



0.前言
笔者整理自视频这真的是B站讲的最好的MySQL数据库优化教程,2022最新版!_哔哩哔哩_bilibili
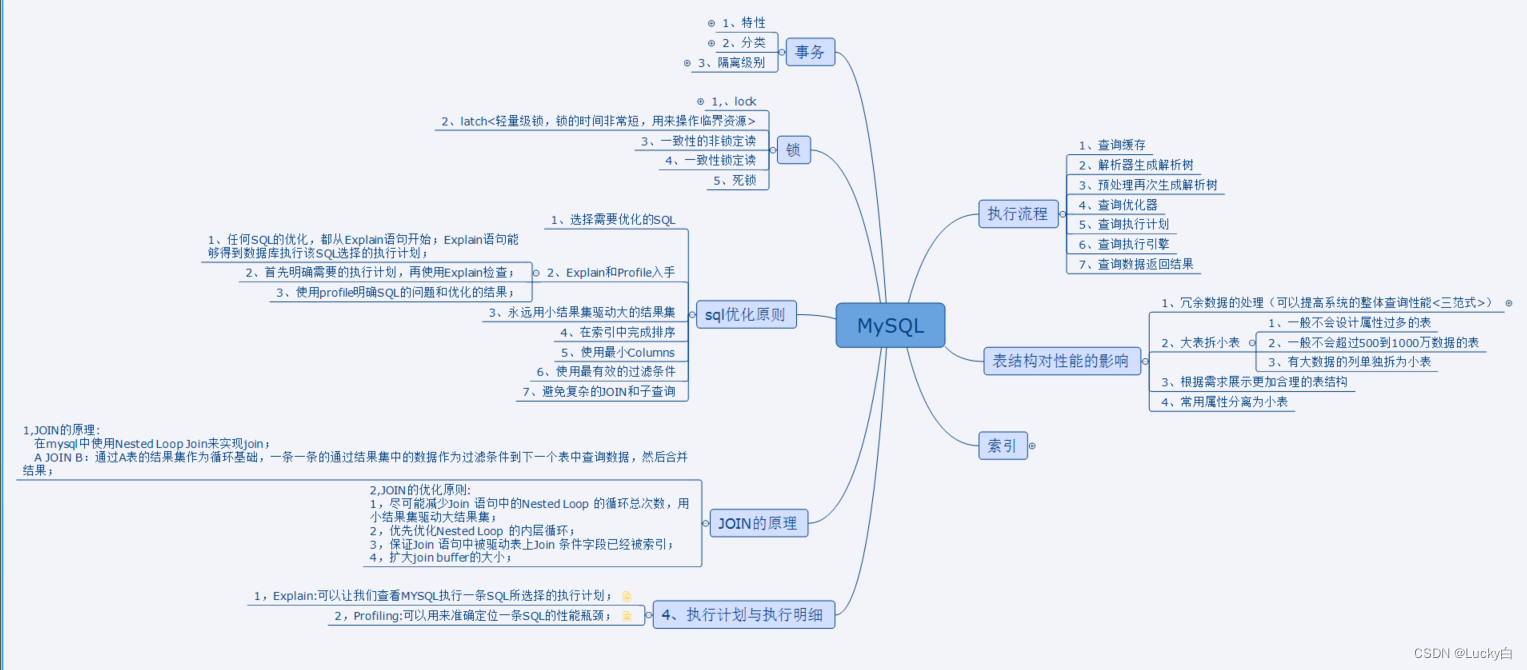
1.有关事务
一组操作,要么全部成功,要么全部失败,目的是为了保证数据最终的一致性。
事务是指访问并可能更新数据库中各种数据项的一个程序执行单元(Unit)。
事务应该具有四个属性:原子性(Atomicity )、一致性(Consistency )、隔离性( lsolation )、持久性( Durability )这四个属性通常称为ACID特性。
目前生产环境所用的隔离级别较多,主要有以下四种:
1)Read Uncommitted
2 ) Read Committed (一般采用)
3 ) Repeatable Read(官方默认)
4 ) Serializable
关于事务需要强调一点:大事务不等于长事务。
事务的相关特性(ACID)
原子性(Atomicity) :当前事务的操作要么同时成功,要么同时失败。原子性由undo log日志来保证。
一致性(Consistency):使用事务的最终目的,由业务代码正确逻辑保证。
隔离性(Isolation):在事务并发执行时,他们内部的操作不能互相干扰。
持久性(Durability) :一旦提交了事务,它对数据库的改变就应该是永久性的。持久性由redo log日志来保证。
事务的隔离性扩充
InnoDB引擎中,定义了四种隔离级别供我们使用,级别越高事务隔离性越好,但性能就越低,而隔离性是由MySQL的各种锁以及MVCC机制来实现的。
read uncommit (读未提交):有脏读问题。
read commit(读已提交):有不可重复读问题。
repeatable read(可重复读):有幻读问题,隔离级别比较高。事务里面只要读到过一次数据,之后再读数据,都以第一次为准。因为可重复读就是我在第一次做任何查询操作的时候,在这一步的时候,数据库当时的所有记录,你可以为它当时有一个快照,我后面在这个事故里面去读任何的其他的数据,不管我靠的还是其他的表,或者说其他的一些行记录的时候,都是以我第一次查询的那一刻的数据库那个快照数据为准,这叫可重复读。在可重复读隔离级别,当事务开启,执行任何查询sql时会生成当前事务的一致性视图read-view,该视图在事务结束之前都不会变化(如果是读已提交隔离级别在每次执行查询sql时都会重新生成),这个视图由执行查询时所有未提交事务id数组(数组里最小的id为min_id))和已创建的最大事务id (max_id)组成,事务里的任何sql查询结果需要从对应版本链里的最新数据开始逐条跟read-view做比对从而得到最终的快照结果。
版本链比对规则:
1.如果 row的 trx_id落在绿色部分( trx_id<min_id ),表示这个版本是已提交的事务生成的,这个数据是可见的;2.如果row的trx_id落在红色部分( trx_id>max_id ),表示这个版本是由将来启动的事务生成的,是肯定不可见的;3.如果 row的trx_id落在黄色部分(min_id <=trx_id<= max_id),那就包括两种情况:
a.若row的 trx_id在视图数组中,表示这个版本是由还没提交的事务生成的,不可见,当前自己的事务是可见的;b.若row的trx_id不在视图数组中,表示这个版本是已经提交了的事务生成的,可见,对于删除的情况可以认为是update的特殊情况,会将版本链上最新的数据复制一份,然后将trx id修改成删除操作的trx_id,同时在该条记录的头信息(record header)里的(deleted flag)标记位写上true,来表示当前记录已经被删除,在查询时按照上面的规则查到对应的记录如果delete_flag标记位为true,意味着记录已被删除,则不返回数据。
serializable (串行):上面问题全部解决。(隔离级别是最高的。)
对串行化的了解:
读锁(共享锁、S锁): select .... lock in share mode;
读锁是共享的,多个事务可以同时读取同一个资源,但不允许其他事务修改。
写锁(排它锁、X锁): select ... for update;
写锁是排他的,会阻塞其他的写锁和读锁,update、delete、insert都会加写锁。
读锁写锁之间是互斥的。
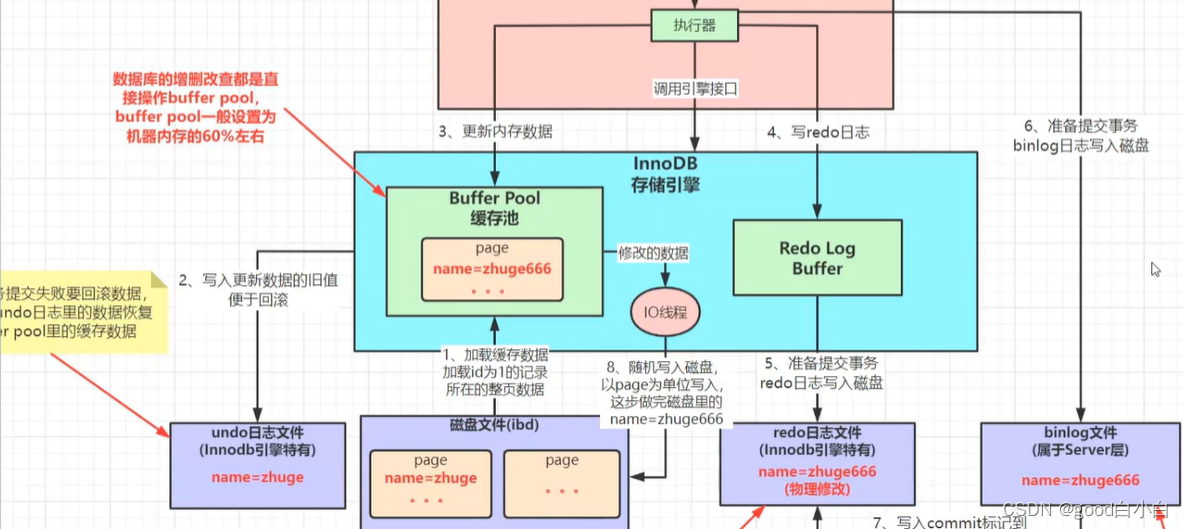
MySQL引入了redo log,Buffer Pool内存写完了,然后会写一份redo log,这份redo log记载着这次在某个页上做了什么修改。
即便MySQL在中途挂了,我们还可以根据redo log来对数据进行恢复。
redo log是顺序写的,写入速度很快。并且它记录的是物理修改(xxxx页做了xxx修改),文件的体积很小,恢复速度也很快。
长事务的影响
·并发情况下,数据库连接池容易被撑爆
锁定太多的数据,造成大量的阻塞和锁超时
·执行时间长,容易造成主从延迟
·回滚所需要的时间比较长undo log膨胀
·容易导致死锁
事务优化
优化原则:在保证业务逻辑的前提下,尽可能宿短事务长度
大事务拆分为小事务
DDL拆分(无锁变更)
长事务合并为大事务
长事务分解(不必要的请求摘除)
应用侧保证一致性
2.有关索引(阿里规约)
1.单表索引数量控制5个以内
2.不允许存在重复索引和冗余索引
3.防止字段隐式转换导致的索引失效
4.SQL优化目标:至少达到range级别
5.利用覆盖索引避免回表操作
6.禁止超过三个表的join
7.在varchar上建立索引,指定索引长度
8.索引字段值不允许设置为null,必须设置默认值
9.单表数据量控制在100Ow以内
10.字段列数量建议在30以内
11.不建议使用MySQL分区表
12.单表行数超过500w或者单表容量超过2G建议分库分表
(二)索引规约
1.【强制】业务上具有唯一特性的字段,即使是组合字段,也必须建成唯一索引。
说明∶不要以为唯一索引影响了insert速度,这个速度损耗可以忽略,但提高查找速度是明显的;另外即使在应用层做了非常完善的校验控制,只要没有唯一索引,根据墨菲定律,必然有脏数据产生。
2.【强制】超过三个表禁止join。需要join的字段,数据类型保持绝对一致;多表关联查询时
保证被关联的字段需要有索引。说明︰即使双表join 也要注意表索引、SQL性能。
3.【强制】在varchar字段上建立索引时,必须指定索引长度,没必要对全字段建立索引,根据,实际文本区分度决定索引长度。
说明∶索引的长度与区分度是一对矛盾体,一般对字符串类型数据,长度为20的索引,区分度会高达90%以上,可以使用count(distinct left(列名,索引长度))/count(*)的区分度来确定。
4.【强制】页面搜索严禁左模糊或者全模糊,如果需要请走搜索引擎来解决。
说明︰索引文件具有B-Tree的最左前缀匹配特性,如果左边的值未确定,那么无法使用此索引。
5.【推荐】如果有order by的场景,请注意利用索引的有序性。order by最后的字段是组合。
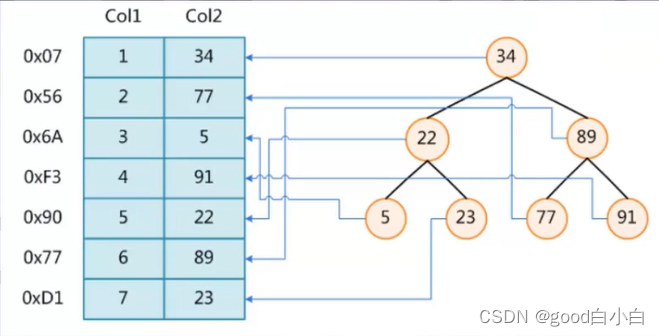
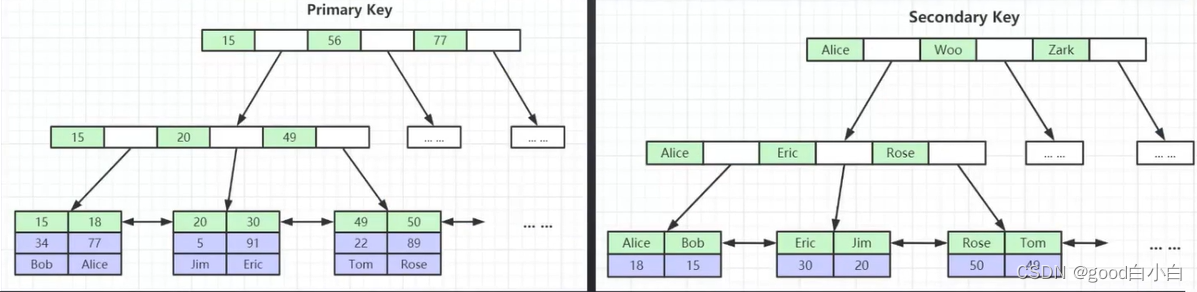
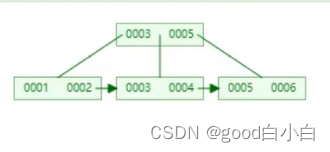
·索引————是帮助MySQL高效获取数据的 排好序的 数据结构
索引数据结构
二叉树 红黑树 Hash表 B-Tree
B+Tree B-Tree变种
·非叶子节点不存储data,只存储索引(冗余),可以放更多的索引·
叶子节点包含所有索引字段
·叶子节点用指针连接,提高区间访问的性能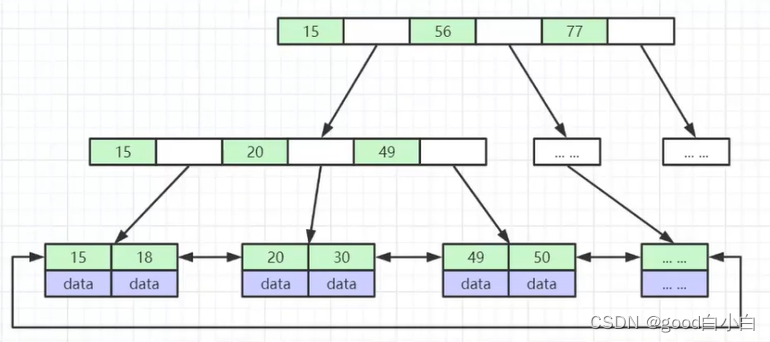


这里引用数据库优化的四大方法_瘦弱的皮卡丘的博客-优快云博客_数据库优化的观点。
1.查看执行计划 explain sql。如果有告警信息,查看告警信息 show warnings;
2.查看SQL涉及的表结构和索引信息3.根据执行计划,思考可能的优化点
4.按照可能的优化点执行表结构变更、增加索引、SQL改写等操作5.查看优化后的执行时间和执行计划。6.如果优化效果不明显,重复第四步操作。
1、选取最适用的字段属性 2、使用连接(JOIN)来代替子查询(Sub-Queries) 3、使用联合(UNION)来代替手动创建的临时表

















 391
391

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









