




复习一为概念性的知识,复习二为算法类的知识
第一章
Ⅰ. 数据挖掘的概念和对象。
数据挖掘的定义:
①广义技术角度的定义
数据挖掘(Data Mining)就是从大量的、不完全的、有噪声的、模糊的、随机的实际应用数据中,提取隐含在其中的、人们事先不知道的、但又是潜在有用的信息或知识的非平凡过程。
②狭义技术角度的定义
也有人把数据挖掘视为知识发现过程中的一个基本步骤。例如Fayyad过程模型主要包含以下七个阶段,知识发现过程由这些步骤的迭代序列组成:
a.知识表示
b.数据清理
c.数据集成
d.数据选择
e.数据变换
f.数据挖掘
g.模式评估
③商业角度的定义
数据挖掘是一种新的商业信息处理技术,其主要特点是对商业数据库中的大量业务数据进行抽取、转换、分析和其他模型化处理,从中提取辅助商业决策的关键性数据。
数据挖掘
从商业的角度
可以描述为:按企业既定业务目标,对大量的企业数据进行探索和分析,揭示隐藏的、未知的或验证已知的规律性,并进一步将其模型化的先进有效的方法。
数据挖掘对象:
1. 关系数据库
2. 数据仓库
3. 文本
4. 多媒体数据
5.Web数据
6. 复杂类型的数据
Ⅱ.数据挖掘常用技术和应用场景
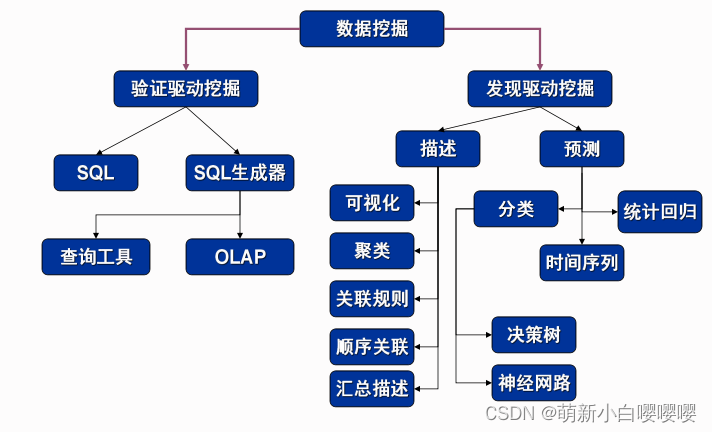
数据挖掘中常用的十三种技术:
统计技术,关联规则,基于历史的分析,遗传算法,聚集检测,连接分析,决策树,神经网络,粗糙集,模糊集,回归分析,差别分析,概念描述等
数据挖掘的应用场景

数据挖掘应用最集中的领域包括金融、医疗、教育、零售、电商、电信和交通等,而且每个领域都有特定的应用问题和应用背景。
以软件工程数据挖掘为例:
软件工程数据(软件开发过程中积累的各种数据):可行性分析和需求分析文档、设计文档、使用说明、软件代码和注释、软件版本及其演化数据、测试用例和测试结果、软件开发者之间的通信、用户反馈等
应用领域的案例:
电商领域:借助于交易记录挖出破坏规则的“害群之马”
交通领域:为打车平台的乘客订制弹性价格
医疗领域:为乔布斯寻找最佳的医疗方案
第二章 数据预处理
Ⅰ数据预处理的形式
-
数据清理补充缺失数据、平滑噪声数据、识别或删除离群点,解决不一致
-
数据集成集成多个数据库、数据立方或文件
-
数据变换规范化、数据离散化、概念分层产生
-
数据归约简化数据、但产生同样或相似的结果
Ⅱ数据清洗
现实世界的数据一般是脏的、不完整的和不一致的。而数据清洗试图填充空缺的值、识别孤立点、消除噪声,并纠正数据中的不一致性。因此,从如下几个方面介绍:
1.空缺值;
2.噪声数据;
3.不一致数据。
1.空缺值
数据并不总是完整的数据库表中,很多条记录的对应字段可能没有相应值,比如销售表中的顾客收入
如何处理空缺值
1)忽略该元组:
2)人工填写空缺值
3)使用属性的平均值填充空缺值
4)使用一个全局变量填充空缺值
5)使用与给定元组属同一类的所有样本的平均值
6)使用最可能的值填充空缺值(最常用)
7)使用填充算法来处理缺失数据
2.噪声数据
噪声(noise):是一个测量变量中的随机错误或偏差,包括错误的值和偏离期望的孤立点值。
引起噪声数据的原因:
•
数据收集工具的问题
•
数据输入错误
•
数据传输错误
•
技术限制
•
命名规则的不一致
如何处理噪声数据
1)分箱 (binning):
分箱的步骤
:
首先排序数据,并将它们分到等深(等宽)的箱中,然后可以按箱的平均值、按箱中值或者按箱的边界等进行平滑。
按箱的平均值平滑:箱中每一个值被箱中的平均值替换
按箱的中值平滑:箱中的每一个值被箱中的中值替换
按箱的边界平滑:箱中的最大和最小值被视为箱边界,箱中的每一个值被最近的边界值替换
① 等深分箱 (binning):
按记录数进行分箱,每箱具有相同的记录数,每箱的记录数称为箱的权重,也称箱子的深度。
示例:
已知一组价格数据:15,21,24,21,25,4,8,34,28 现用等深(深度为3)分箱方法对其进行平滑,以对数据中的噪声进行处理。
解:排序后的数据:4,8,15,21,21,24,25,28,34
划分为等高度的Bins :
| Bin1: | 4,8,15 |
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 2169
2169

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









