体的描述,监督信号来自于文本处理。
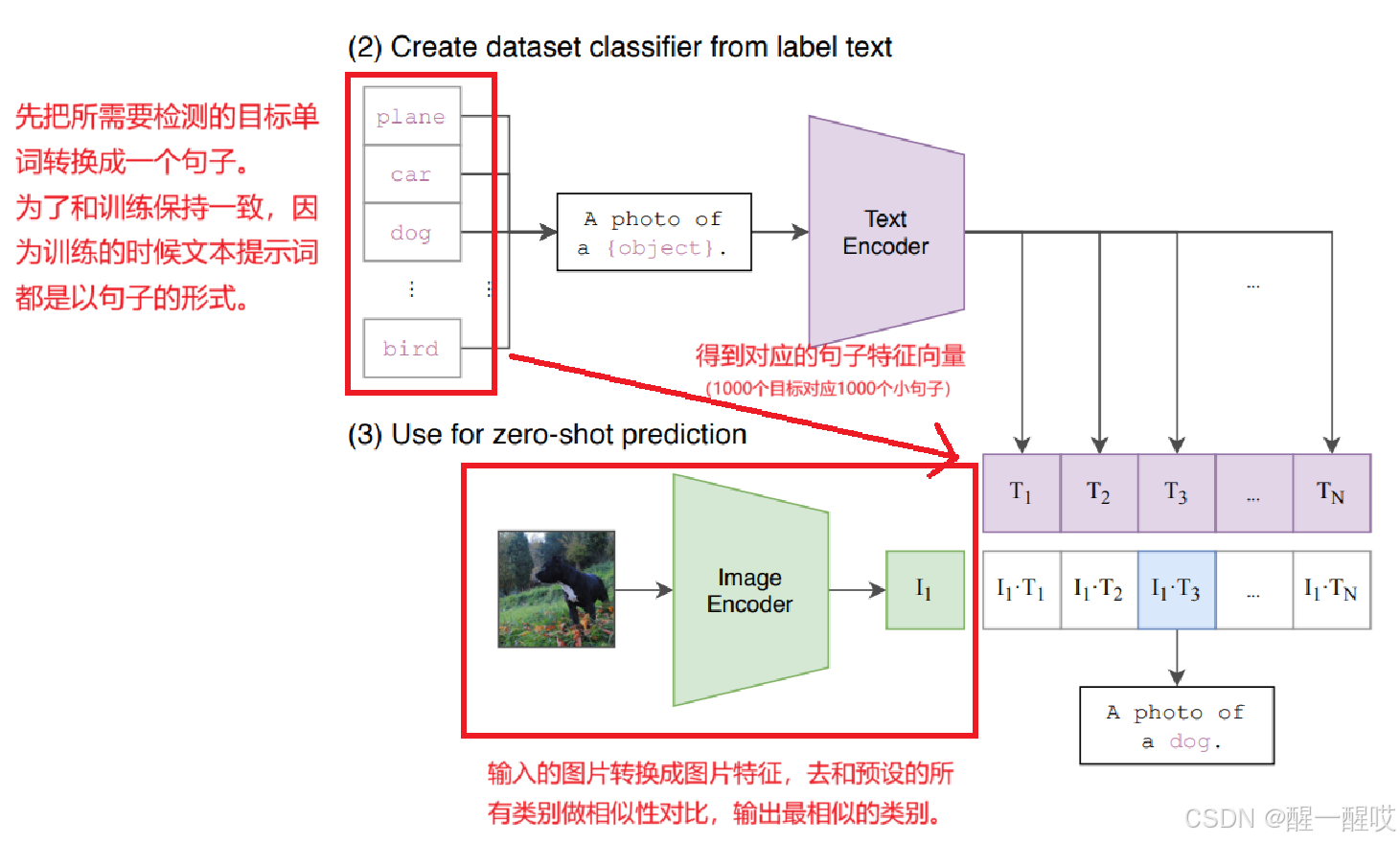
CLIP零样本推理:
在推理时,给定任意一张图片,如果在文本对中模型见过提示词,就可以推理出来,理论上提示词可以无限扩大,去检测的图片任意性也越强。
由于预训练模型见过的语义非常多,即使没有具体的提示词,也可以通过其他简单的语义组合,图像中的物体检测出来。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









