




先认识标签:
table表标签
tr行标签
td列标签
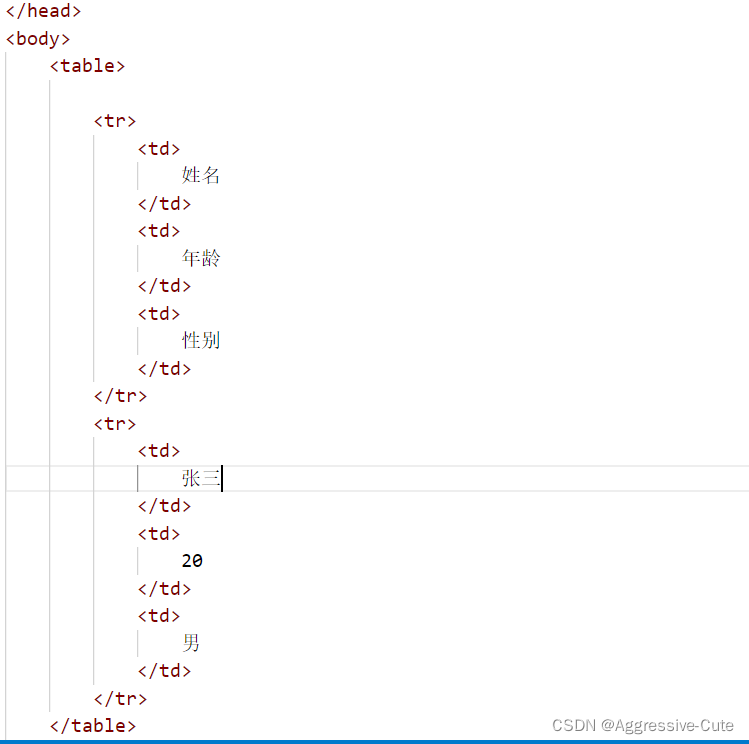
简单创建一个表:
ul:无序列表、数据无关来联、在爬虫领域中使用较多;ol:顺序列表,数据相关联,爬虫使用场景少。
演示如下:


table里面可以设置的属性:width、height、border(边框) "xx px"
a标签:
超链接 href="域名"
点击超链接,页面会自动跳转到百度这个url(网址)


什么叫爬虫?
1、爬虫一段程序,通过url域名爬取网页的信息
2、程序模拟浏览器获取有用的数据
核心:爬取网页所有的数据 解析获取有用的数据
爬虫难点?
爬与反爬之间的博弈 就像是追女朋友 <你要满足她的种种要求、然后一网打尽获取想要的数据>
爬虫能干什么???
数据分析:数据收集起来分析规律,这些数据是怎们样的;
人工抓取数据:获得想要的数据;
舆情分析:分析;
社交软件的冷启动:例如陌陌爬取微博上面的用户数据,让你聊天,假人引流;
竞争对手的监督:像国内的两大电商阿里和京东,互相爬取数据,分析,修改上价格,提高销售量
再例如:12306抢票台 其他软件也能实现抢票功能 就是因为怕取了12306的数据;
政府部门的天气数据等等.......
爬虫类型:
通用爬虫,意义不大;
聚焦爬虫,我们主要学习这个类型的爬虫技术。
常见的反爬手段:
UA;
代理ip;
验证码验证;
动态加载网页(返回假的数据);
数据加密(字体加密...)
爬取数据之get请求方式:
'''
使用urllib.request库爬取数据
请求对象定制、模拟浏览器访问服务器获取需求、读取解码数据...
url 路径
respose=urllib.request.urlopen() 返回需求
content=respose.read().decode("utf-8")获取数据
注意:
response的数据类型是“HTTPResponse”
字节->字符串 read()读取的是字节(B),需要解码显示字符串,才可以看到中文
字符串->字节 编码 encode()
read() 字节形式读取二进制 拓展 read(5)只读五个字节的数据并且返回
readlind() 只读一行数据
readlines()读取所有数据 每一行作为索引返回成为一个列表。
getcode() 获取当前状态码 正确为200 错误 如 404...
geturl() 获取当前访问网页路径(域名[主机])
getheaders() 获取用户信息(cpu型号 浏览器版本、信息这些)
'''
总结:
一个类型:response类型为 HTTPResponse
六个方法:read() readline() readlines() getcode() geturl() getheaders()
注意:
read方法:
返回的是二进制数据,我们要将二进制的数据转换成字符串需要解码decode() 字符串->字节 需要编码encode()
'''
使用urllib.request.urlretrieve()下载网页、图片、视频:
# 下载视频 mp4 # import urllib.request # url_vedio="https://vd3.bdstatic.com/mda-na93kr391yq0zeq9/cae_h264/1641782208996425563/mda-na93kr391yq0zeq9.mp4?v_from_s=hkapp-haokan-suzhou&auth_key=1641812993-0-0-05416df08744469cd594da52838260a4&bcevod_channel=searchbox_feed&pd=1&pt=3&logid=2393887674&vid=8494476860693044414&abtest=100254_2&klogid=2393887674" # urllib.request.urlretrieve(url_vedio,'news.mp4')
补充知识:
url="https://www.baidu.com"
http/https(更加安全)协议
www.baidu.com主机
端口号:http(80)/https(443)
路径:s
wd:参数
#:锚点
request对象:url+data+headers
传参:位置传参、关键字传参、......
'''
'''
get请求:
编解码 urllib.parse quote/unicode
转换编码(unicode全球编码):urllib.parse.quoto()真对单个字符/encode()针对多个字符--data({:},:)
base_url+data 转换层可以用的url url=base_url+data
'''
# https://www.baidu.com/baidu?tn=monline_3_dg&ie=utf-8&wd=%E9%99%88%E5%A5%95%E8%BF%85 可以使用的
# import urllib.request
# headers={
#
# 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:95.0) Gecko/20100101 Firefox/95.0'
# }
# url="https://www.baidu.com/baidu?tn=monline_3_dg&ie=utf-8&wd=%E9%99%88%E5%A5%95%E8%BF%85"
# request=urllib.request.Request(url=url,headers=headers)
# response=urllib.request.urlopen(request)
# content=response.read().decode('utf-8')
# print(content)
# base_url="https://www.baidu.com/baidu?tn=monline_3_dg&ie=utf-8&wd=" 少了一个陈奕迅需要unicode编码
# 需要将 陈奕迅 改成unicode编码格式 单个依赖于parse.quote()
# 实现
# import urllib.request
# import urllib.parse
# base_url="https://www.baidu.com/baidu?tn=monline_3_dg&ie=utf-8&wd="
# name=urllib.parse.quote("陈奕迅")
# new_url=base_url+name
# headers={
# 'User-Agent':
# 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:95.0) Gecko/20100101 Firefox/95.0'
# }
# request=urllib.request.Request(url=new_url,headers=headers)
# response=urllib.request.urlopen(request)
# content=response.read().decode("utf-8")
# print(content)
# 简单来说就是转换成unicode编码 1/请求对象定制(UA/https) 2/模拟获得响应 3/读取解码数据
# tn=monline_3_dg&ie=utf-8&wd=陈奕迅 针对多个需要编码转换 parse.urlencode()针对多个参数编解码
import urllib.request
import urllib.parse
base_url="https://www.baidu.com/baidu?"
data={
'tn':'monline_3_dg',
'ie':'utf-8',
'wd':'陈奕迅'
}
url=urllib.parse.urlencode(data)
new_url=base_url+url
headers={
'User-Agent':
'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:95.0) Gecko/20100101 Firefox/95.0'
}
# 请求资源路径
request=urllib.request.Request(url=new_url,headers=headers)
response=urllib.request.urlopen(request)
content=response.read().decode('utf8')
print(content)
# request->response->content 爬虫第一步大致流程 第二步解析数据,找到需要的数据
SUMMERY:
简单来说get请求方式就三步:
urllib.request/urllib.parse
1、请求对象定制 url、headers;
2.模拟浏览器访问服务器获得响应;
3、读响应数据并且解码,获得数据;
request->response->content
具体步骤:
- (url+headers)合法 request=url.request.Request(url=url,headers=headers)
- response=urllib.request.urlopen(request)
- content=response.read().decode("utf-8")

















 1571
1571

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









