



 本文详细介绍了MySQL索引的工作原理,包括存储位置、数据结构如B+树和哈希表,以及存储引擎的区别。重点讲解了B+树的特点和在MySQL中的应用,特别是聚簇索引和非聚簇索引的概念。此外,还讨论了索引优化相关的技术名词,如回表、索引覆盖和最左匹配。
本文详细介绍了MySQL索引的工作原理,包括存储位置、数据结构如B+树和哈希表,以及存储引擎的区别。重点讲解了B+树的特点和在MySQL中的应用,特别是聚簇索引和非聚簇索引的概念。此外,还讨论了索引优化相关的技术名词,如回表、索引覆盖和最左匹配。
目录
索引
概述
索引是帮助MySQL高效获取数据的数据结构。
MySQL索引原理和数据结构介绍
存储位置
索引的数据文件也需要持久化存储,存储到磁盘中,当需要时把数据从磁盘中读取到内存中,加快数据的访问(分块读取)
局部性原理:
数据和程序都有聚集成群的倾向,之前被查过的数据很快会被再次查询,冷热数据
磁盘预读
在数据交换的时候,会有一个基本的逻辑单位,称之为页,一般占用空间是4K/8K,跟操作系统相关,每次在进行数据获取的时候,可以获取页的整数倍(读取数据时,以页的整数倍读取数据,MySQL中innodb的存储引擎读取数据的时候会读取16K(innodb_page_size value=16K))
数据结构(B+树 )
K-V格式的数据:哈希表、树
哈希表
hashmap用的红黑树
缺点:
-
范围查找需要遍历每一个元素,如果全部是等值查找可以用Hash表
-
碰撞--冲突:数据散列不均匀,浪费存储空间,因此要求设计足够好的hash算法
-
如果存储大量数据,会占用大量的存储空间,而且不能够分块读取
存储引擎(数据文件在存储介质中的不同组织形式)
-
innodb
-
MyISAM
-
memory (hash索引,MySQL官网介绍)
树(二叉树、BST、AVL、红黑树、B树、B+树)
-
二叉树、BST、AVL、红黑树 二叉树有且仅有两个分支
-
BST、AVL、红黑树 有序二叉树
-
AVL、红黑树 二叉平衡树
B树、B+树
多叉有序树
degree:阶/度,表示每个节点至多存放多少条记录(degree=4,最多插入3条,插入第四条开始分支)
B树:
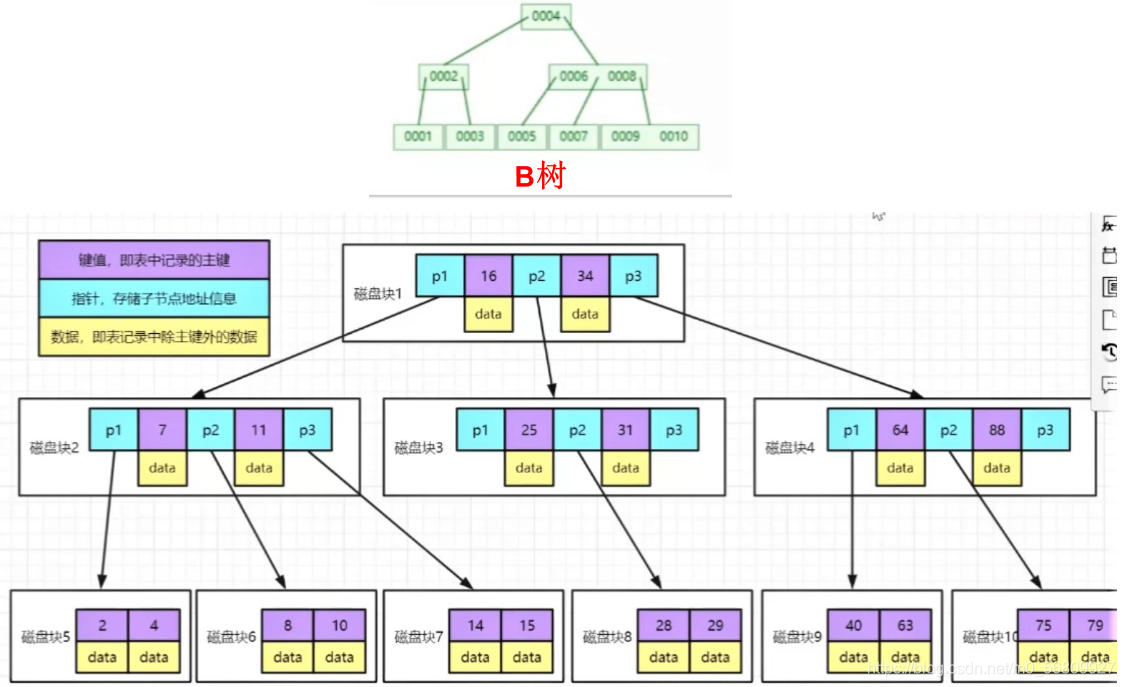
16:键值,即表中记录的主键
P:指针,存储子节点地址信息
data:数据,即表记录中处主键外的数据
B+树:
B+树每个节点可以包含更多的节点,这么做的原因有:
-
降低树的高度
-
将数据范围变为多个区间,区间越多,数据检索越快
非叶子节点存储key,叶子节点存储key和数据
叶子节点两两指针相互连接(符合磁盘的预读特性),顺序查询性能更高
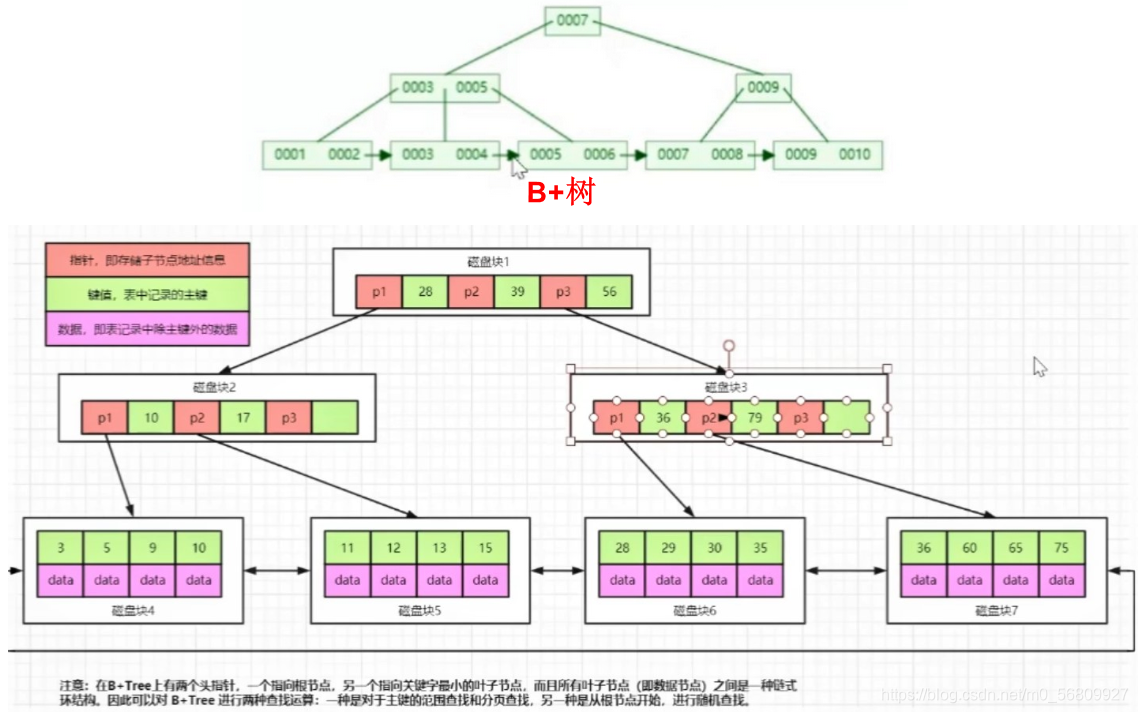
MySQL数据层数:千万级别三到四层,key要尽可能少的占用空间,所以int比varchar好
MySQL聚簇索引和非聚簇索引区别?
判断数据和索引是否放在一起,放在一起就是聚簇索引,不放在一起就是非聚簇索引
在innodb中,数据在进行插入的时候必须要跟某一个索引的值进行绑定,这个值默认是主键,如果没有主键,选择唯一键,没有唯一键选择六字节的rowid。→数据一定跟索引存放(.frm .ibd)
一个表中可以有多少个索引?
索引如果是跟数据放在一起的话,数据会只存储一份
id,name,age,gender,address,id是主键,name是普通索引→
在整个表中会有两个B+树,主键是跟数据放在一起的,name所在的B+树叶子节点中放置的是id的值。
select * from table where name=?→执行这个语句会走两科B+树,先根据nameB+树检索到id值,再根据id值到idB+树检索到整体行记录
由上得到结论:innodb中一定有聚簇索引(id是聚簇索引,name是非聚簇索引),但是其他索引都是非聚簇索引
MyISAM只有非聚簇索引
关于索引的技术名词
id,name,age,gender id是主键,name是普通索引回表
select * from table where name='小美女'
从非聚簇索引跳转到聚簇索引中查找数据的过程称为回表,效率不高,因此在工作中避免回表操作索引覆盖
select id,name from table where name='小美女'
当非聚簇索引的叶子节点中包含了查询需要的所有字段时,不需要回表,这个过程称为索引覆盖,推荐使用索引覆盖最左匹配
id,name,age,gender id是主键,name,age是普通索引,组合索引除了第三条都符合最左匹配(从name到age,先过滤name)
第四条MySQL优化器会优化为先name后age
select * from table where name=? and age=?
select * from table where name=?
select * from table where age=?
select * from table where age=? and name=?索引下推
select * from table where name=? and age=?
在没有索引下推之前,执行过程是先根据name从存储引擎中拉取数据,然后根据age在server中过滤
有了索引下推后,执行过程是根据(name,age)整体的从存储引擎中做数据检索,返回对应的记录,不在server层做任何操作(把检索内容从server层推到存储引擎层)案例1
创建表abc,id主键索引,a、b、c为组合索引idx_1
CREATE TABLE abc(id INT PRIMARY KEY,a INT,b INT,c INT);
ALTER TABLE abc ADD INDEX idx_1(a,b,c);
SHOW INDEX FROM abc;
EXPLAIN SELECT * FROM abc WHERE a=1 AND b=1 AND c=1;
EXPLAIN SELECT * FROM abc WHERE b=1 AND c=1;
EXPLAIN SELECT * FROM abc WHERE c=1;三个查询都用到了索引
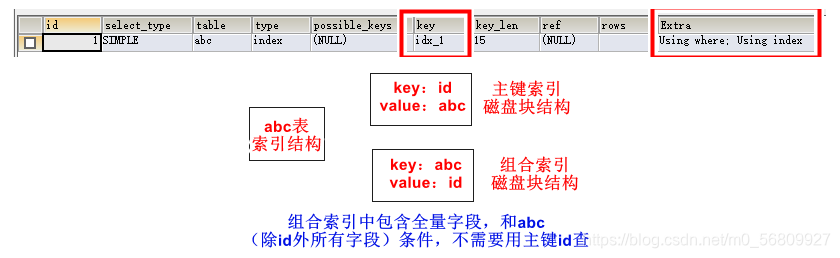
当表中的全部列(除主键索引列外)都是组合索引列的时候,无论怎么查都会用到索引
案例2
创建表abcd,id主键索引,a、b、c为组合索引idx_2,d无索引
CREATE TABLE abcd(id INT PRIMARY KEY,a INT ,b INT,c INT ,d INT);
ALTER TABLE abcd ADD INDEX idx_2(a,b,c);
SHOW INDEX FROM abcd;
EXPLAIN SELECT * FROM abcd WHERE a=1 AND b=1 AND c=1 AND d=1;用到了索引
EXPLAIN SELECT * FROM abcd WHERE b=1 AND c=1 AND d=1;没用到索引
EXPLAIN SELECT * FROM abcd WHERE c=1 AND d=1;没用到索引
EXPLAIN SELECT * FROM d=1;没用到索引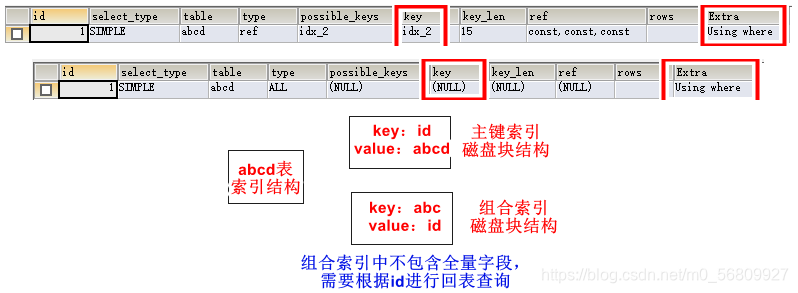
案例3
创建表abc,id主键索引,a、b、c为组合索引 idx_2,d为普通索引 idx_3
ALTER TABLE abcd ADD INDEX idx_3(d);
EXPLAIN SELECT * FROM abcd WHERE id=1;-- (当表为空时没有用到主键索引)用到主键索引,索引长度4
EXPLAIN SELECT * FROM abcd WHERE d=1; -- 用到索引idx_3,索引长度5
EXPLAIN SELECT * FROM abcd WHERE a=1 AND b=1 AND c=1;-- 用到索引idx_2索引长度15
EXPLAIN SELECT * FROM abcd WHERE a=1 AND b=1;-- 索引长度10
EXPLAIN SELECT * FROM abcd WHERE a=1;-- 索引长度5
EXPLAIN SELECT * FROM abcd WHERE b=1 AND c=1;-- 没有用到索引
EXPLAIN SELECT * FROM abcd WHERE c=1;-- 没有用到索引
EXPLAIN SELECT * FROM abcd WHERE a=1 AND c=1;-- 用到索引idx_2 索引长度5案例4
创建表abc,id主键索引,a、b、c、d为组合索引idx_2
ALTER TABLE abcd ADD INDEX idx_2(a,b,c,d);
EXPLAIN SELECT * FROM abcd WHERE d=1;-- 用到了idx_2索引,索引长度20
EXPLAIN SELECT * FROM abcd WHERE c=1;-- 用到了idx_2索引,索引长度20
EXPLAIN SELECT * FROM abcd WHERE b=1;-- 用到了idx_2索引,索引长度20
EXPLAIN SELECT * FROM abcd WHERE a=1;-- 用到了idx_2索引,索引长度5
EXPLAIN SELECT * FROM abcd WHERE a=1 AND b=1;-- 用到了idx_2索引,索引长度10
EXPLAIN SELECT * FROM abcd WHERE a=1 AND b=1 AND c=1;-- 用到了idx_2索引,索引长度15
EXPLAIN SELECT * FROM abcd WHERE a=1 AND b=1 AND c=1 AND d=1;-- 用到了idx_2索引,索引长度20
EXPLAIN SELECT * FROM abcd WHERE a=1 AND b=1 AND d=1;-- 用到了idx_2索引,索引长度10
EXPLAIN SELECT * FROM abcd WHERE id=1;-- 用到了主键索引,索引长度为4IO
IO是硬件层面的瓶颈,软件方面有IO量和IO次数
减少IO量、减少IO次数,公司禁止写select *(IO量增多)

















 494
494

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









