




总体介绍
从整体上看,DDPM包括两个过程,即:扩散过程和反向过程。其中,扩散过程就是对一张图片逐渐添加高斯噪声,直至其变成随机噪声;而反向过程实际上是一个去噪过程,根据扩散过程中学习到的图片风格,对随机噪声逐渐进行去噪,最终生成一张与学到的风格相同的图片。DDPM的本质作用就是:学习训练数据的分布,从而生成尽可能符合训练数据分布的真实图片。 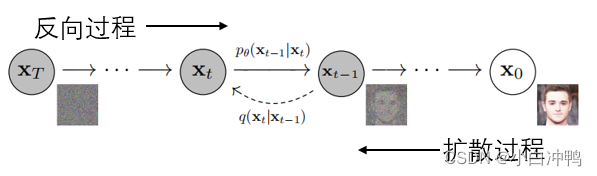
扩散过程


 DDPM:扩散与反向过程的生成艺术,
DDPM:扩散与反向过程的生成艺术,
 DDPM通过扩散过程添加高斯噪声至图片,再通过反向过程学习并去噪,模仿训练数据的分布生成逼真图片。核心是理解数据分布并生成新样本。
DDPM通过扩散过程添加高斯噪声至图片,再通过反向过程学习并去噪,模仿训练数据的分布生成逼真图片。核心是理解数据分布并生成新样本。
从整体上看,DDPM包括两个过程,即:扩散过程和反向过程。其中,扩散过程就是对一张图片逐渐添加高斯噪声,直至其变成随机噪声;而反向过程实际上是一个去噪过程,根据扩散过程中学习到的图片风格,对随机噪声逐渐进行去噪,最终生成一张与学到的风格相同的图片。DDPM的本质作用就是:学习训练数据的分布,从而生成尽可能符合训练数据分布的真实图片。
 6178
6178

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言




 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章























