




 本文深入探讨了Kafka的消费者工作流程,重点介绍了消费者组的概念和操作,包括初始化、消费流程以及分区分配策略如Range和Roundrobin。此外,还讨论了offset管理和数据积压问题,强调了消费者事务在确保消息一致性中的作用。
本文深入探讨了Kafka的消费者工作流程,重点介绍了消费者组的概念和操作,包括初始化、消费流程以及分区分配策略如Range和Roundrobin。此外,还讨论了offset管理和数据积压问题,强调了消费者事务在确保消息一致性中的作用。
目录
一、kafka的消费方式
由
broker
决定消息推送的速率,对于不同消费速率的
consumer
就不太好处理
了。消息系统都致力于让
consumer
以最大的速率最快速的消费消息,但不幸的是,
push
模式下,
当broker 推送的速率远大于 consumer 消费的速率时,consumer 恐怕就要崩溃了
。最终
Kafka
还是选取了传统的
pull
模式。
Pull
模式的另外一个好处是
consumer 可以自主决定是否批量的从 broker 拉取数据
。
Push
模式必须在不知道下游
consumer
消费能力和消费策略的情况下决定是立即推送每条消息还是缓存之后批量推
送。如果为了避免
consumer
崩溃而采用较低的推送速率,将可能导致一次只推送较少的消息而造成浪
费。
Pull
模式下,
consumer
就可以根据自己的消费能力去决定这些策略。
Pull 有个缺点
是,
如果 broker 没有可供消费的消息,将导致 consumer 不断在循环中轮询,直到新消息到达
。为了避免这点,
Kafka
有个参数可以让
consumer
阻塞知道新消息到达
(
当然也可以阻塞知道
消息的数量达到某个特定的量这样就可以批量发送
)

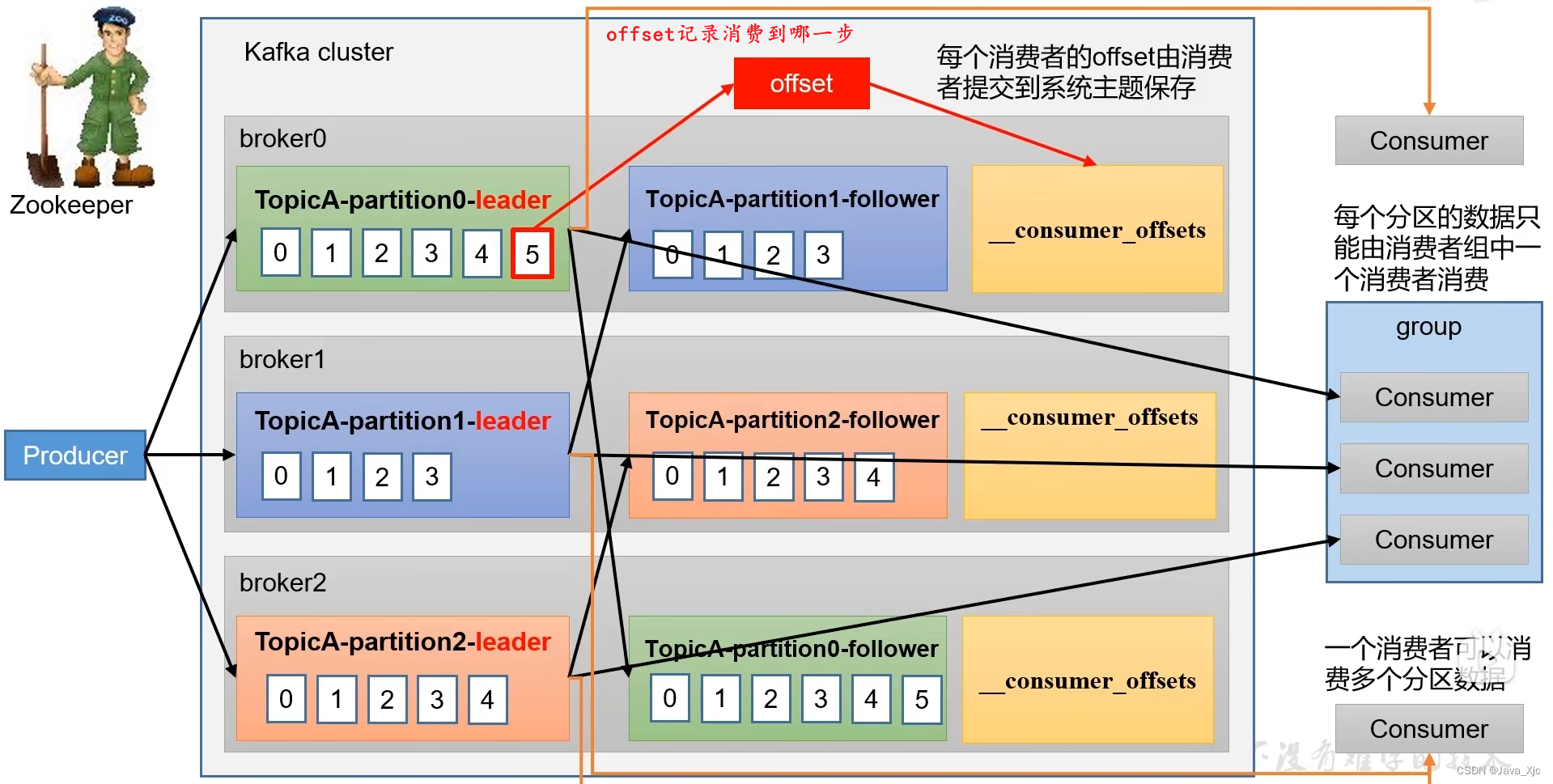
二、消费者总体工作流程
每个分区的数据只能由消费者组中的一个消费者消费
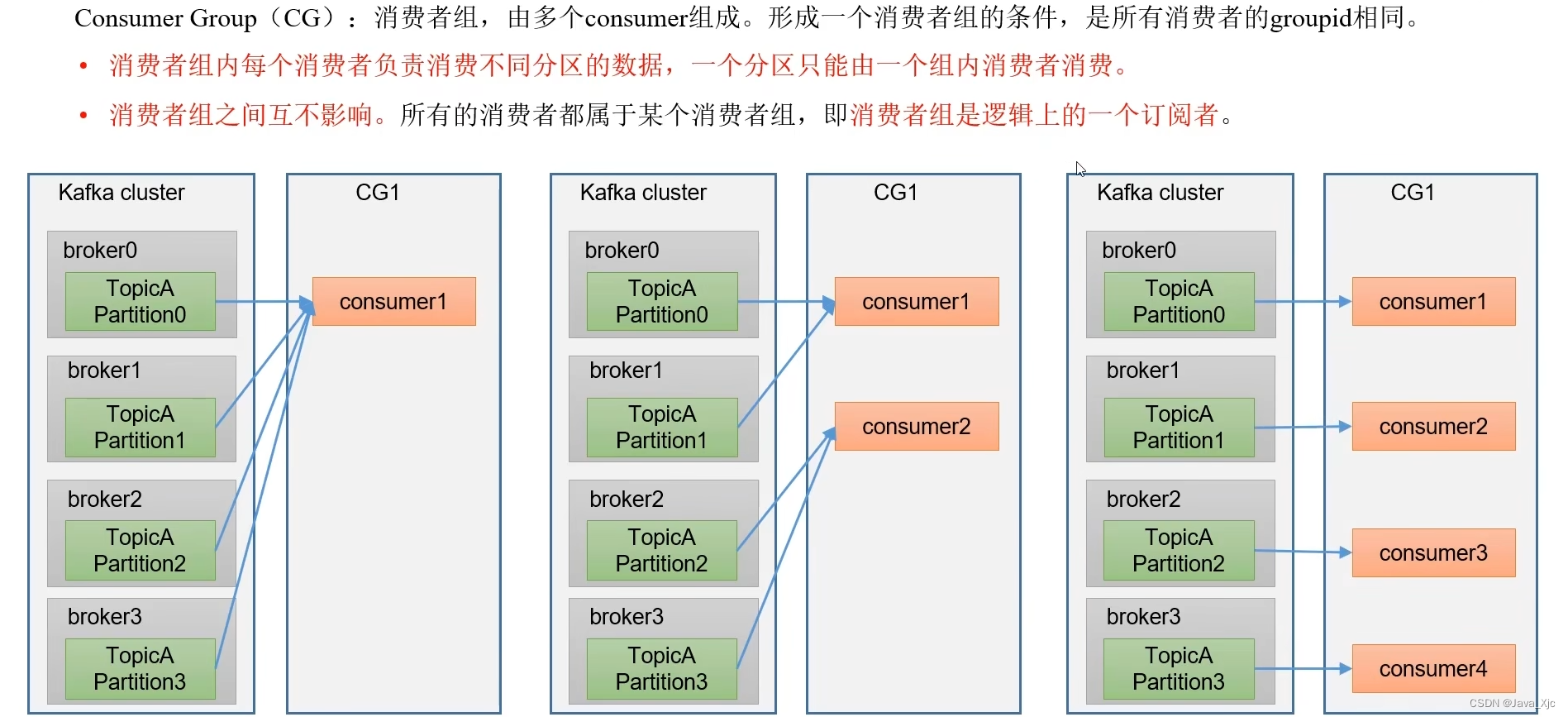
三、消费者组
消费者组工作原理
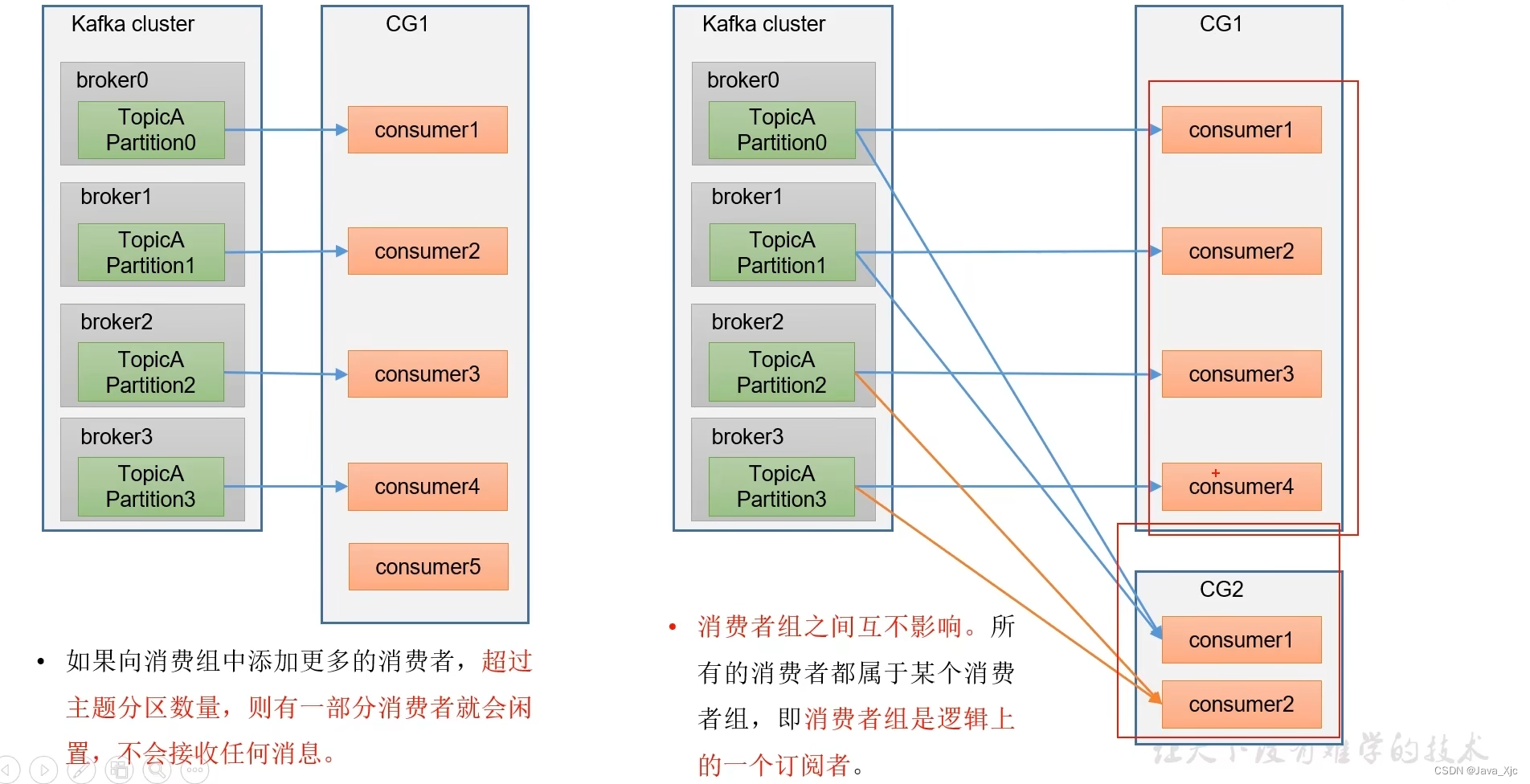
消费者组初始化
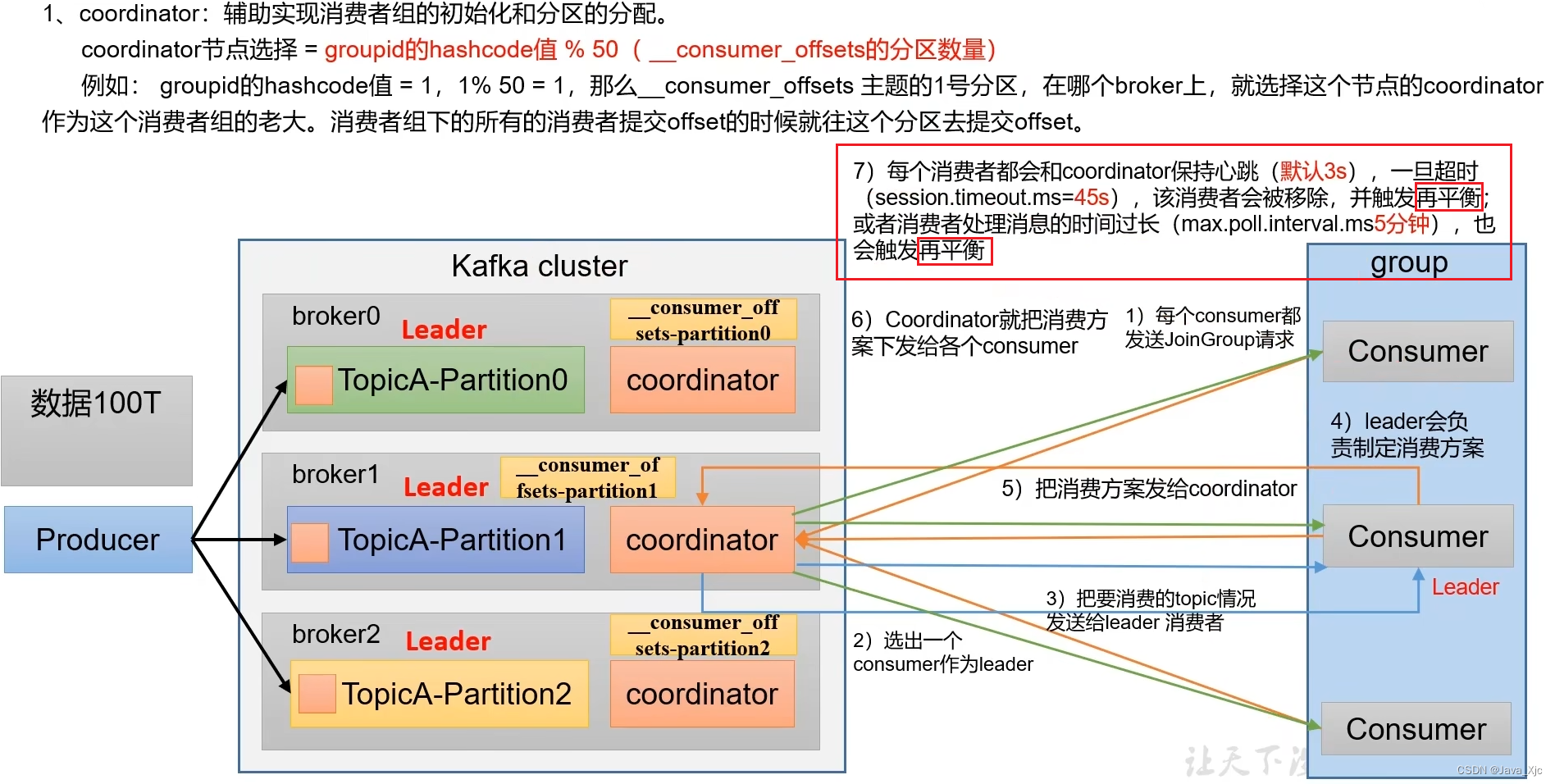
消费者组详细消费流程
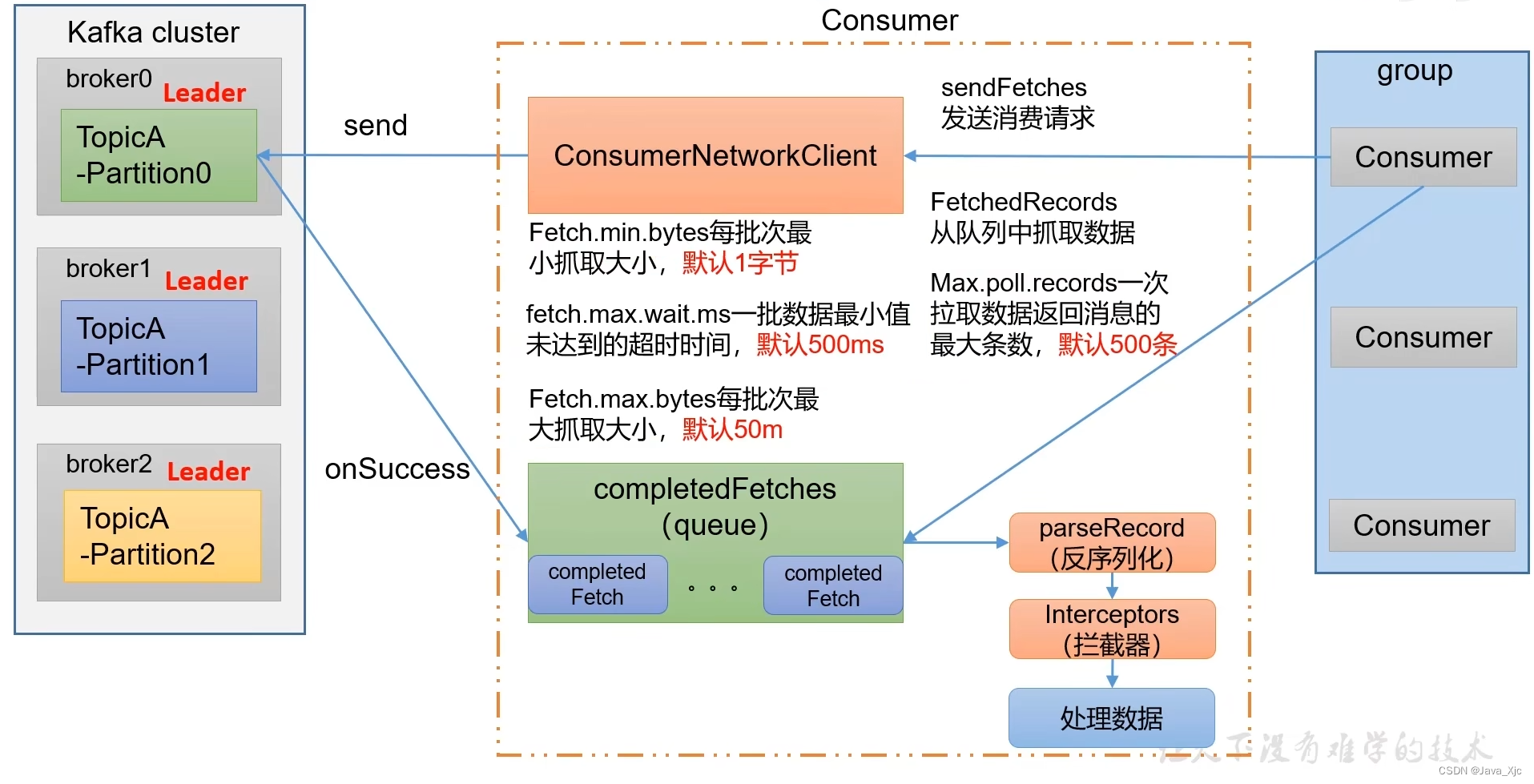
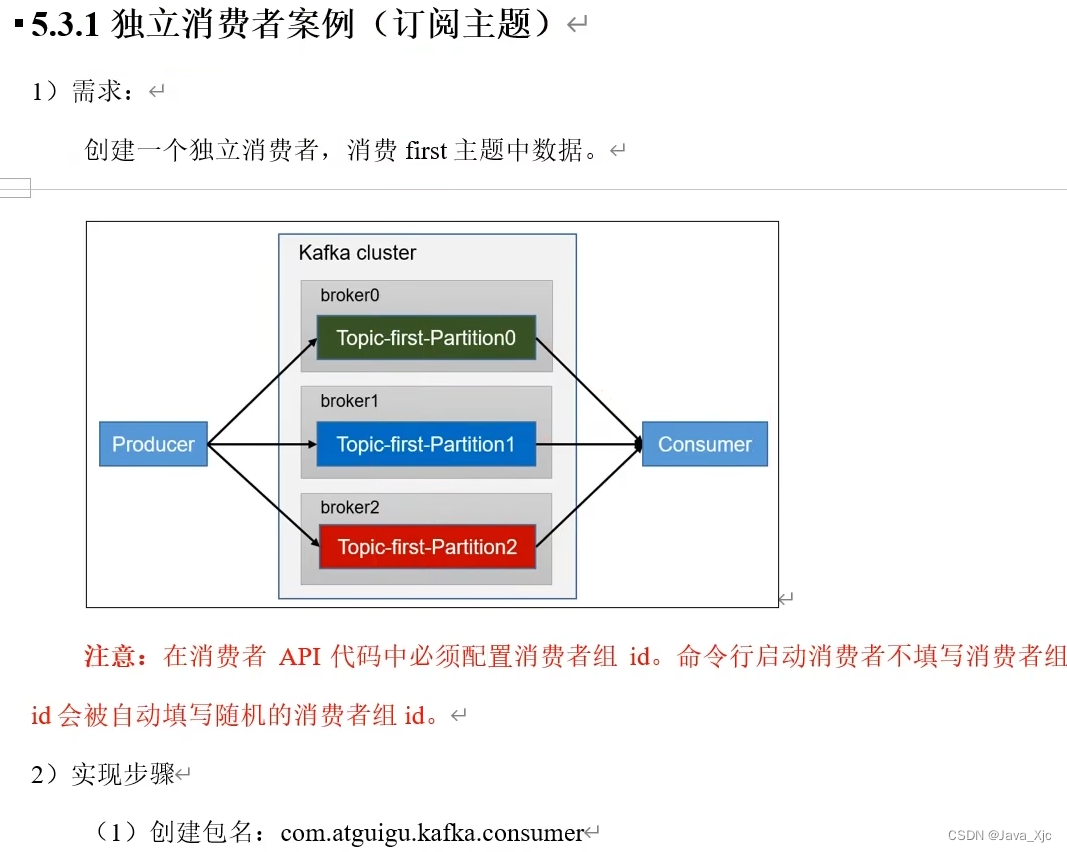
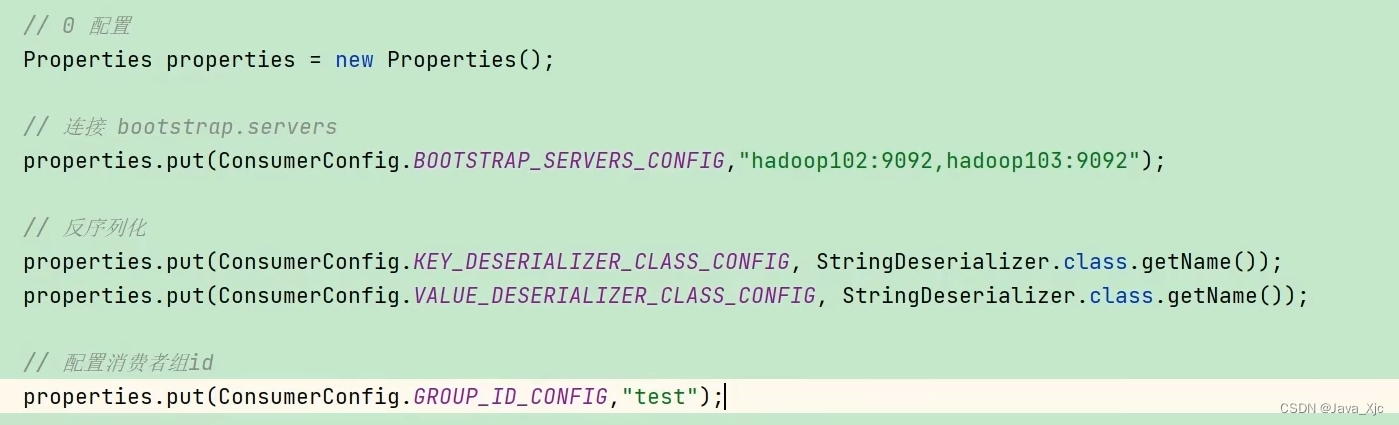
消费一个主题

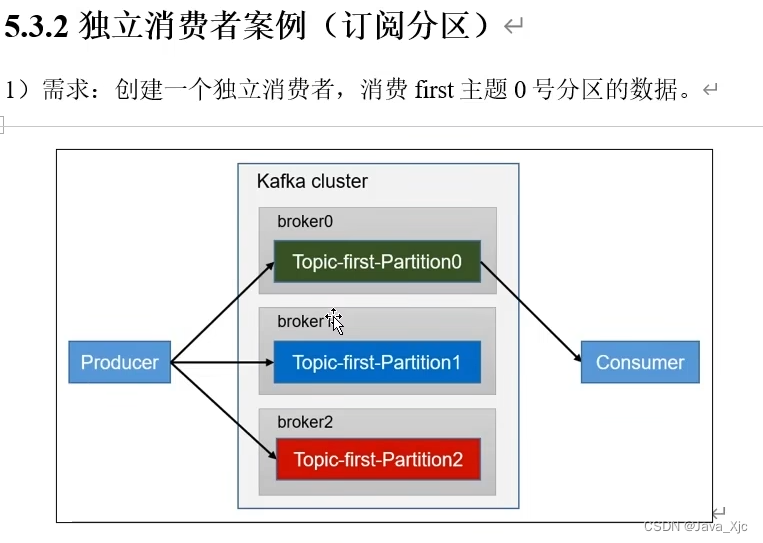
消费一个分区


消费者组案例

消费者组id相同,那么都在同一个消费者组!
一个分区的数据只会由一个消费者消费!

四、分区分配以及再平衡
分区分配策略Range
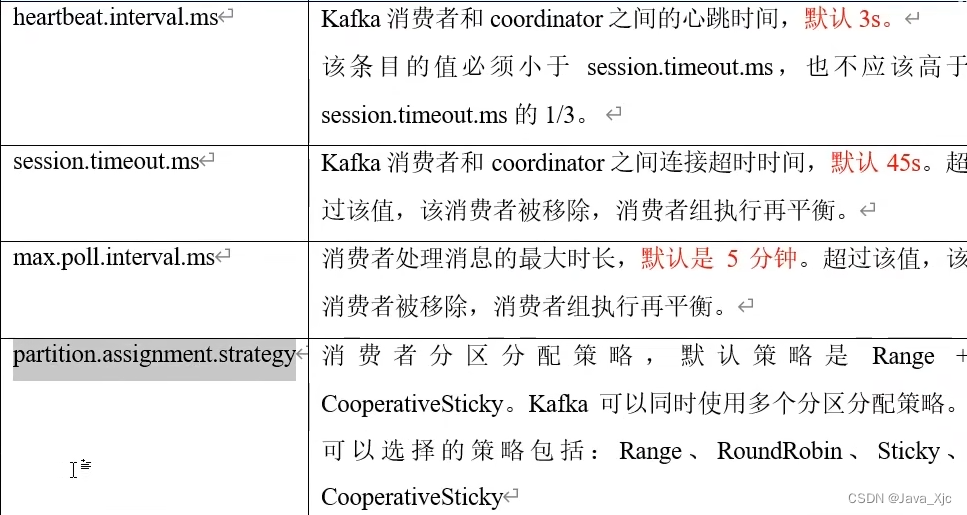
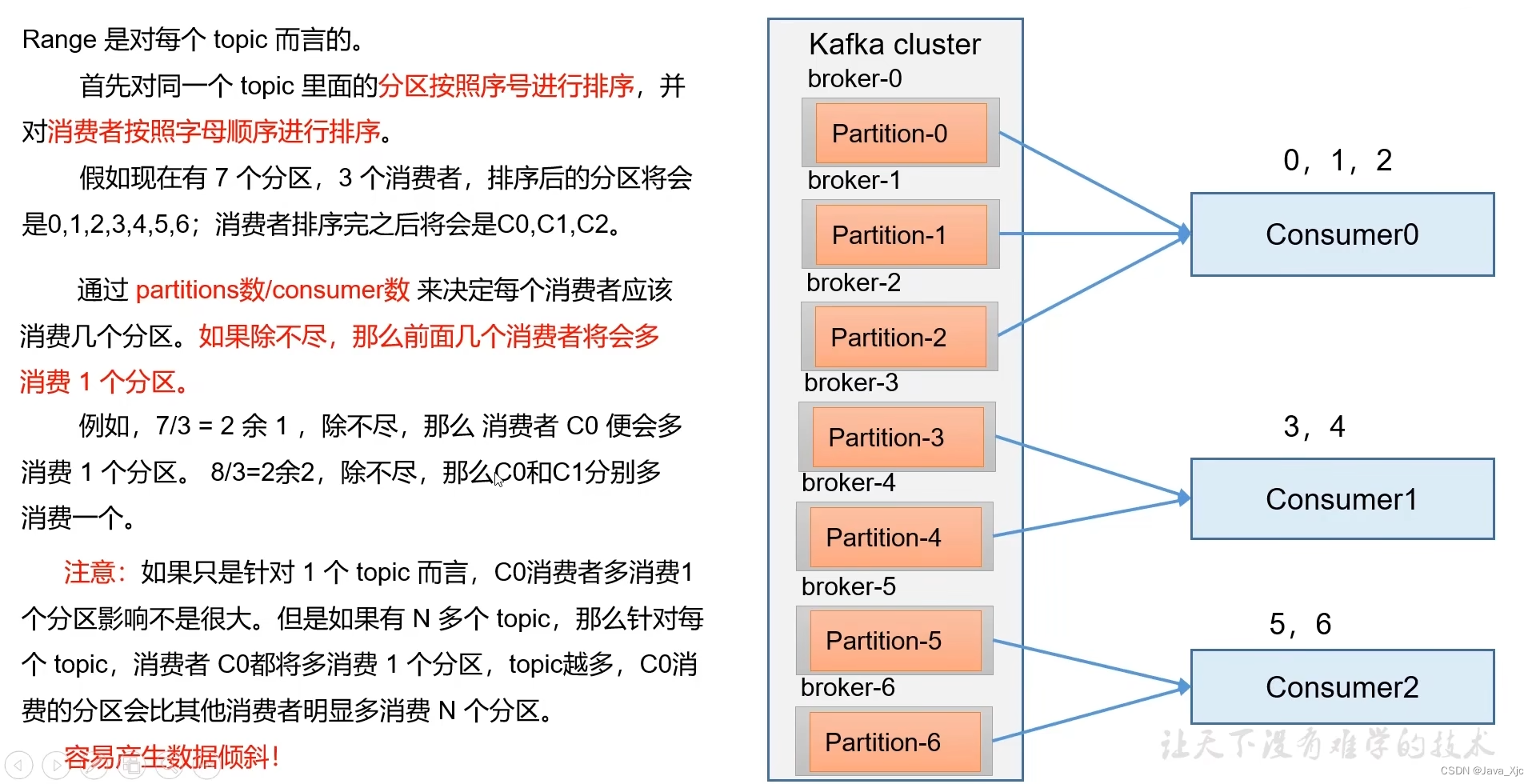
如果有多个Topic,可能会导致多出来的分区都由C0消费,导致C0消费过多,即数据倾斜!
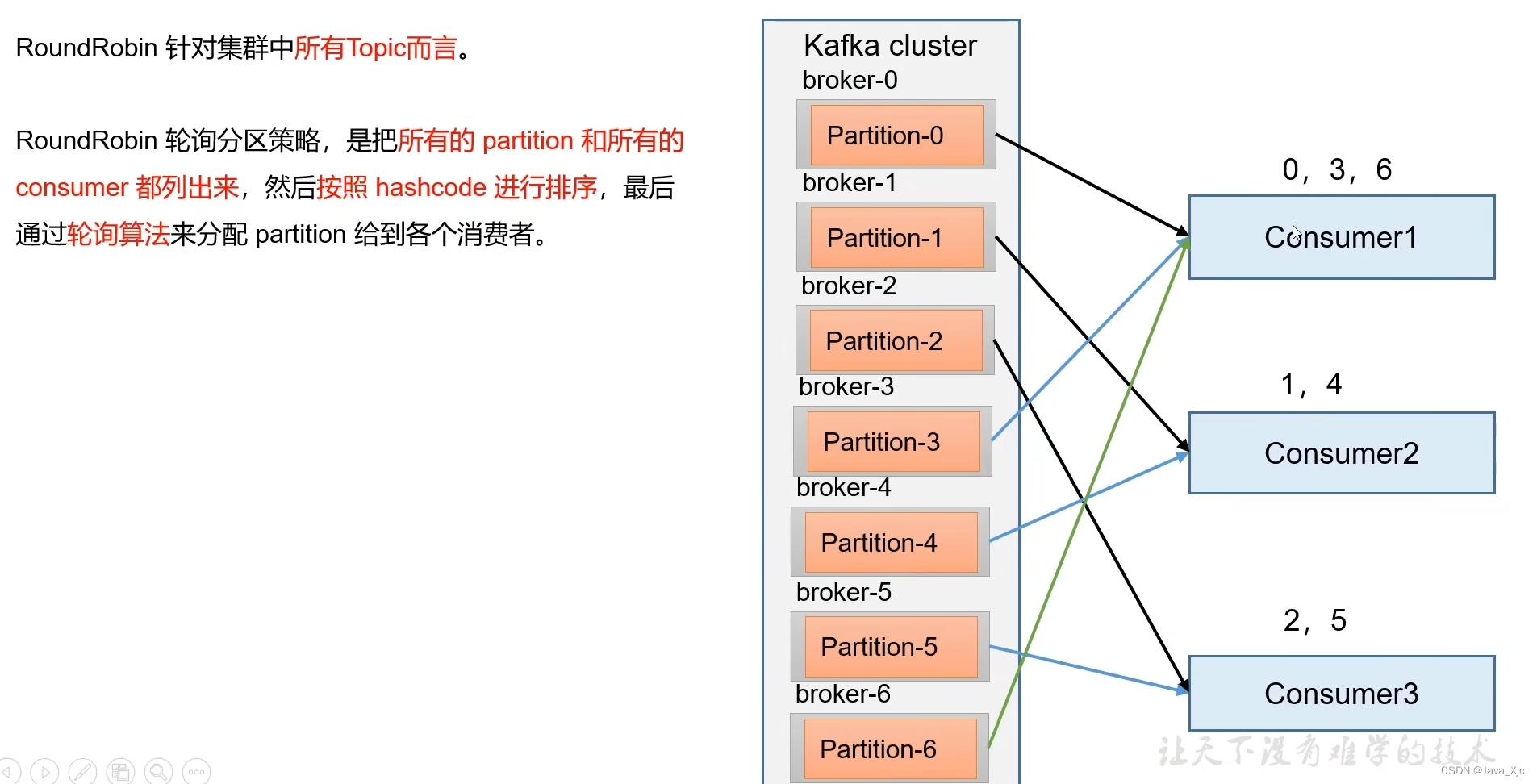
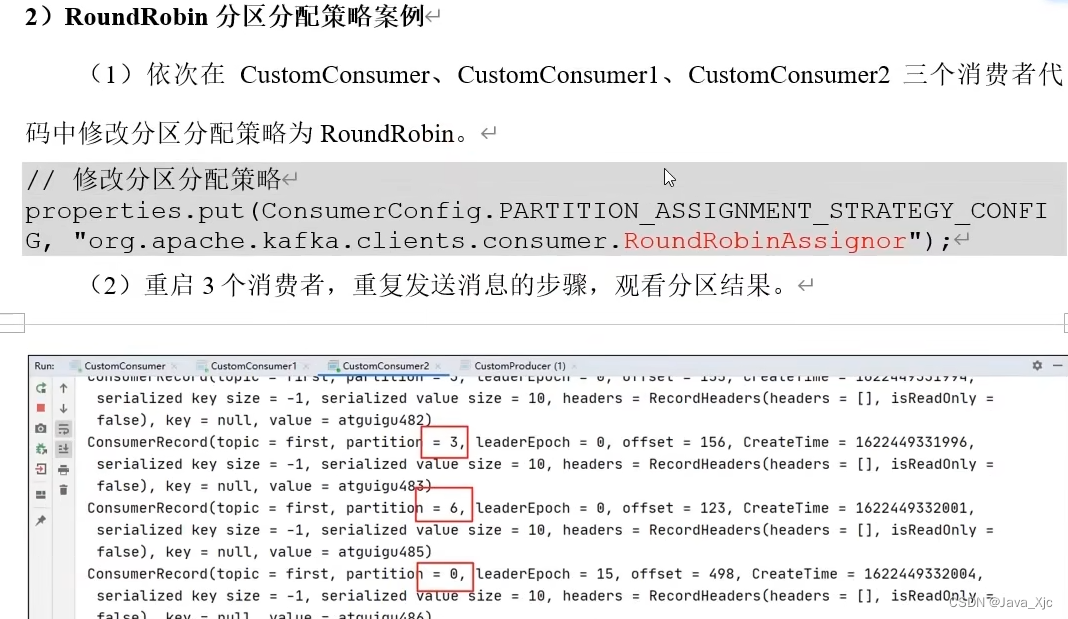
分区分配策略Roundrobin

分区分配策略Sticky以及再平衡


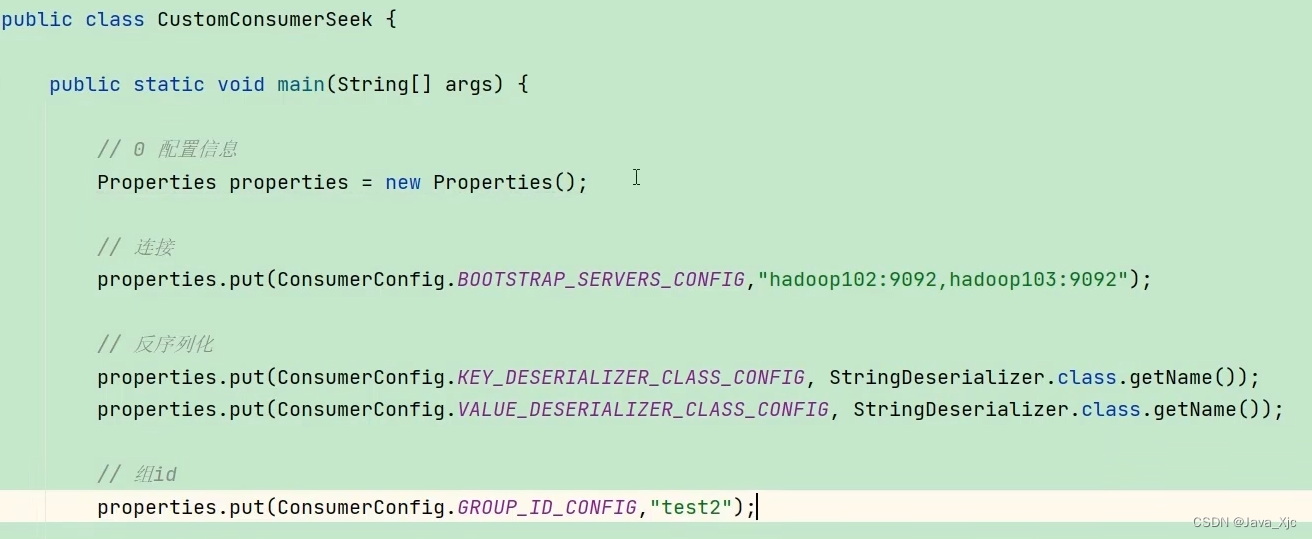
五、offest位移
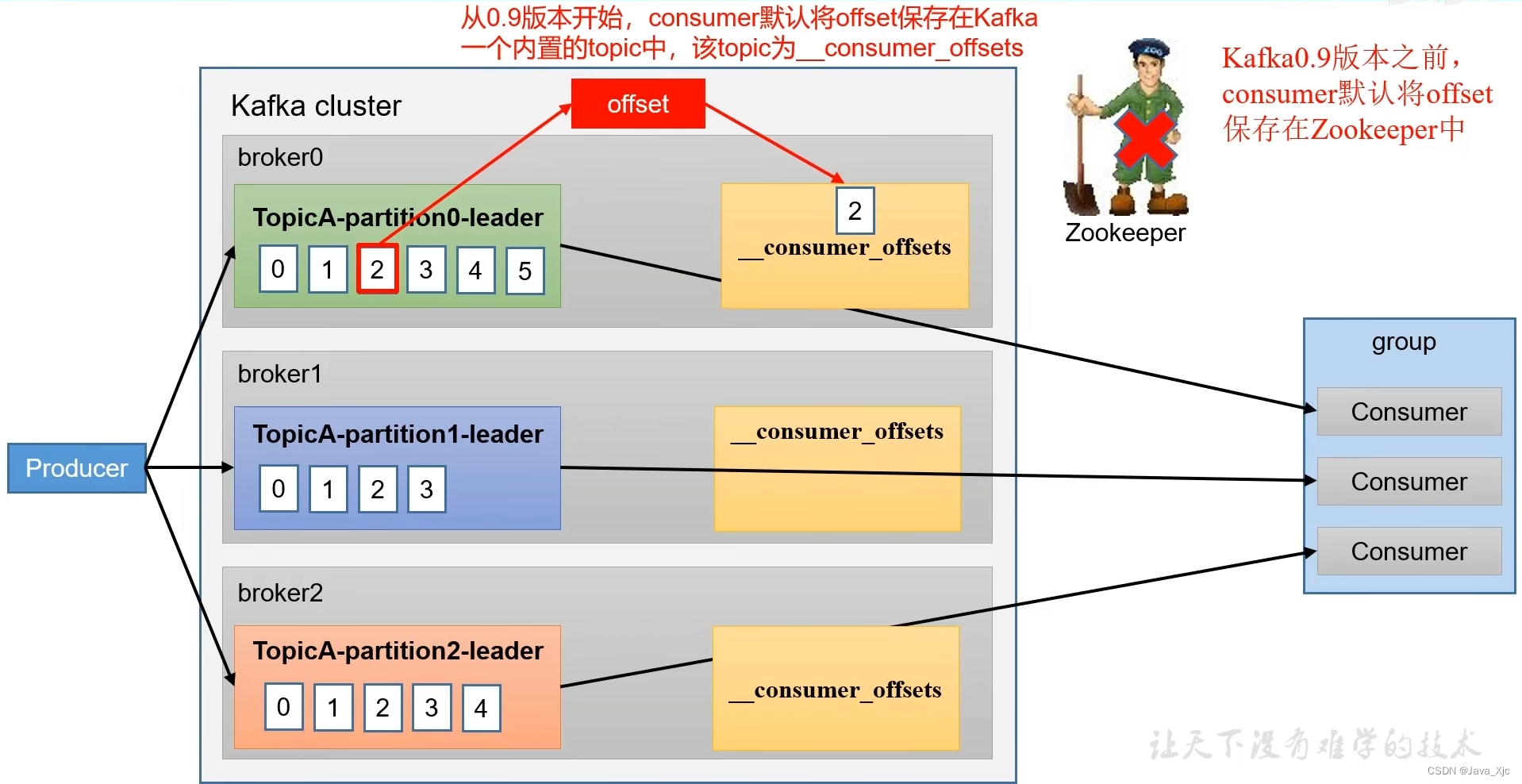
offest默认维护位置


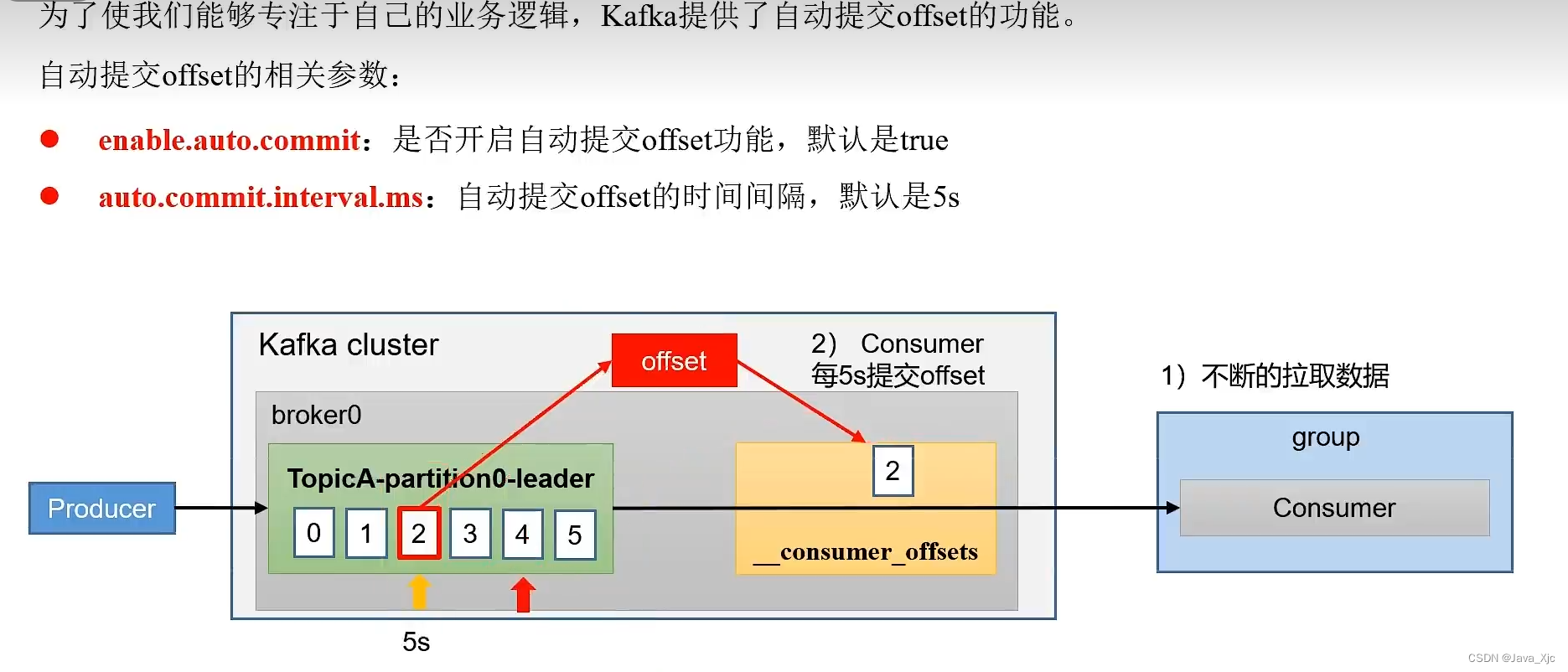
自动offset

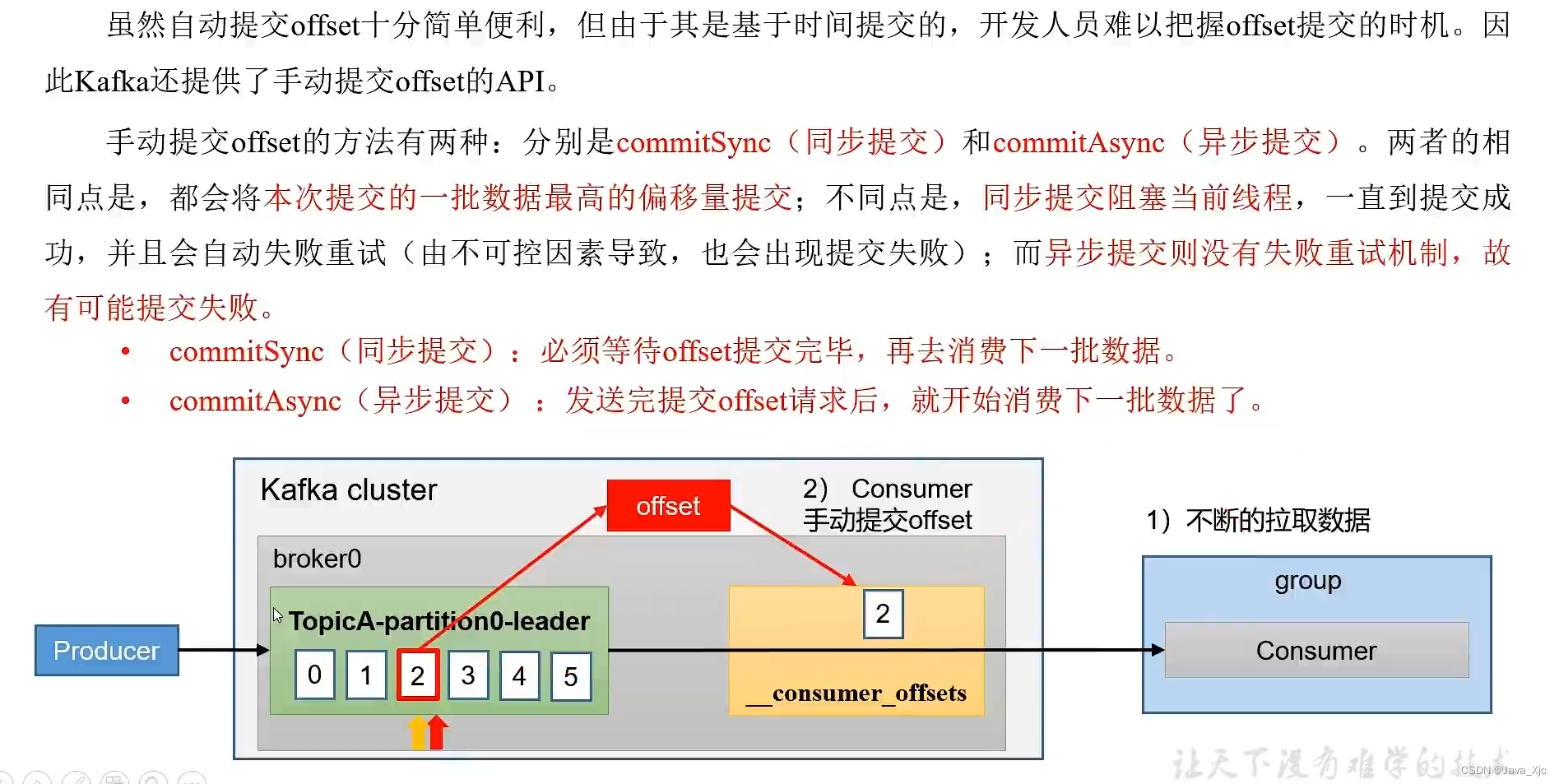
手动offset

指定offset

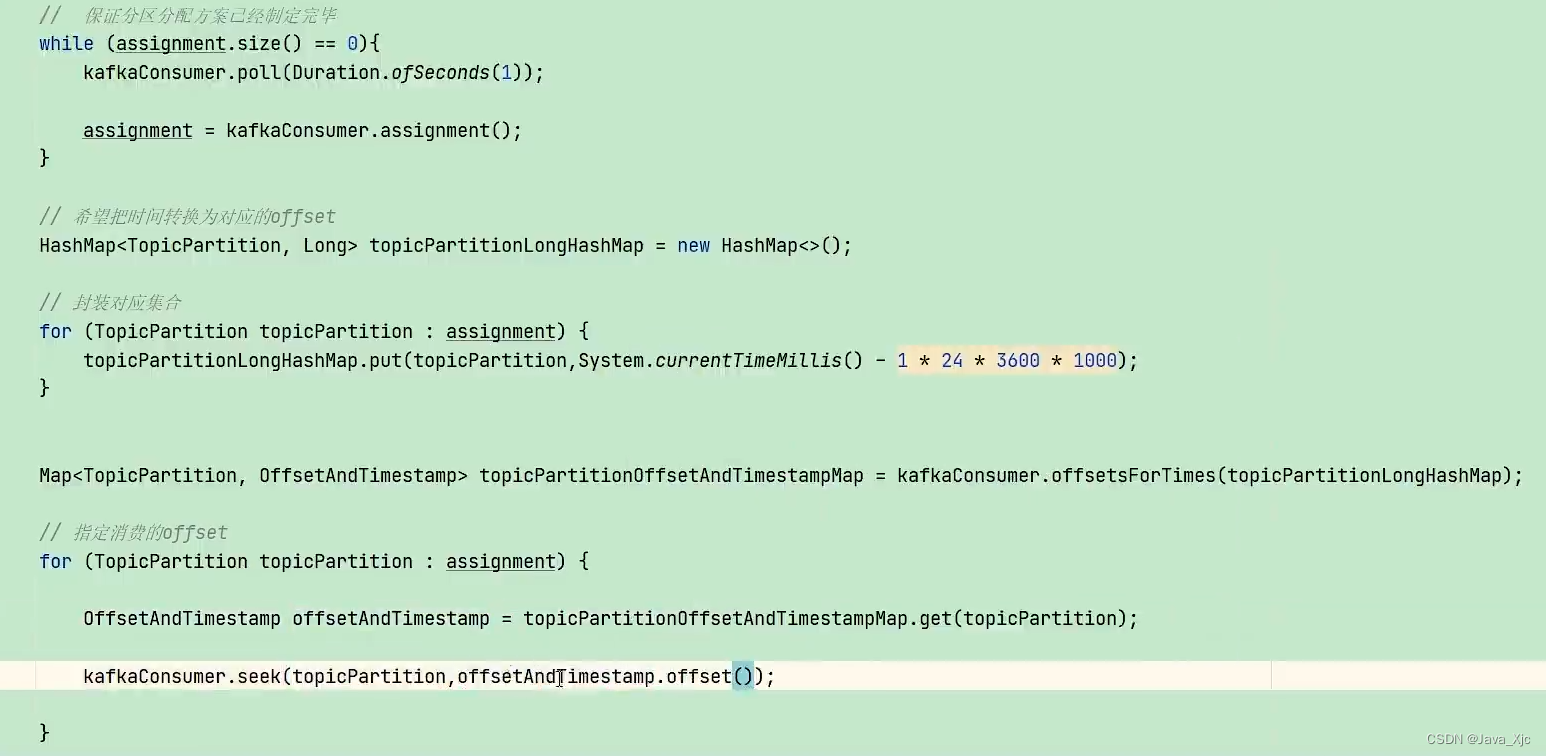
 还需要保证分区分配完成!
还需要保证分区分配完成!

六、按照指定时间消费

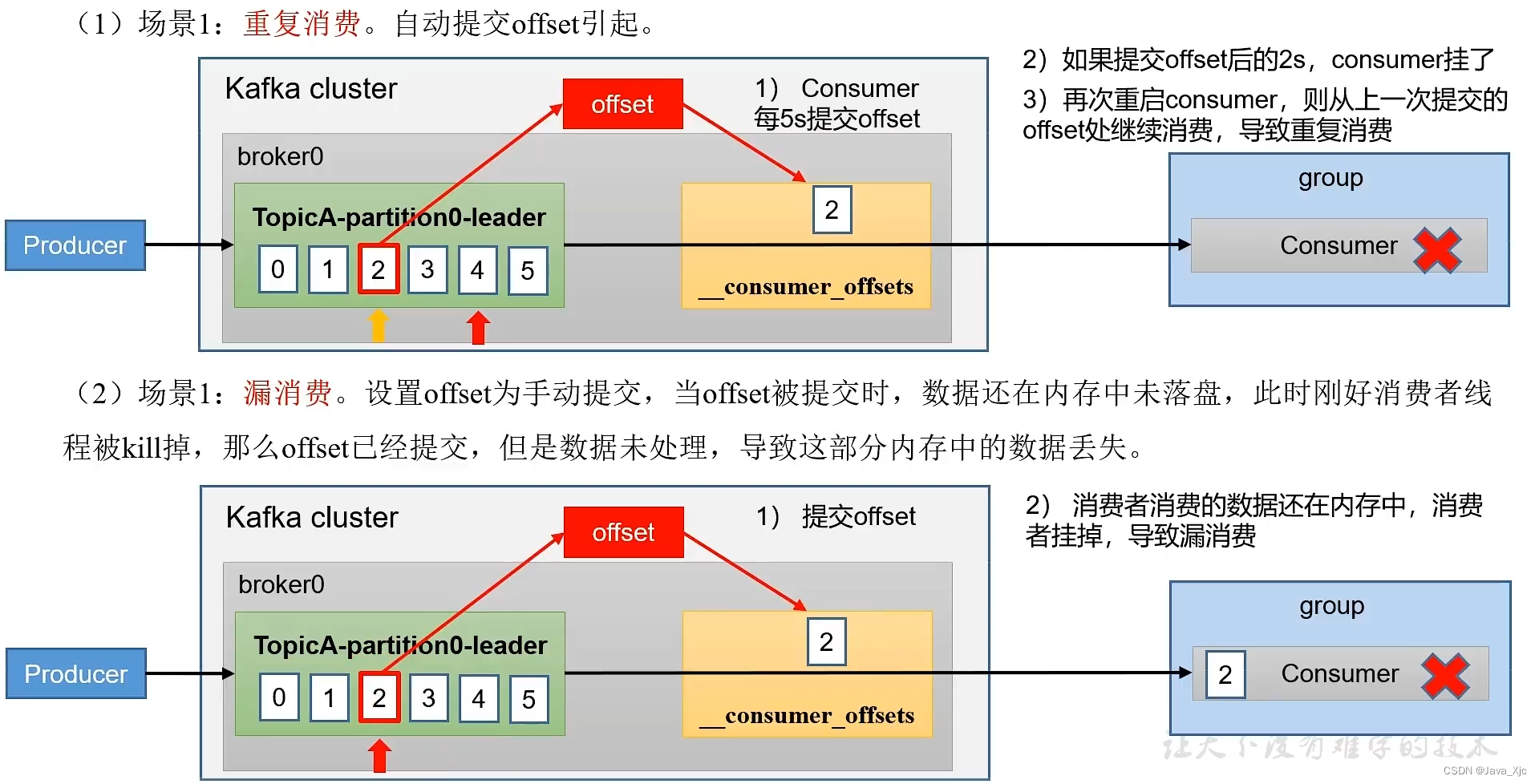
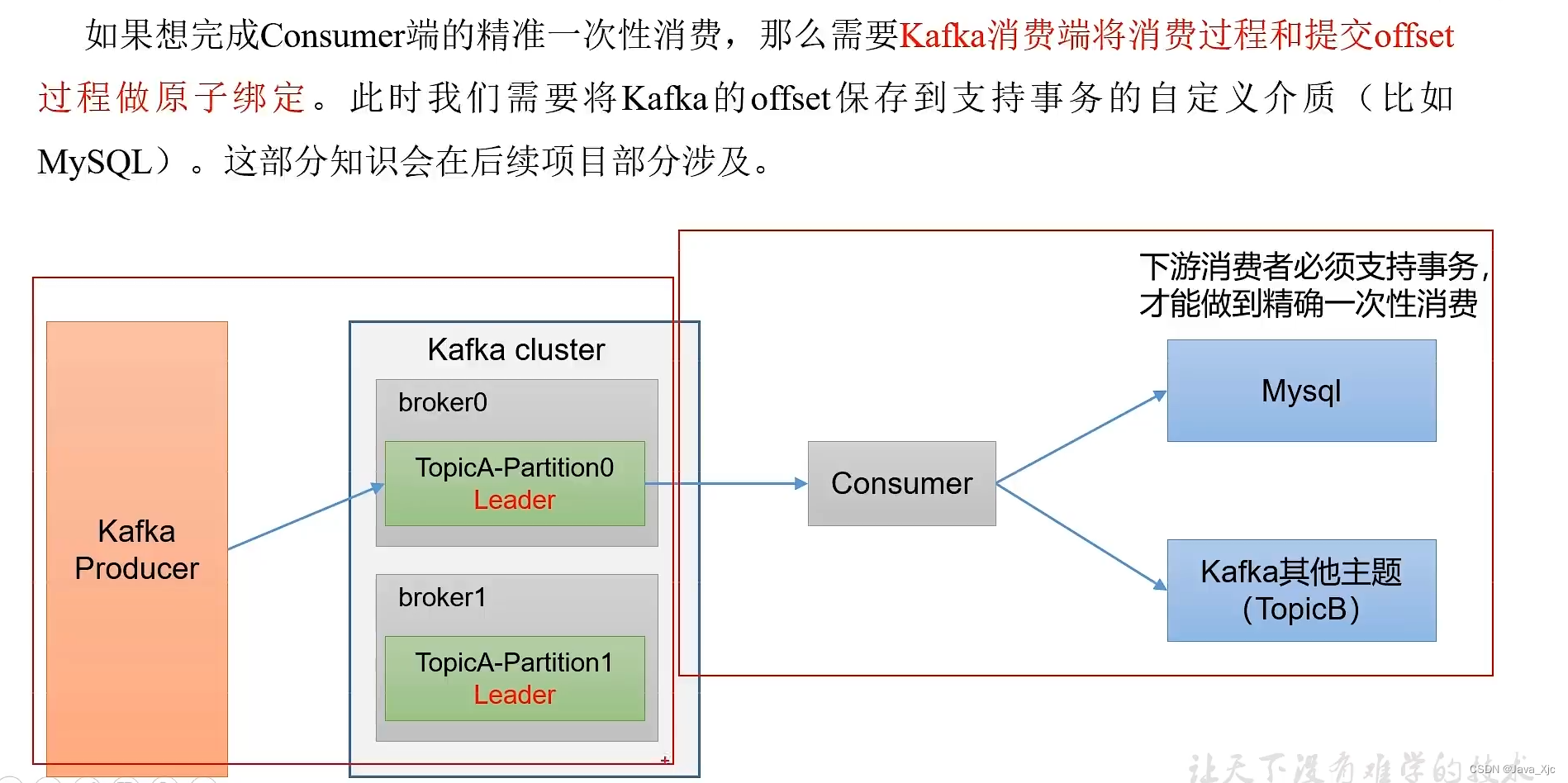
七、消费者事务

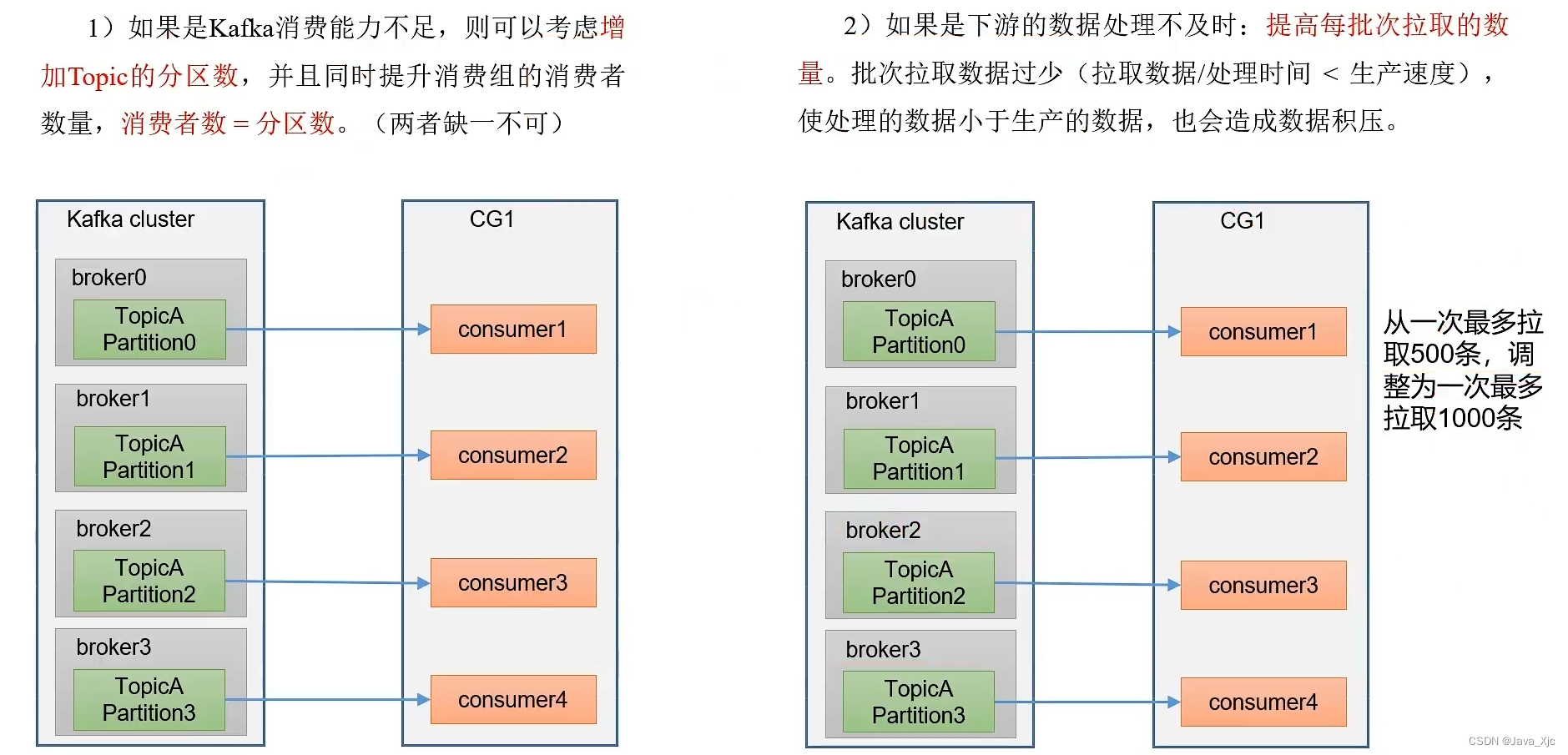
八、数据积压


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









