




 本文介绍如何通过userid获取1688店铺的商品列表,详细阐述请求URL、请求方式为GET,并提供请求参数及返回示例。
本文介绍如何通过userid获取1688店铺的商品列表,详细阐述请求URL、请求方式为GET,并提供请求参数及返回示例。
简要描述
- 根据userid获取数据
http://xxx.xxx.xxx.xxx:xxxx/asynSearch
- get +V LP1336790
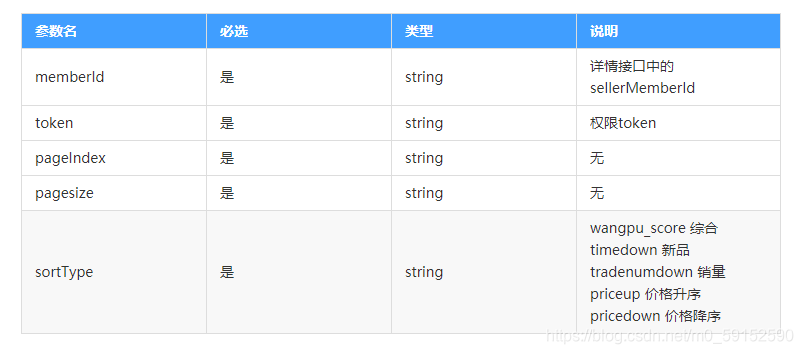 返回示例
返回示例
{
"api": "mtop.1688.shop.data.get",
"data": {
"content": {
"appdata": {
"count": "20",
"hasMore": "true",
"isDiy": "false",
"pageIndex": "1",
"showGap": "true",
"showType": "common",
"sortType": "pricedown"
},
"isPicAuth": "false",
"isPriceAuth": "false",
"isTppOffer": "true",
"offerModuleList": [
[
{
"agentInfo": {
"agentBookedCount": "0",
"agentPrice": "5888.0",
"baoTuiTime": null,
"fahuoTime": "24",
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









