



当我们需要获取网站上的一些数据或文件时,可以使用爬虫来实现自动化的数据抓取。爬虫是一种通过程序自动访问网站、解析网页内容、提取有用信息的技术。在这个过程中,我们需要使用一些工具和技巧来进行网站的爬取和数据的提取。
我们今天爬取的是4K壁纸_4K手机壁纸_4K高清壁纸大全_电脑壁纸_4K,5K,6K,7K,8K壁纸图片素材_彼岸图网因为这个网站壁纸好看,因为需要钱,不想花钱,就能爬取网站
1.导入相应的库
import requests
import re
import os2获取网页内容
url = "https://pic.netbian.com/"
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.90 Safari/537.36"
}
response = requests.get(url=url,headers=headers)
response.encoding = response.apparent_encoding
3.使用正则表达式从网页内容中匹配出图片的链接和名字
parr = re.compile('src="(/u.*?)".alt="(.*?)"') # 匹配图片链接和图片名字
image = re.findall(parr,response.text)
4.判断本地是否存在名为“彼岸图网图片获取”的文件夹,若不存在则创建;
path = "彼岸图网图片获取"
if not os.path.isdir(path): # 判断是否存在该文件夹,若不存在则创建
os.mkdir(path) # 创建5.遍历获取到的图片链接和名字,依次下载图片,并保存到本地文件夹中;
# 对列表进行遍历
for i in image:
link = i[0] # 获取链接
name = i[1] # 获取名字
"""
在文件夹下创建一个空jpg文件,打开方式以 'wb' 二进制读写方式
@param res:图片请求的结果6.打印出每张图片的名字和下载状态
with open(path+"/{}.jpg".format(name),"wb") as img:
res = requests.get("https://pic.netbian.com"+link)
img.write(res.content) # 将图片请求的结果内容写到jpg文件中
img.close() # 关闭操作
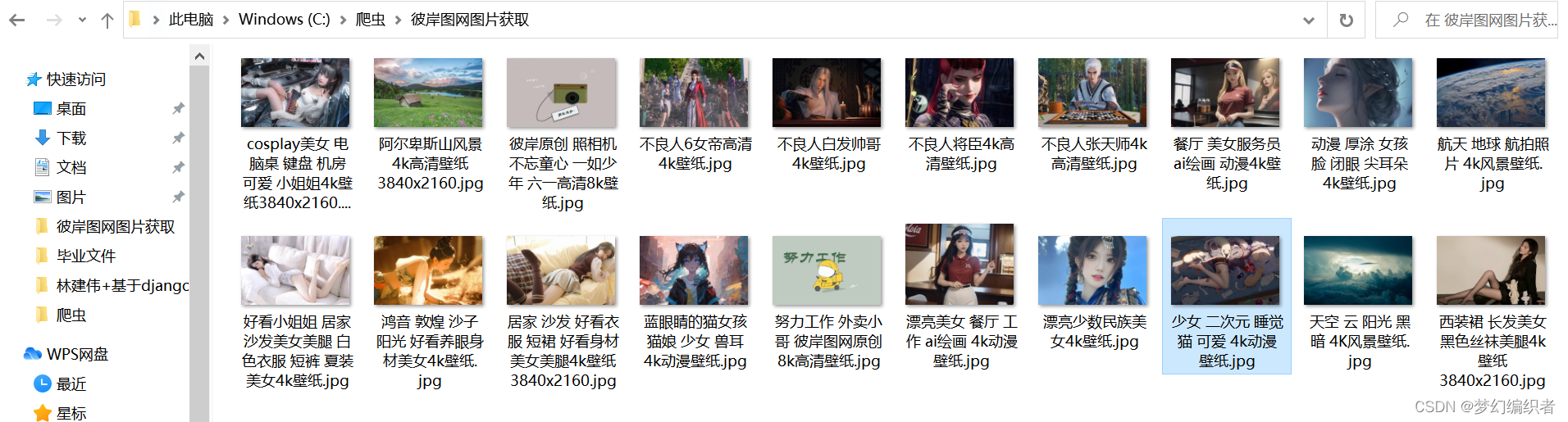
print(name+".jpg 获取成功······")最后他会按照每一张照片进行打印,最后查看文件夹


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











