



引言
随着工业4.0时代的到来,设备故障诊断已经从传统的被动响应转向主动预测和智能 决策。RAPTOR(Recursive Abstractive Processing for Tree-Organized Retrieval)作为一种新兴的检索增强生成(RAG)技术,为工业设备故障诊断提供了 全新的技术路径。本文将深入解析基于RAPTOR技术的工业设备故障诊断系统的实现细 节,从核心技术原理到工程落地实践,全面展示这一创新解决方案。
本项目运行界面如下:
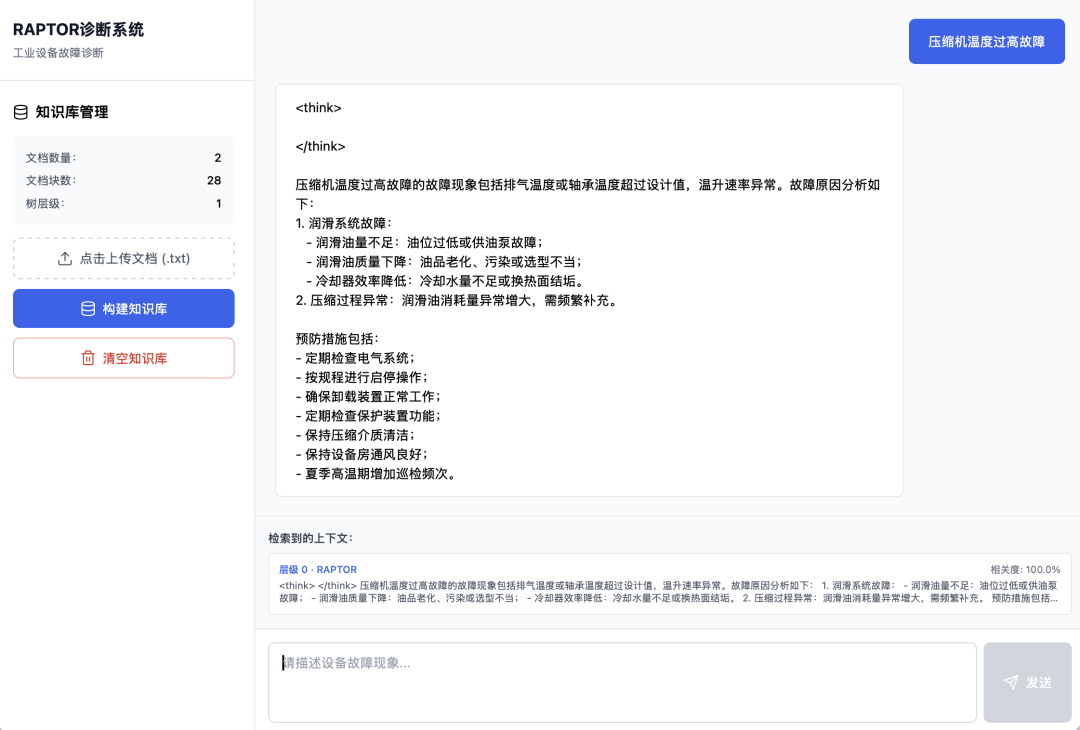
1. RAPTOR技术原理深度剖析
1.1 核心技术思想
RAPTOR是一种基于树形结构的递归检索系统,其核心思想是通过层次化的方式组织知识,实现多粒度的信息检索和摘要生成。
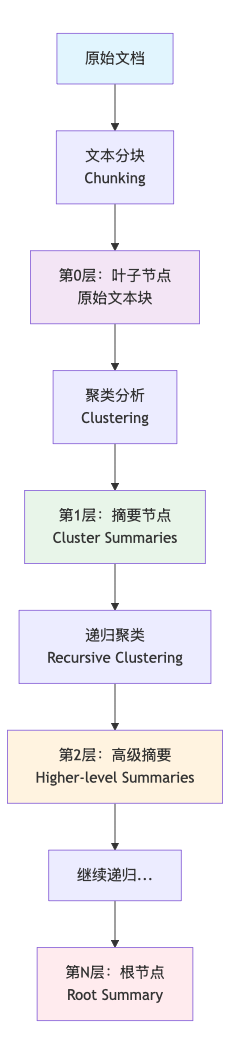
1.2 工作流程解析
RAPTOR的工作流程可以分为四个关键阶段:
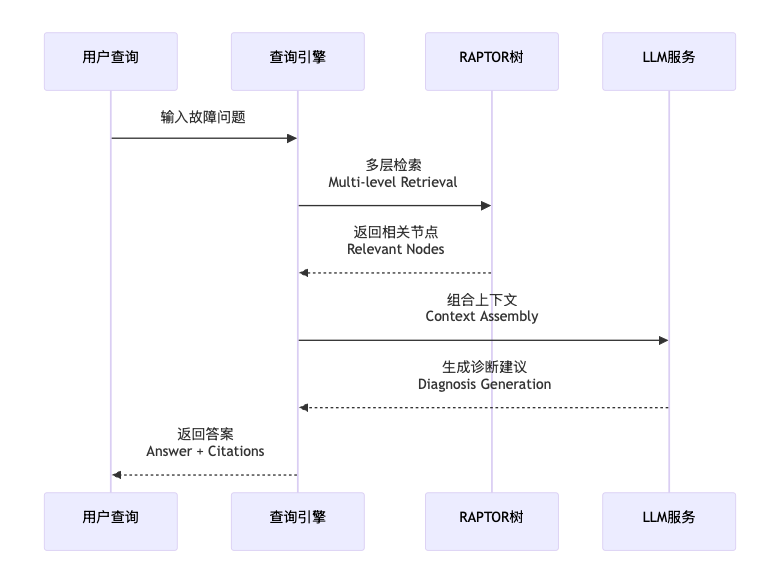
1.3 关键技术创新点
1. 递归摘要生成
- 通过层层摘要,将长文档压缩为不同粒度的表示
- 每一层都比下一层更抽象,覆盖更大范围的信息
2. 树形检索机制
- 从所有层级同时检索,平衡细粒度和粗粒度信息
- 动态选择最相关的节点组合
3. 自适应分块策略
- 不是简单的固定长度分块
- 结合语义相似性和上下文连续性
2. RAPTOR官方实现分析
2.1 架构设计
官方RAPTOR(https://github.com/parthsarthi03/raptor/tree/master) 实现采用模块化设计,主要包含以下核心组件:
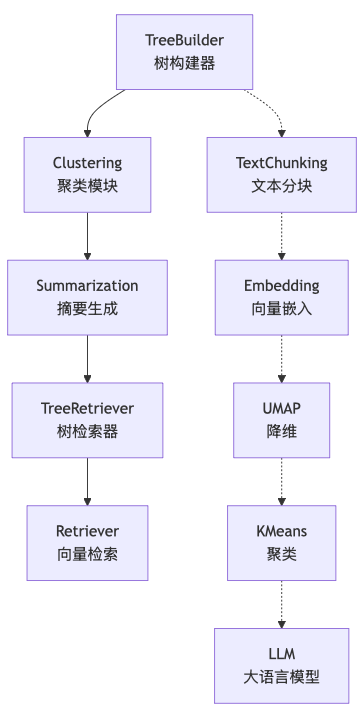
2.2 关键技术实现
文本分块策略(utils.py)
def split_text(text, tokenizer, max_tokens, overlap=0): # 基于标点符号和换行的智能分块 delimiters = [".", "!", "?", "\n"] sentences = re.split(regex_pattern, text) # 计算token数并动态分组 n_tokens = [len(tokenizer.encode(" " + sentence)) for sentence in sentences] # 构建分块,确保不超过max_tokens chunks = [] # ... 省略具体实现
树构建过程(tree_builder.py)
def build_tree(self, text, use_multithreading=True): # 1. 文本分块 chunks = split_text(text, self.tokenizer, self.max_tokens) # 2. 创建叶子节点 leaf_nodes = self.create_leaf_nodes(chunks) # 3. 递归聚类和摘要 for level in range(1, self.tree_levels): # UMAP降维 embeddings = get_embeddings(current_nodes, embedding_model) reduced_embeddings = umap(embeddings) # KMeans聚类 clusters = kmeans(reduced_embeddings, self.cluster_size) # 生成摘要 summaries = [] for cluster in clusters: summary = llm_summarize(cluster) summaries.append(summary) # 创建上层节点 current_nodes = create_nodes(summaries, level)
2.3 检索算法
RAPTOR的检索算法结合了向量相似性和树结构特征:
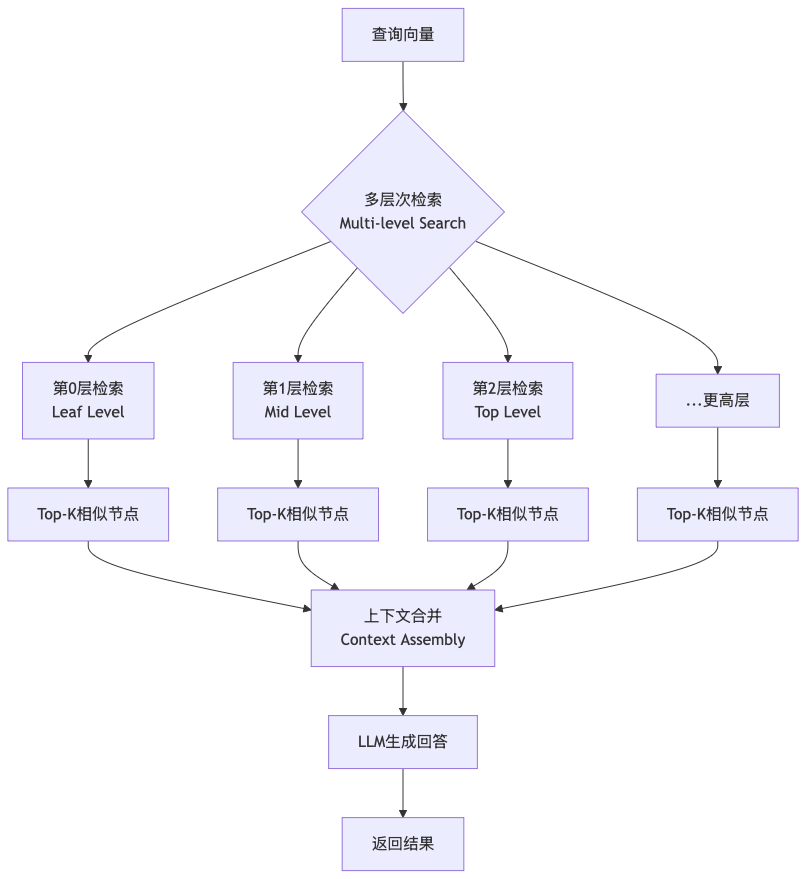
3. 本项目对官方Raptor的扩展
工业数据往往包含敏感信息——设备参数、生产工艺、故障模式等,这些数据的泄露可能导致重大商业损失。本项目特此对RAPTOR官方实现进行了扩展,特别增加了本地化部署能力,通过Ollama等工具实现模型的本地运行,确保"数据不出厂"。(源码包中,Raptor包下的代码是官方代码和本项目对其支持大模型能力的扩展)
3.1 多LLM支持架构设计
为了提高系统的灵活性和可扩展性,项目设计了统一的LLM服务抽象层:
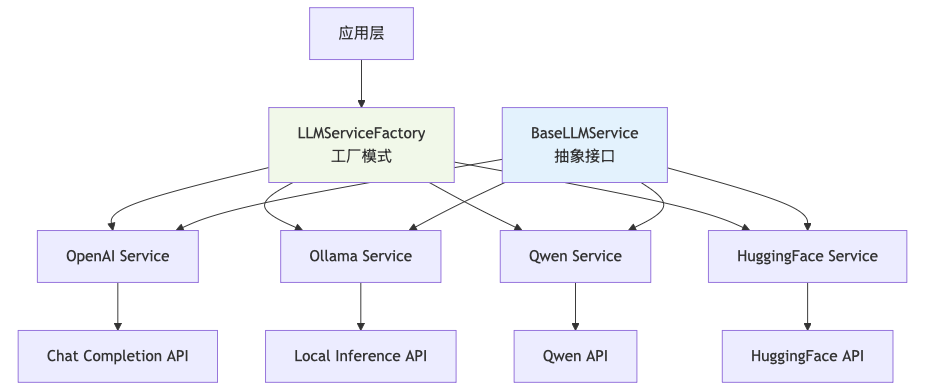
3.2 Ollama集成实现
核心服务类(llm_service.py)
class OllamaService(BaseLLMService): """Ollama本地LLM服务实现""" def __init__(self, base_url=None, model=None): self.base_url = base_url or settings.OLLAMA_BASE_URL self.model = model or settings.OLLAMA_MODEL asyncdef chat(self, messages, **kwargs): """通过Ollama API进行对话""" asyncwith httpx.AsyncClient() as client: response = await client.post( f"{self.base_url}/api/chat", json={ "model": self.model, "messages": messages, "stream": False }, timeout=60.0 ) return response.json()["message"]["content"]
配置管理(config.py)
# 多LLM提供商配置 DEFAULT_LLM_PROVIDER: str = "qwen" # 支持:qwen, huggingface, openai, ollama # Ollama配置 OLLAMA_BASE_URL: str = "http://localhost:11434" OLLAMA_MODEL: str = "qwen3:8b"
3.3 RAPTOR服务封装
RAPTOR服务类(raptor_service.py)
class RaptorService: """RAPTOR服务封装,支持多LLM""" def __init__(self, llm_service=None): self.llm_service = llm_service self.raptor_instance = None asyncdef build_tree(self, documents, document_names=None): """构建RAPTOR树""" # 初始化RAPTOR实例 config = RetrievalAugmentationConfig( embedding_model=OllamaEmbeddingModel(...), tb_summarization_model=OllamaSummarizationModel(...), qa_model=OllamaQAModel(...) ) self.raptor_instance = RetrievalAugmentation(config=config) # 合并文档并构建树 combined_text = "\n\n".join([...]) self.raptor_instance.add_documents(combined_text) self.raptor_instance.save(save_path) asyncdef query(self, query_text, top_k=5): """查询并生成回答""" answer = self.raptor_instance.answer_question( question=query_text ) return [{"content": answer, "score": 1.0}]
3.4 自定义嵌入模型
项目实现了Ollama嵌入模型支持:
class OllamaEmbeddingModel: """Ollama嵌入模型实现""" asyncdef embed(self, text): asyncwith httpx.AsyncClient() as client: response = await client.post( f"{self.base_url}/api/embeddings", json={ "model": self.model, "prompt": text }, timeout=30.0 ) return response.json()["embedding"]
4. 项目整体架构实现
4.1 后端架构设计
后端采用FastAPI框架,实现了清晰的层次化架构:
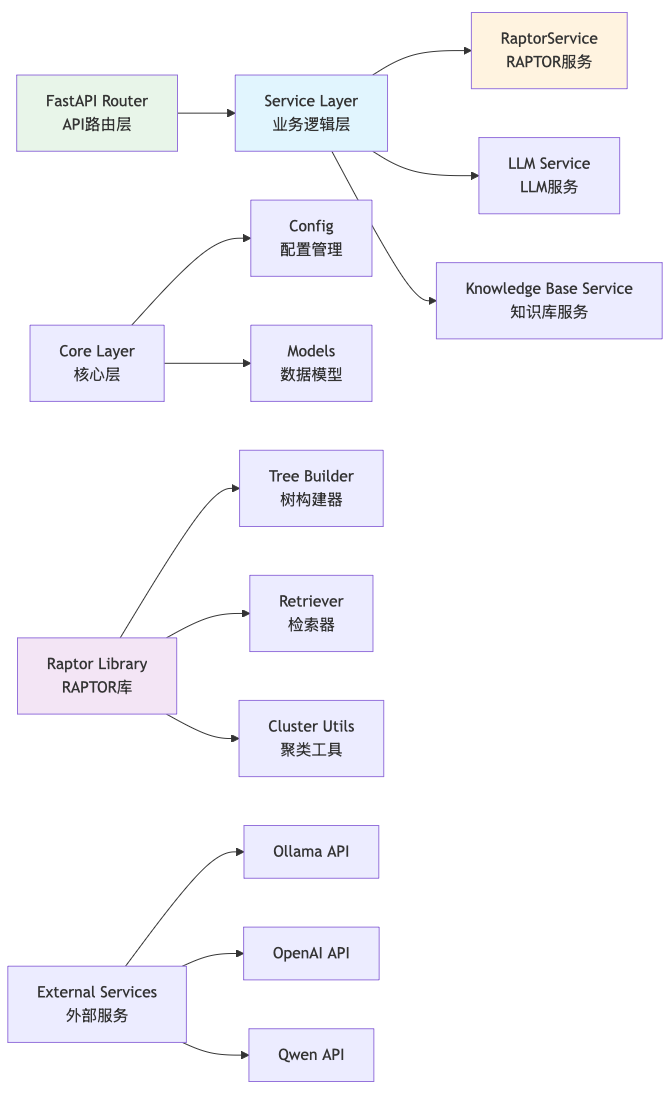
4.2 API设计
项目实现了完整的RESTful API:
# 主要API端点 @router.post("/api/chat")asyncdef chat_question(request: ChatRequest): """智能问答""" @router.post("/api/upload")asyncdef upload_document(file: UploadFile): """文档上传""" @router.post("/api/knowledge-base/build")asyncdef build_knowledge_base(): """构建知识库""" @router.get("/api/knowledge-base/tree")asyncdef get_tree_structure(): """获取树结构"""
4.3 前端架构实现
前端采用React + TypeScript + Tailwind CSS技术栈:
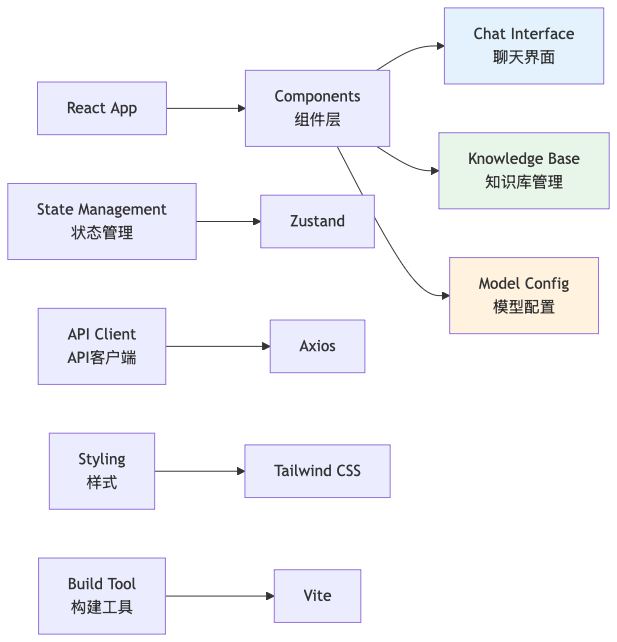
4.4 关键前端组件
聊天界面组件(ChatInterface.tsx)
const ChatInterface: React.FC = () => {const [messages, setMessages] = useState<ChatMessage[]>([]);const [input, setInput] = useState('');const sendMessage = async () => { const response = await apiClient.post('/api/chat', { message: input, use_raptor: true }); setMessages(prev => [...prev, response.data]); };return ( <div className="chat-container"> <MessageList messages={messages} /> <InputBox onSend={sendMessage} /> </div> );};
知识库管理组件(KnowledgeBaseManager.tsx)
const KnowledgeBaseManager: React.FC = () => {const [documents, setDocuments] = useState<Document[]>([]);const [treeStructure, setTreeStructure] = useState(null);const buildKnowledgeBase = async () => { await apiClient.post('/api/knowledge-base/build'); const tree = await apiClient.get('/api/knowledge-base/tree'); setTreeStructure(tree.data); };return ( <div className="kb-manager"> <DocumentUploader onUpload={setDocuments} /> <BuildButton onClick={buildKnowledgeBase} /> <TreeVisualization data={treeStructure} /> </div> );};
4.5 前后端数据流
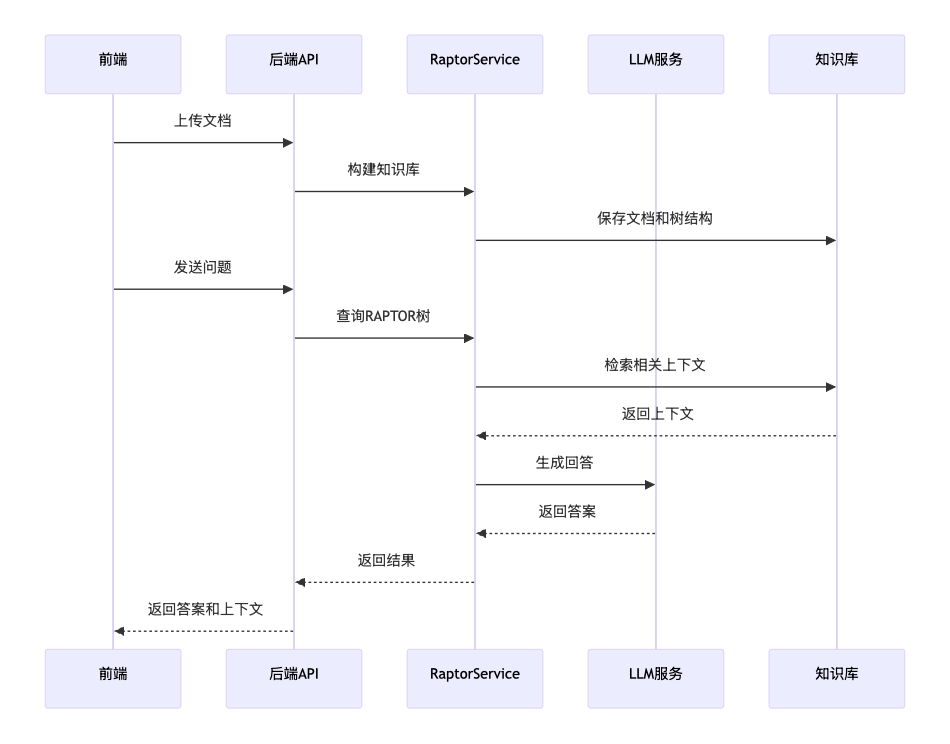
结语
RAPTOR工业设备故障诊断系统通过创新的树形检索技术,结合现代大语言模型的强大能力,为工业设备的智能诊断提供了全新的技术路径。系统不仅实现了RAPTOR的完整功能,还通过多LLM支持、本地化部署等创新特性,大大提升了系统的实用性和可扩展性。
源代码
完整的项目代码和更详细的实现,请访问我的知识星球,获取完整系统项目源代码。
欢迎加入我的知识星球
星球包含本公众号所有付费内容,包括实战源代码、课程等,;另有更多的技术和实战内容,专注大模型、RAG、Agents、Dify、Ragflow、知识图谱等大模型应用研发企业落地实践、案例教程、最新技术动态等内容,重在技术前沿、企业应用和实战,欢迎大家交流。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









