



 本文介绍了一种用于存储英文单词的单链表方法,通过共享相同后缀来节省空间。详细阐述了如何查找两个链表的公共后缀,包括优化前后的算法实现及其时间复杂度分析。
本文介绍了一种用于存储英文单词的单链表方法,通过共享相同后缀来节省空间。详细阐述了如何查找两个链表的公共后缀,包括优化前后的算法实现及其时间复杂度分析。
6-10 共享后缀的链表 (25 分)
有一种存储英文单词的方法,是把单词的所有字母串在一个单链表上。为了节省一点空间,如果有两个单词有同样的后缀,就让它们共享这个后缀。下图给出了单词“loading”和“being”的存储形式。本题要求你找出两个链表的公共后缀。
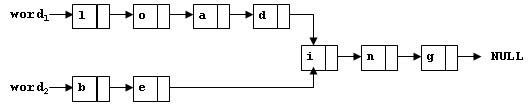
函数接口定义:
PtrToNode Suffix( List L1, List L2 );
其中List结构定义如下:
typedef struct Node *PtrToNode;
struct Node {
ElementType Data; /* 存储结点数据 */
PtrToNode Next; /* 指向下一个结点的指针 */
};
typedef PtrToNode List; /* 定义单链表类型 */
L1和L2都是给定的带头结点的单链表。函数Suffix应返回L1和L2的公共后缀的起点位置。
裁判测试程序样例:
#include <stdio.h>
#include <stdlib.h>
typedef char ElementType;
typedef struct Node *PtrToNode;
struct Node {
ElementType Data; /* 存储结点数据 */
PtrToNode Next; /* 指向下一个结点的指针 */
};
typedef PtrToNode List; /* 定义单链表类型 */
void ReadInput( List L1, List L2 ); /* 裁判实现,细节不表 */
void PrintSublist( PtrToNode StartP ); /* 裁判实现,细节不表 */
PtrToNode Suffix( List L1, List L2 );
int main()
{
List L1, L2;
PtrToNode P;
L1 = (List)malloc(sizeof(struct Node));
L2 = (List)malloc(sizeof(struct Node));
L1->Next = L2->Next = NULL;
ReadInput( L1, L2 );
P = Suffix( L1, L2 );
PrintSublist( P );
return 0;
}
/* 你的代码将被嵌在这里 */
输入样例:
如图存储的链表
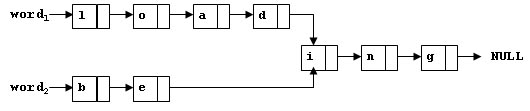
输出样例:
ing
我们只要找到相同的节点(地址相同==->next相同即可)
超时部分错误答案:
/*这是忽略超时版*/
//l2指针在L2中不断循环,未找到相同节点则i向l1后指一位;
PtrToNode Suffix(List L1, List L2) {
List i = (List)malloc(sizeof(struct Node));//创建一个类型为List名叫S的指针,并为他分配空间
List k1 = i, k2 = i;//创建一个类型为List名叫k1,k2的指针,并为他分配空间
i = L1;
int k = 0;//第一次循环从L1的头指针开始
for (; i && k2;) {
k++;
i = i->Next;
if (k == 1) {
i = L1;//保证i从L1的头指针开始循环
}
k2 = L2;
for (; k2;) {
if (k2->Next == i->Next) {
return i->Next;
}
k2 = k2->Next;
}
k2 = L2->Next;
}
}
此方法超时原因因为其时间复杂度为o(N*N);
当字符串长度长时非常慢;
优化正确答案:
PtrToNode Suffix( List L1, List L2 ){
List P1, P2;
int len1 = 0, len2 = 0;
P1 = L1 -> Next;
P2 = L2 -> Next;
for(;P1;){
len1++;
P1 = P1 -> Next;
}
for(;P2;){
len2++;
P2 = P2 -> Next;
}
P1 = L1 -> Next;
P2 = L2 -> Next;
while(len1 > len2){
len1--;
P1 = P1 -> Next;
}
while(len2 > len1){
len2--;
P2 = P2 -> Next;
}
for(;P1 != P2;){
P1 = P1 -> Next;
P2 = P2 -> Next;
}
return P1;
}
原理:
将多余出的字符串对齐,保证一一寻找时可以找到相同的地址,
loading
King
对齐后从d和K开始依次寻找
放弃了o(n*n)的冗余算法,使时间复杂度大大下降


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









