




什么是爬虫?
网络爬虫也叫网络蜘蛛,如果把互联网比喻成一个蜘蛛网,那么爬虫就是在网上爬来爬去的蜘蛛,爬虫程序通过请求url地址,根据响应的内容进行解析采集数据。
简单的说:就是用代码模拟人的行为,去各各网站溜达、点点按钮、查查数据。或者把看到的数据拿下来。通过有效的爬虫手段,批量采集数据。

反爬与反反爬
反爬:有时企业不想自己的数据被别人拿到。这时就会设置反爬的手段,来不让爬虫获取数据。
反反爬:破解掉反爬手段,再获取其数据。所有的手段都有可能破解。
第一个爬虫程序
#从urlopen中获取库urllib.request
from urllib.request import urlopen
#输入请求的网址
url = 'http://www.baidu.com'
#发送请求
resp = urlopen(url)
print(resp.read().decode()[:100])
#将爬取的信息打印
#read()将网址可读
#decode()将内容转化为字符串
#[:100]只读前100个字符
urllib响应对象的使用
from urllib.request import urlopen
url = 'http://www.baidu.com'
resp = urlopen(url)
print(resp.read()[:100])
print(resp.getcode()) # 获取响应码,200表示成功
print(resp.geturl()) # 获取访问的url
print(resp.info()) # 获取响应头信息
Request对象的使用
可以使用Request库,通过里面的headers修改自己的请求头信息,用来伪装自己。
from urllib.request import urlopen
#调用库Request
from urllib.request import Request
url = 'http://httpbin.org/get'
#将字典传入变量headers
headers = {'新头':'666' }
#封装url并修改请求头信息
req = Request(url,headers=headers)
#发送请求
resp = urlopen(req)
print(resp.read().decode())
urllib发送get请求
大部分被传输到浏览器的html,images,js,css, … 都是通过GET方法发出请求的。它是获取数据的主要方法
Get请求的参数都是在Url中体现的,如果有中文,需要转码,这时我们可使用l以下两种方法
- urllib.parse. quote() 转换一个值
from urllib.request import urlopen,Request
#引入用与中文转码的库quote
from urllib.parse import quote
#将用于转码的中文设置为一个变量args
args = input('请输入想要搜索的内容:')
#将中文args放入网址中,开头加上f
url = f'https://www.baidu.com/s?wd={quote(args)}'
#修改头
headers = {'User-Agent':'Mozilla'}
#使用Request将url与headers封装
req = Request(url,headers=headers)
#使用urlopen发送
resp = urlopen(req)
print(resp.read().decode()[:1500])
- urllib.parse.urlencode() 转换键值对
from urllib.request import urlopen,Request
#引入用与中文转码的库urlencode
from urllib.parse import urlencode
#将用于转码的中文设置为一个变量args
args = input('请输入想要搜索的内容:')
#将中文args放入字典parms中
parms = {'wd':args}
#将值为中文的字典parms放入网址中
url = f'https://www.baidu.com/s?{urlencode(parms)}'
headers = {'User-Agent':'Mozilla'}
req = Request(url,headers=headers)
resp = urlopen(req)
print(resp.read().decode()[:1500])
喜马拉雅实战
我们将通过这次实战学会两点:
1.如何分析网页
2.使用方法,一次获取多页信息
不同的网站有不同的网址规律,打开喜马拉雅网,我们对网址开始分析
点进音乐界面,然后进入不同分类的音乐,观察网址
https://www.ximalaya.com/category/a1_b733978/
https://www.ximalaya.com/category/a2_b733978/
我们发现标红位置代表着音乐的分类
在a1类型中的音乐点击下一页我们发现
https://www.ximalaya.com/category/a1_b733978/
https://www.ximalaya.com/category/a1_b733978/p2
https://www.ximalaya.com/category/a1_b733978/p3
标红位置代表不同页数
此时我们大概完成了对网页的分析,开始写爬虫:
利用方法,设计变量p{num}替代网址中的页数部分,将num放入循环,实现一次获取多页数据
from urllib.request import Request,urlopen
def spider_Music(page):
for num in range(1,page+1):
if num == 1:
url = 'https://www.ximalaya.com/category/a2_b733978/'
else:
url = f'https://www.ximalaya.com/category/a2_b733978/p{num}'
#更改请求头与封装发送
headers = {'User-Agent':'Mozilla'}
req = Request(url,headers=headers)
resp = urlopen(req)
print(resp.getcode()) #获取响应码,200表示成功
print(resp.geturl()) #获取响应网址
print(resp.read().decode()[:100])
a = input('请输入需要查询的页数:')
spider_Music(int(a))
post请求封装多个数据
使用data可以封装多个数据,但要注意将字典data先转换为字符串,
再用encode()转换为bytes类型,因为字典不能直接被传送
from urllib.request import Request,urlopen
from urllib.parse import urlencode
url = 'https://www.kuaidaili.com/login/'
#data内放入多个数据
data = {
'username': '15517100927',
'password':'rr211314',
'login_type': '1',
}
#将数据data转换为字符串,然后通过encode转换为bytes类型
tru_data = urlencode(data).encode()
headers = {'User-Agent':'Mozilla'}
#将数据data封装
req = Request(url,data=tru_data,headers=headers)
resp = urlopen(req)
print(resp.read().decode())
动态页面数据的获取
有时在访问了请求后,并不能获取想要的数据。
很大的原因之一就是,当前的页面是动态的。
目前网络的页面分为2大类:
-
静态页面
- 特征:访问有UI页面URL,可以直接获取数据
-
动态页面(AJAX)
- 特征:访问有UI页面URL,不能获取数据。需要抓取新的请求获取数据
解决方案:
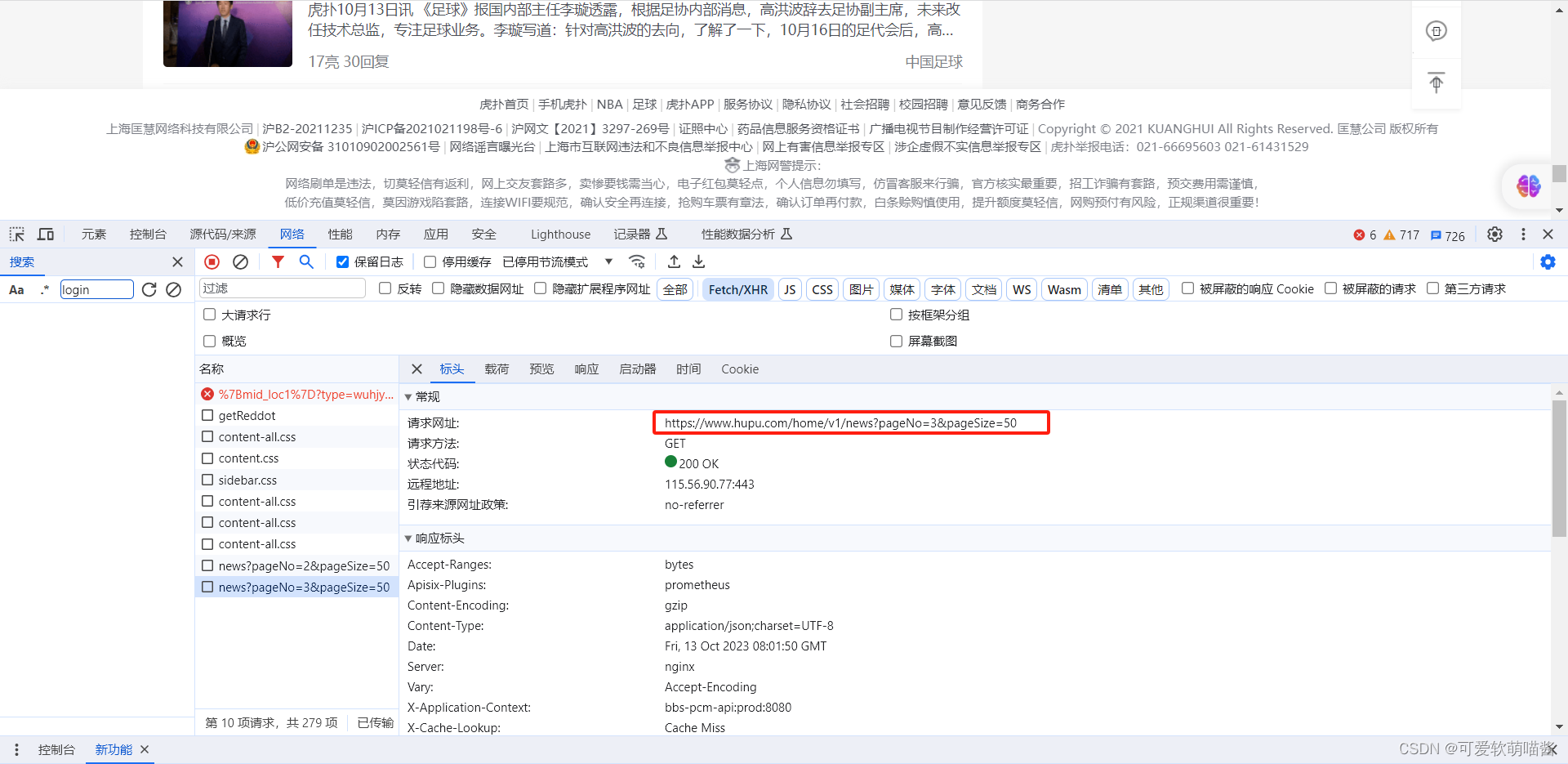
在动态页面中,选择Fetch/XHR,然后滑动滚动条,即可发现有新的动态数据产生
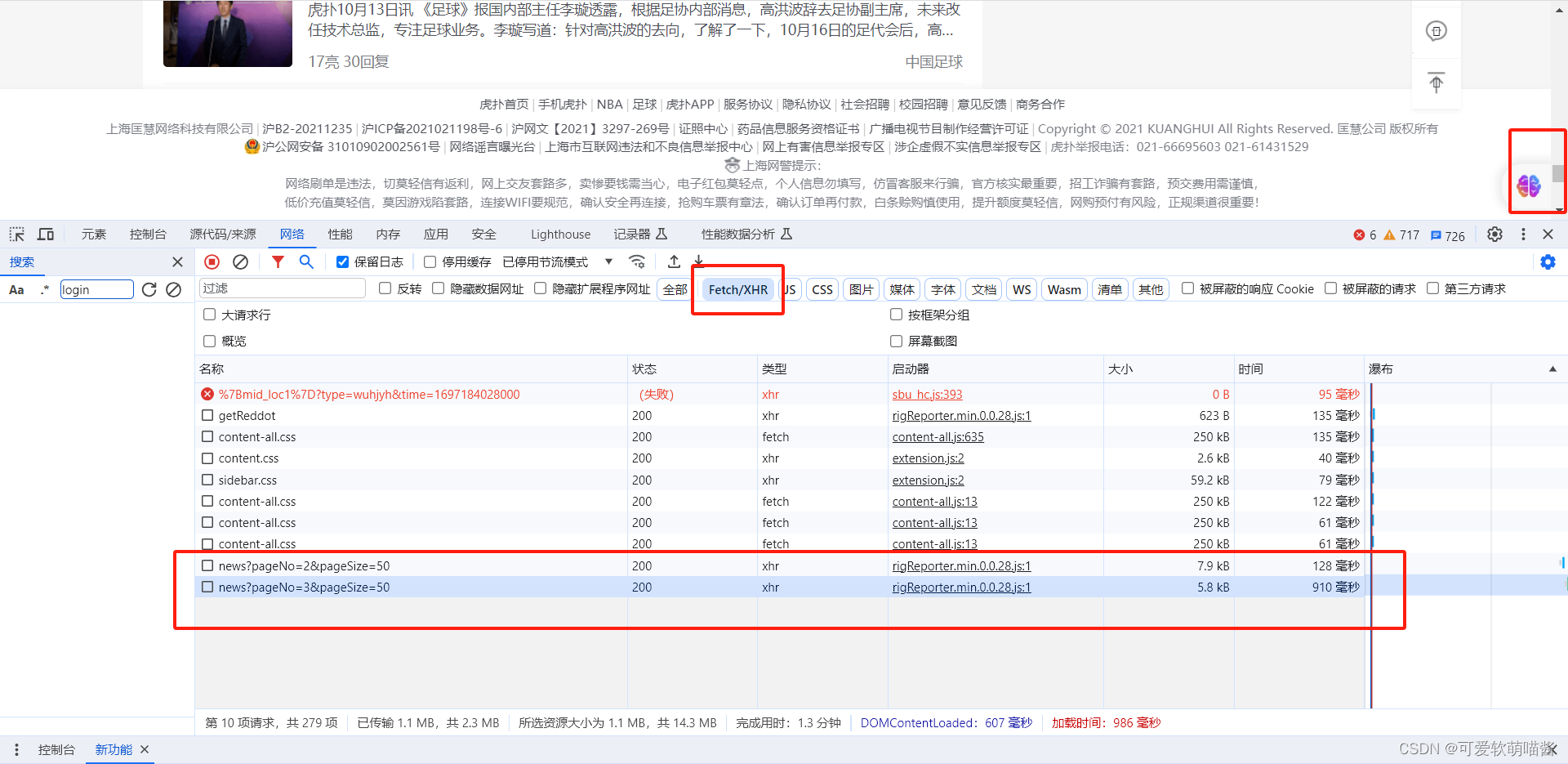
再次点击动态数据,即可获取网址等信息。
请求 SSL证书验证
如果SSL证书验证不通过,或者操作系统不信任服务器的安全证书,那我们将无法访问网站,这时我们可以通过绕过验证的方式解决问题
#引入库ssl
import ssl
# 忽略SSL安全认证
context = ssl._create_unverified_context()
# 添加到context参数里
response = urlopen(request, context = context)
伪装爬虫-请求头
有些网站不会同意你使用程序直接进行访问,如果识别有问题,那么站点根本不会响应
所以为了访问,我们可以使用库fake-useragent,完全模拟浏览器的工作
首先进行fake-useragent的安装
第一步 创建虚拟环境
在终端创建虚拟环境,保持原先环境的干净
终端输入 mkvirtualenv 环境名 创建虚拟环境
点击右下角,进行环境的切换,由于是刚创建好的环境,需要刷新一下,新环境才会显示

第二步 安装fake-useragent
终端输入:pip install fake-useragent
进行安装
安装好后,我们使用fake_useragent里面的UserAgent每次访问所使用的头都是随机的
from urllib.request import urlopen,Request
#引用库UserAgent
from fake_useragent import UserAgent
#将伪装头放入,chrome代表浏览器的名字,也可以使用其他浏览器名字
header = {'User-Agent':UserAgent().chrome}
url = 'http://httpbin.org/get'
req = Request(url,headers=header)
resp = urlopen(req)
print(resp.read().decode())
urllib的底层原理
在前面,我们都是使用的是urlopen,他的底层是opener,urlopen也就是默认的opener。
它是一个特殊的opener,可以理解成opener的一个特殊实例,传入的参数仅仅是url,data,timeout。
如果我们需要用到Cookie,只用这个opener是不能达到目的的
所以我们需要创建一个底层的opener,向opener中加入各种各样的功能
最后,将HTTPHandler(参数)加入opener中,即可实现各种不同功能的opener,从而获取特定数据
不同的参数,可以使HTTPHandler拥有不同的功能
也可以传入多个参数,如HTTPHandler(参数1,参数2,参数3···),这样就可以实现一个HTTPHandler拥有多种功能
实例:
from urllib.request import Request
#引入底层opener,与实现opener各种功能的功能块HTTPHandler
from urllib.request import build_opener,HTTPHandler
from fake_useragent import UserAgent
url = 'http://httpbin.org/get'
headers = {'User-Agent':UserAgent().chrome}
req = Request(url,headers = headers)
#向功能块HTTPHandler中加入参数从而确定功能
handler = HTTPHandler(debuglevel= 1)
#将拥有功能的handler加入底层opener中,从而使opener拥有功能
opener = build_opener(handler)
#发送请求
resp = opener.open(req)
print(resp.read().decode())
伪装爬虫—代理ip的使用
使用爬虫时,如果被网站发现你的ip地址,那么网站可以永久禁止你的ip地址进入
所以我们可以使用多个虚拟ip地址,让别的服务器或电脑代替自己的服务器去获取数据
这样的话其中一个虚拟ip地址被封禁,我们可以使用其他虚拟地址继续爬取数据
方法:使用上一节所学习的内容,利用含有可修改ip地址的ProxyHandler,向其中以字典形式加入
虚拟ip地址,ProxyHandler传入opener中,即可。
实例:
from urllib.request import urlopen,Request
from fake_useragent import UserAgent
#引入底层opener,与拥有修改ip地址的功能块ProxyHandler
from urllib.request import build_opener,ProxyHandler
url = 'http://httpbin.org/get'
#向功能块以字典形式传入虚拟地址
Handler = ProxyHandler({'http':'180.120.209.192:8888'})
#将带有虚拟地址的功能块封装入底层opener
opener = build_opener(Handler)
headers = {'User-Agent':UserAgent().chrome}
req = Request(url,headers=headers)
resp = opener.open(req)
print(resp.read().decode())
cookie的使用
想获取网络部分信息或APP的信息数据时,需要提前做一些操作:
比如需要登录,或者提前访问过某些页面才可以获取到。
其实底层就是在网页里面的请求头增加了Cookie信息。
所以如果我们往请求头加入cookie信息,即可绕过这些操作,直接获取数据
注意:如果是动态页面,则需要寻找你所需要数据的url地址
获取cookie方法:
登录进入页面后,右键点击检查,选择网络,ctrl+r刷新,然后双击文件格式为document的文件,找到请求标头下的cookie
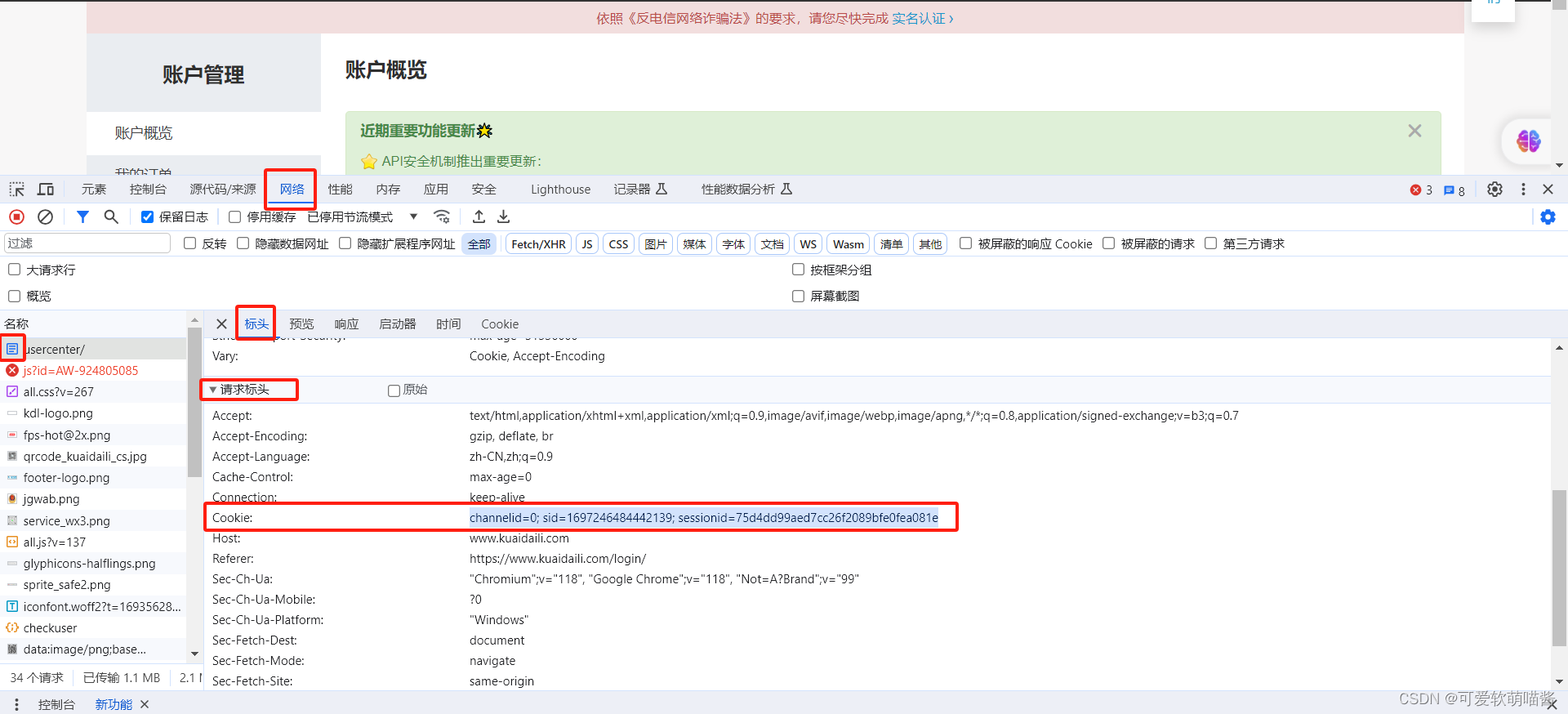
将cookie数据复制到爬虫里的请求头,再将拥有cookie数据的请求头封装到url里发送即可
由于文件内容较多,控制台无法展示全部数据,所以我们将爬取的数据保存到html文件中
实例:
from urllib.request import urlopen,Request
from fake_useragent import UserAgent
url = 'https://www.kuaidaili.com/usercenter/'
#向请求头headers里以字典形式装入Cookie
headers = {
'User-Agent':UserAgent().chrome,
'Cookie':'channelid=0; sid=1697666664442139; sessionid=75d4dd66aed7cc26f2086bfe0fea061e'
}
req = Request(url,headers=headers)
resp = urlopen(req)
#将被爬取的数据保存到文件中
with open('tmp.html','wb') as f: #文件f名为tmp,格式为html,wb表示数据的格式为bytes类型
f.write(resp.read()) #向文件f内写入爬取的数据
运行代码,获得文件:
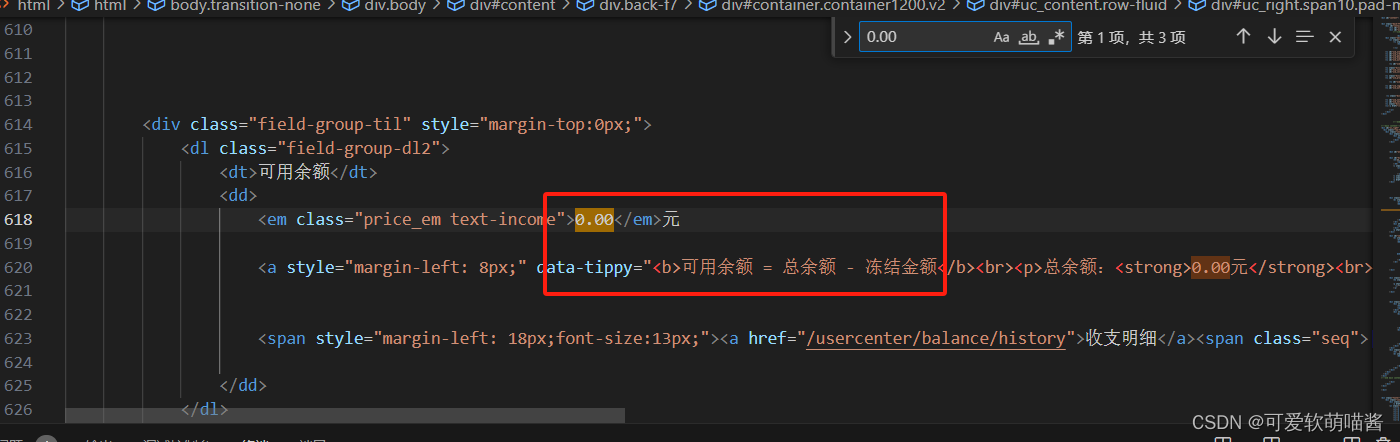
打开查询我们的金额:
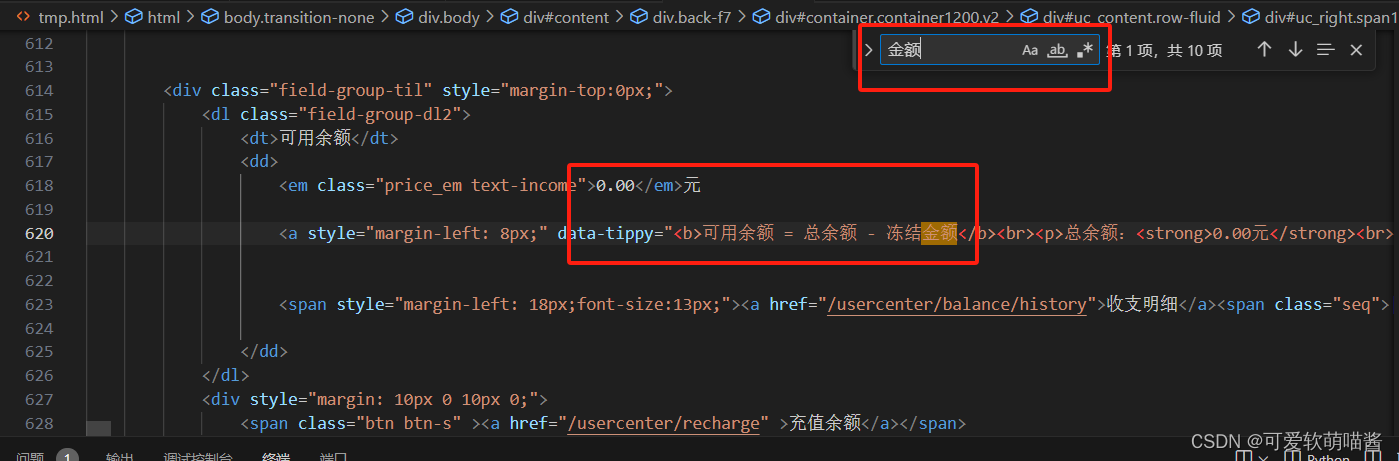
此时我们不用登录,也可以看到我们账户里的金额了
登陆后保持cookie
手动复制cookie太过繁琐,我们可以通过代码登录的方式解决
传统的urlopen在发送请求后会释放数据,
所以如果想要获取数据我们需要HTTPCookieProcessor来扩展opener的功能
首先我们需要获取:
1.登录所需要url:进入登录页面,右键检查,选择网络,随便输入账号密码,点击登录,获取url
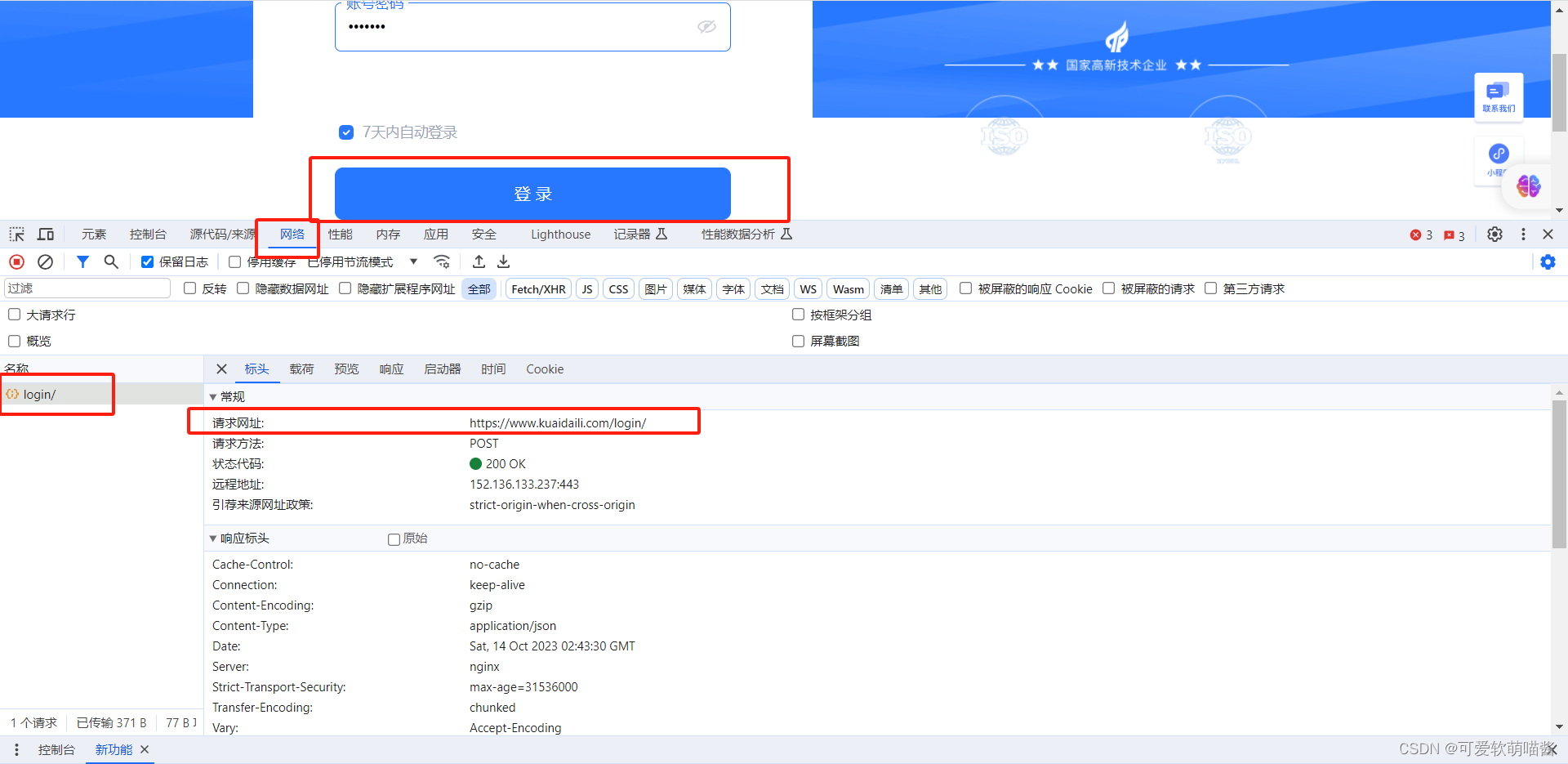
2.封装的数据所需要的内容与格式:点击标头旁的载荷,获取我们想要的数据:
注意:载荷里的数据有next:/的话也要获取下来
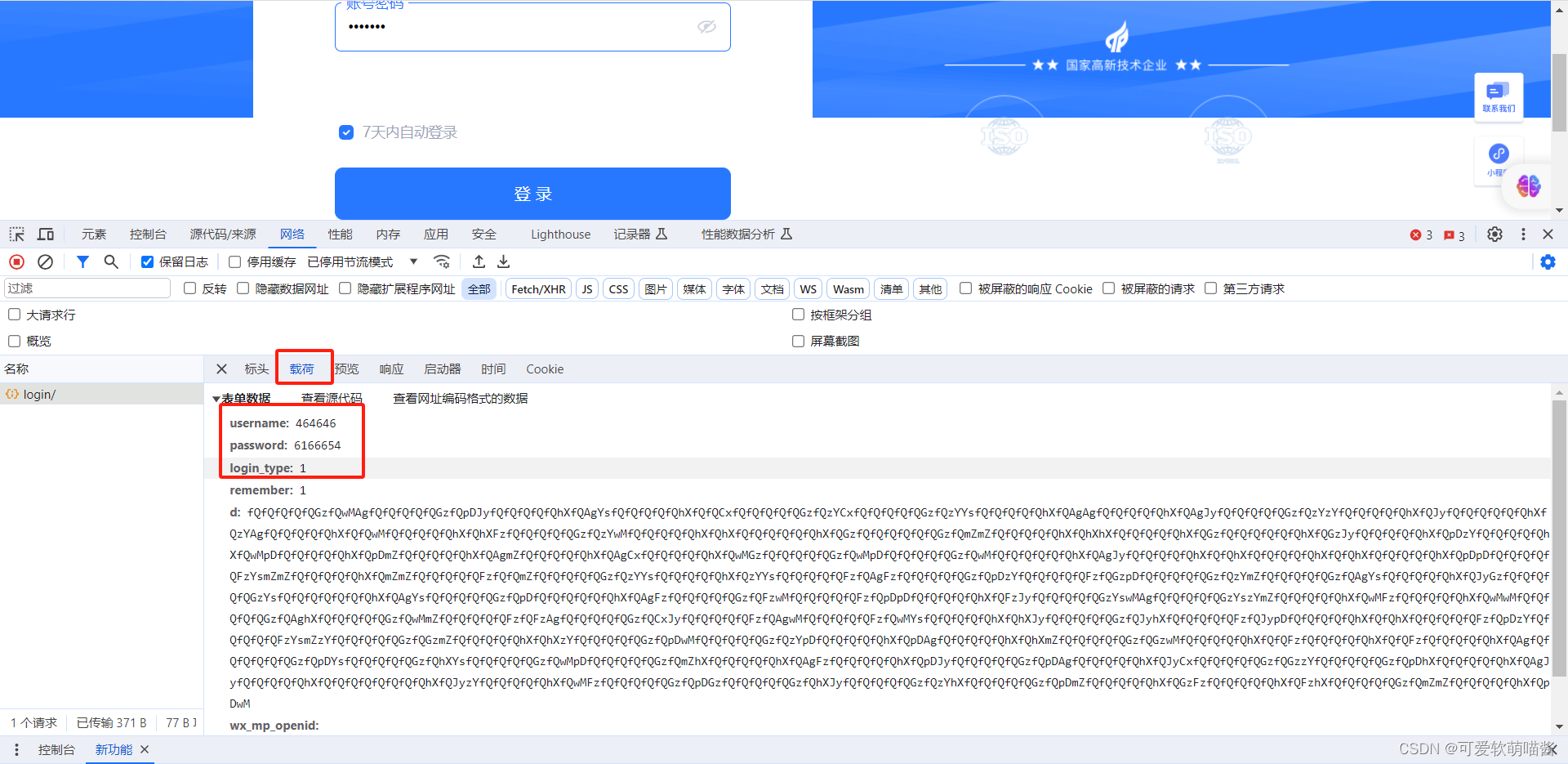
获取这些信息后就可以使用爬虫爬取数据了
这次我们用代码实现登陆操作,并爬取登录操作与登录成功后的两部分数据
所以代码分为登陆操作与登陆后
实例:
from urllib.request import Request
from fake_useragent import UserAgent
#引入具有保存cookie作用的HTTPCookieProcessor
from urllib.request import build_opener,HTTPCookieProcessor
#引入具有中文转码作用的库
from urllib.parse import urlencode
#————————————————————————————登陆操作——————————————————————————————
#输入登录网址
login_url = 'https://www.kuaidaili.com/login/'
headers = {'User-Agent':UserAgent().chrome}
#向data里传入账号与密码
data = {
'username': '1666666',
'password':'rr211314',
'login_type': '1',
}
#向opener赋予保存cookie的功能
handler = HTTPCookieProcessor()
opener = build_opener(handler)
#字典不能直接发送,需要通过encode()转为bytes类型
login_req = Request(login_url,headers=headers,data = urlencode(data).encode())
login_resp = opener.open(login_req)
#————————————————————————————登陆后——————————————————————————————
#输入登陆后的网址,从而爬取登录成功后的数据
index_url = 'https://www.kuaidaili.com/usercenter/'
index_req = Request(index_url,headers=headers)
#此opener也具有保存cookie的功能
index_resp = opener.open(index_req)
#保存文件
with open('html','wb') as f:
f.write(index_resp.read())
然后我们可以在生成的文件中查看到登录前的账号信息
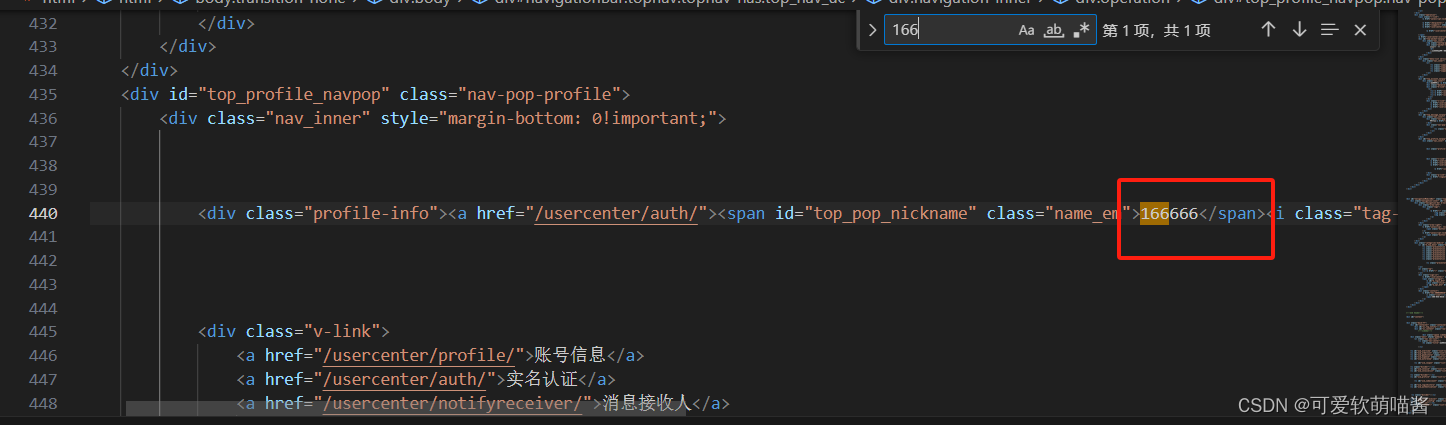
与登陆成功后的信息,比如账户金额
Cookie的保存与读取
我们可以将登录信息保存为一个可读取的cookie文件
这种文件并不是上一节课所保存的登录数据,而是具有登录功能的可读取文件
这样可以使用多个程序或设备,同时读取文件进行登录操作
这种登陆方式是通过读取文件直接进行登录的,不需要再使用繁杂的登陆操作
登陆后进行数据的爬取
分别创建生成cookie文件的与读取cookie文件的两个方法:
生成文件方法:
1.利用上节课具有保存功能的HTTPCookieProcessor(),向其中传入MozillaCookieJar()
使其从保存登录数据,变成保存具有登录功能的文件,
MozillaCookieJar()会保存具有登录功能的数据
2.将具有保存登录功能的MozillaCookieJar()传入handle,再将handle传入底层opener,
使opener具有保存cookie登陆操作数据的功能
3.使用cookie_jar.save,生成文件
读取文件方法:
1创建一个具有读取功能的MozillaCookieJar(),然后使用MozillaCookieJar().load进行读取
2.将已读取文件信息的MozillaCookieJar()传入HTTPCookieProcessor(),再传入handle中
3.创建一个用来读取cookie文件的opener,将handle传入进去,使其拥有读取功能,完成登录操作
实例:
from urllib.request import Request
from fake_useragent import UserAgent
from urllib.parse import urlencode
#引入具有保存cookie作用的HTTPCookieProcessor
from urllib.request import build_opener,HTTPCookieProcessor
#引入具有生成可保存或读取,用于登录cookie文件的MozillaCookieJar
from http.cookiejar import MozillaCookieJar
#创建保存可读取cookie的文件的方法
def save_cookie():
login_url = 'https://www.kuaidaili.com/login/'
headers = {'User-Agent':UserAgent().chrome}
data = {
'username': '15517100927',
'password':'rr211314',
'login_type': '1',
'next':'/'
}
#创建一个准备用来保存cookie文件的对象
cookie_jar = MozillaCookieJar()
#将此功能赋予handler,从而使其从生成保存登录数据的文件变成保存具有登录功能的文件
handler = HTTPCookieProcessor(cookie_jar)
#创建用于保存cookie登录功能文件的opener
opener = build_opener(handler)
login_req = Request(login_url,headers=headers,data = urlencode(data).encode())
login_resp = opener.open(login_req)
#生成文件为cookie.txt
cookie_jar.save('cookie.txt',ignore_discard=True,ignore_expires=True)
#创建读取cookie的文件的方法
def use_cookie():
index_url = 'https://www.kuaidaili.com/usercenter/'
headers = {'User-Agent':UserAgent().chrome}
index_req = Request(index_url,headers=headers)
#创建一个准备用来读取cookie文件的对象
cookie_jar = MozillaCookieJar()
#让对象cookie_jar读取cookie文件
cookie_jar.load('cookie.txt',ignore_discard=True,ignore_expires=True)
#将已读取cookie文件的对象传入handle中
handler = HTTPCookieProcessor(cookie_jar)
#创建一个新的拥有读取cookie文件的opener
opener = build_opener(handler)
index_resp = opener.open(index_req)
with open('html','wb') as f:
f.write(index_resp.read())
if __name__ == '__main__':
#save_cookie()
use_cookie()






















 到【灌水乐园】发言
到【灌水乐园】发言







