




 文章介绍了Redis中的Bitmap数据结构及其在签到统计中的应用,以及布隆过滤器的基本原理和使用,包括添加和查询数据的步骤。布隆过滤器用于高效判断集合中是否存在某个元素,虽存在误判但节省内存。文章还提供了手写布隆过滤器的简单架构及SpringBoot整合Redis和MyBatis的示例代码。
文章介绍了Redis中的Bitmap数据结构及其在签到统计中的应用,以及布隆过滤器的基本原理和使用,包括添加和查询数据的步骤。布隆过滤器用于高效判断集合中是否存在某个元素,虽存在误判但节省内存。文章还提供了手写布隆过滤器的简单架构及SpringBoot整合Redis和MyBatis的示例代码。
7.1 bitmap复习
1 是什么
- 由 0 和 1 状态表现得二进制位的 bit 数组
2 能干嘛
- 用于状态统计
- Y、N 类似 AutomicBoolean
- 需求
- 用户是否登录过Y、N,比如京东每日签到送京东
- 电影、广告是否被点击播放过
- 钉钉打卡上班,签到统计
3.京东签到领取京东
-
小厂方法,传统 mysql 方式
-
CREATE TABLE user_sign ( keyid BIGINT NOT NULL PRIMARY KEY AUTO_INCREMENT, user_key VARCHAR(200),#京东用户ID sign_date DATETIME,#签到日期(20210618) sign_count INT #连续签到天数 ) INSERT INTO user_sign(user_key,sign_date,sign_count) VALUES ('20210618-xxxx-xxxx-xxxx-xxxxxxxxxxxx','2020-06-18 15:11:12',1); SELECT sign_count FROM user_sign WHERE user_key = '20210618-xxxx-xxxx-xxxx-xxxxxxxxxxxx' AND sign_date BETWEEN '2020-06-17 00:00:00' AND '2020-06-18 23:59:59' ORDER BY sign_date DESC LIMIT 1; -
签到量用户小这个可以,如何解决这个点
-
一条签到记录对应一条记录,会占据越来越大的空间。
-
一个月最多31天,刚好我们的int类型是32位,那这样一个int类型就可以搞定一个月,32位大于31天,当天来了位是1没来就是0。
-
一条数据直接存储一个月的签到记录,不再是存储一天的签到记录。
-
-
-
大厂方法
-
基于redis的 Bitmap 实现签到日历
-
在签到统计时,每个用户一天的签到用1个bit位就能表示,
一个月(假设是31天)的签到情况用31个bit位就可以,一年的签到也只需要用365个bit位,根本不用太复杂的集合类型
-
-
4. 基本命令
SETBIT key offset value // 将第offset的值设为value value只能是0或1 offset 从0开始
GETBIT key offset // 获得第offset位的值
STRLEN key // 得出占多少字节 超过8位后自己按照8位一组一byte再扩容
BITCOUNT key // 得出该key里面含有几个1
BITOP and destKey key1 key2 // 对一个或多个 key 求逻辑并,并将结果保存到 destkey
BITOP or destKey key1 key2 // 对一个或多个 key 求逻辑或,并将结果保存到 destkey
BITOP XOR destKey key1 key2 // 对一个或多个 key 求逻辑异或,并将结果保存到 destkey
BITOP NOT destKey key1 key2 // 对一个或多个 key 求逻辑非,并将结果保存到 destkey
7.2布隆过滤器
1. 是什么
由一个初值都为零的bit数组和多个哈希函数构成,用来快速判断集合中是否存在某个元素
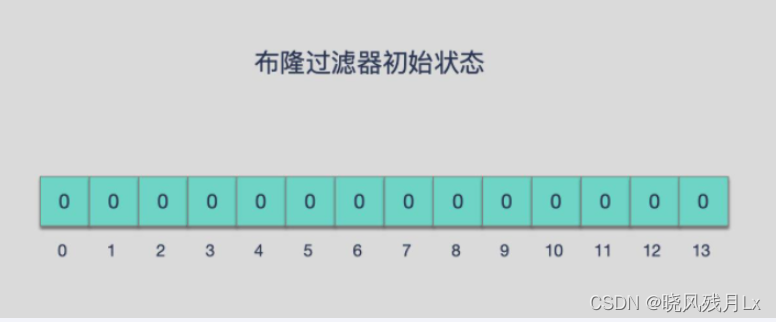
- 目的
- 减少内存占用
- 方式
- 不保存数据信息,只是在内存中做一个是否存在的标记flag
- 本质
- 判断具体数据是否村在于一个大的集合中
- 布隆过滤器是一种类似 set 的数据结构,只是统计结果在巨量数据下有点小瑕疵,不够完美
- 它实际上是一个很长的二进制数组(00000000)+一系列随机hash算法映射函数,主要用于判断一个元素是否在集合中。
- 通常我们会遇到很多要判断一个元素是否在某个集合中的业务场景,一般想到的是将集合中所有元素保存起来,然后通过比较确定。
- 链表、树、哈希表等等数据结构都是这种思路。但是随着集合中元素的增加,我们需要的存储空间也会呈现线性增长,最终达到瓶颈。同时检索速度也越来越慢,上述三种结构的检索时间复杂度分别为O(n),O(logn),O(1)。这个时候,布隆过滤器(Bloom Filter)就应运而生
2.能干嘛
- 高效地插入和查询,占用空间少,返回地结果是不确定性 + 不完美性
- 一个元素如果判断结果:存在时,元素不一定存在,不存在时,元素一定不存在
- 布隆过滤器可以添加元素,但是不能删除元素
- 涉及到hashcode判断依据,删掉元素会导致误判率增加
- 为什么不能删掉?
- 因为他是有多个 hash 函数,对一个值进行多次 hash 运算,将获得的每个值,在对应位置存 1 ,容易导致这个 1 也代表别的值,一旦删除,另一个值也无法通过
3.实现原理和数据结构
布隆过滤器(Bloom Filter) 是一种专门用来解决去重问题的高级数据结构。
实质就是一个大型位数组和几个不同的无偏hash函数(无偏表示分布均匀)。由一个初值为零地bit数组和多个哈希函数构成,用来快速判断某个数据是否存在。但是跟HyperLogLog一样,他也有一点不精确,存在一定的误判概率
-
添加 key 时
- 使用多个 hash 函数对key进行hash运算得到一个整数索引值,对位数组长度进行取模运算得到一个位置
- 每个 hash 函数都会得到一个不同的位置,将这几个位置都置 1 就完成了 add 操作
-
查询 key 时
- 只要有其中一位是零就表示这个key不存在,但如果都是1,则不一定存在对应的key
-
结论
- 有,可能有
- 无,肯定无
-
hash 冲突导致数据不精准1
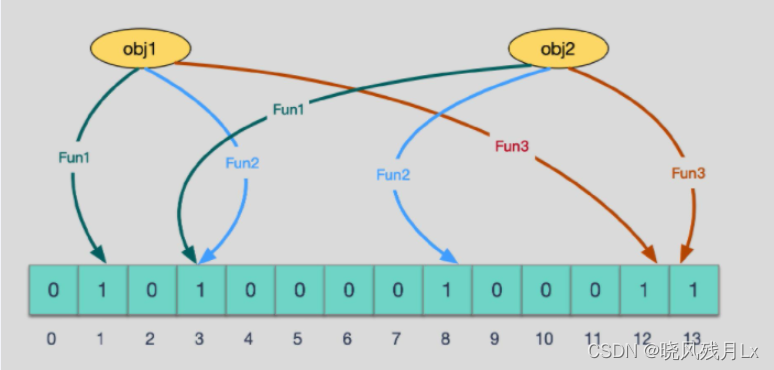
- 查询的时候看看这几个点是不是 1 ,就可以大概率直到集合中有没有它了,如果这些点,有任何一个为零则被查询变量一定不在,如果都是 1,则被查询变量很可能存在
- 正是基于布隆过滤器的快速检测特性,我们可以在把数据写入数据库时,使用布隆过滤器做个标记,当缓存缺失后,应用查询数据库时,可以通过查询布隆过滤器快速判断数据是否存在,如果不存在,就不用再去数据库中查询了。这样一来,即使发生了缓存穿透了,大量请求只会查询Redis和布隆过滤器,而不会积压到数据库,也就不会影响数据库的正常运行。布隆过滤器可以使用redis实现,本身就能承担较大的并发访问压力
-
hash 冲突导致数据不精准2
-
哈希函数的概念是:将任意大小的输入数据转换成特定大小的输出数据的函数,转换后的数据称为哈希值或哈希编码,也叫散列值
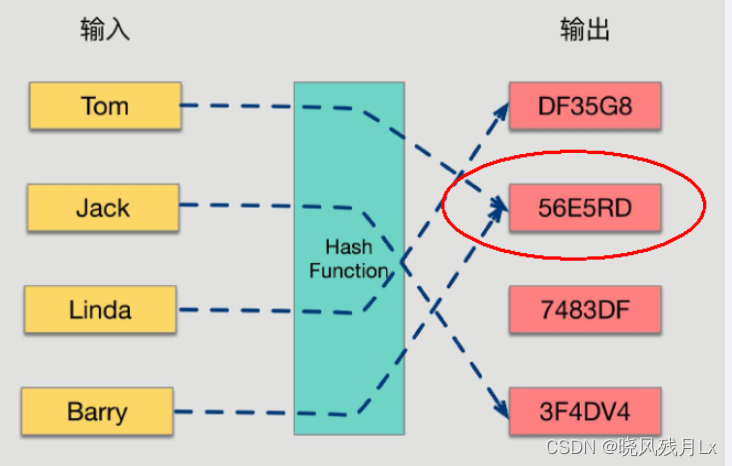
-
如果两个散列值是不相同的(根据同一函数)那么这两个散列值的原始输入也是不相同的。
-
这个特性是散列函数具有确定性的结果,具有这种性质的散列函数称为单向散列函数。
-
散列函数的输入和输出不是唯一对应关系的,如果两个散列值相同,两个输入值很可能是相同的,但也可能不同,这种情况称为“散列碰撞(collision)”
-
用 hash表存储大数据量时,空间效率还是很低,当只有一个 hash 函数时,还很容易发生哈希碰撞。
-
4.使用三步骤
- 本质上 是由长度为m 的位向量或位列表 (仅包含 0 或 1 位值的列表)组成,最初所有的值均设置为 0

-
添加数据,为了尽量地址不冲突,使用多个hash函数对key进行运算,算得一个下标索引值,然后对数据长度进行取模运算得到一个位置,每个 hash 函数都会算得一个不同的位置。再把位数组的这几个位置都置为 1 就完成了 add 操作。
对字符串进行多次hash(key) → 取模运行→ 得到坑位
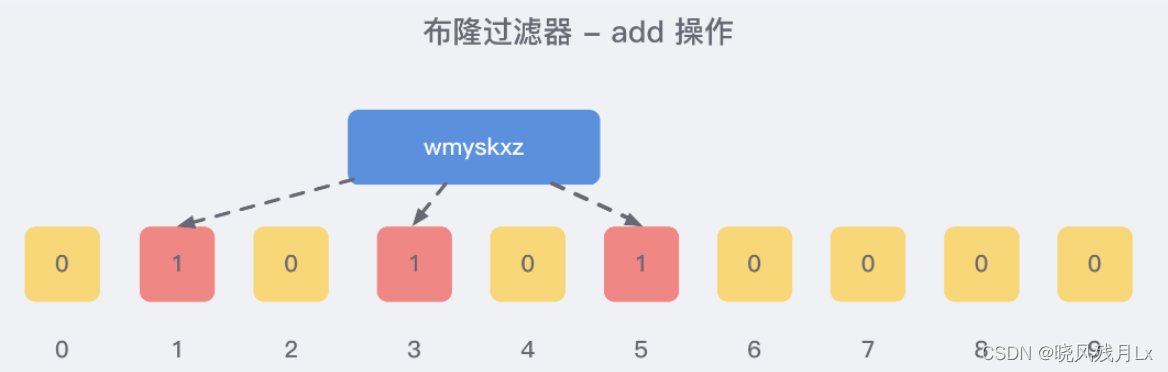
-
向布隆过滤器查询某个key是否存在时,先把这个 key 通过相同的多个 hash 函数进行运算,查看对应的位置是否都为 1,只要有一个位为零,那么说明布隆过滤器中这个 key 不存在;如果这几个位置全都是 1,那么说明极有可能存在;
- 总结
- 是否存在
- 有,可能有
- 无,肯定无
- 使用是最好不要让实际元素数量远大于初始化数量,一次给够避免扩容
- 当实际元素数量超过初始化数量,应该对布隆过滤器进行重建,重新分配一个size 更大的过滤器,再将所有的历史元素批量add
- 是否存在
5.尝试手写简单的布隆过滤器,结合bitmap
1.整体架构
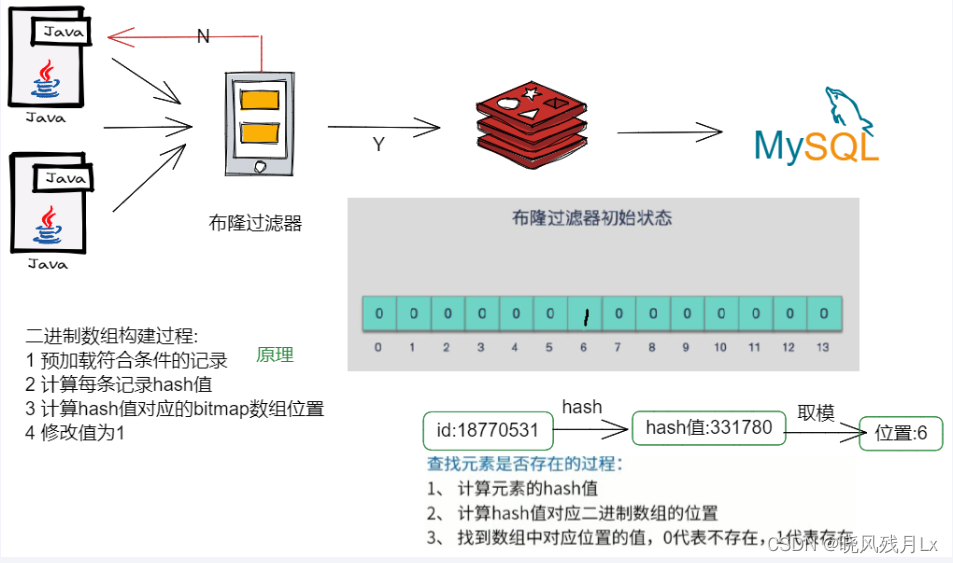
2.步骤设计
- setBit的构建过程
- @PostConstruct 初始化白名单数据
- 计算元素hash值
- 得到hash值算出对应的二进制数组的坑位
- 将对应坑位的值修改为数字1,表示存在
- getBit查询是否存在
- 计算元素hash值
- 得到hash值算出对应的二进制数组的坑位
- 返回对应坑位的值,0表示无,1表示存在
3 springboot + redis + mybatis+布隆过滤器 整合
-
使用Mapper4自动生成
-
先创建 mybatis-generator 工程
-
建表sql
CREATE TABLE `t_customer` ( `id` int(20) NOT NULL AUTO_INCREMENT, `cname` varchar(50) NOT NULL, `age` int(10) NOT NULL, `phone` varchar(20) NOT NULL, `sex` tinyint(4) NOT NULL, `birth` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP, PRIMARY KEY (`id`), KEY `idx_cname` (`cname`) ) ENGINE=InnoDB AUTO_INCREMENT=10 DEFAULT CHARSET=utf8mb4 -
pom
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>com.xfcy</groupId> <artifactId>mybatis_generator</artifactId> <version>1.0-SNAPSHOT</version> <parent> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-parent</artifactId> <version>2.6.10</version> <relativePath/> </parent> <properties> <!-- 依赖版本号 --> <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding> <maven.compiler.source>1.8</maven.compiler.source> <maven.compiler.target>1.8</maven.compiler.target> <java.version>1.8</java.version> <hutool.version>5.5.8</hutool.version> <druid.version>1.1.18</druid.version> <mapper.version>4.1.5</mapper.version> <pagehelper.version>5.1.4</pagehelper.version> <mysql.version>5.1.39</mysql.version> <swagger2.version>2.9.2</swagger2.version> <swagger-ui.version>2.9.2</swagger-ui.version> <mybatis.spring.version>2.1.3</mybatis.spring.version> </properties> <dependencies> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> </dependency> <!--Mybatis 通用mapper tk单独使用,自己带着版本号--> <dependency> <groupId>org.mybatis</groupId> <artifactId>mybatis</artifactId> <version>3.4.6</version> </dependency> <!--mybatis-spring--> <dependency> <groupId>org.mybatis.spring.boot</groupId> <artifactId>mybatis-spring-boot-starter</artifactId> <version>${ mybatis.spring.version}</version> </dependency> <!-- Mybatis Generator --> <dependency> <groupId>org.mybatis.generator</groupId> <artifactId>mybatis-generator-core</artifactId> <version>1.4.0</version> <scope>compile</scope> <optional>true</optional> </dependency> <!
-
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1770
1770

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











