







1.实验目的
掌握二叉树的生成、遍历等操作,及哈夫曼编码/译码的原理。
2.实验要求
输入:通过命令行参数输入字符串(长度>=20)和码字。
输出: (1)命令行参数不正确输出ERROR_01;
(2)编码失败输出ERROR_02;
(3)译码失败输出ERROR_03;
(4)在同一行中输出编码结果和译码结果,中间使用空格隔开。
简明实例:
输入:“stupid is as stupid does” “101101001110”
输出:“001110111110111000111101000011001000011000
1110111110111000111100111010010100 pat”
其他要求:
- 基于该哈夫曼树,实现非递归的先序遍历算法,输出该树所有的节点、节点的权值、节点的度和节点所在的层数;
- 在实现时要求哈夫曼树的左右孩子的大小关系满足,左孩子节点权值小于右孩子节点权值,若左右孩子权值相等,按字母顺序排列(序号小的字母在左孩子)。
代码质量要求:
1、优选C语言,禁止直接调用C++ STL库;
2、除循环变量外,其它变量命名使用有明确含义的单词或缩写,不建议使用拼音;
3、禁止出现魔鬼数字; 4、添加必要的程序注释;
5、统一代码格式,例如:{}和空行; 6、变量初始化,不要依赖默认赋值;
7、入参检查,“外部输入输入不可靠”,指针判空(一级指针、二级指针……),循环变量上下限;
8、malloc与free配对; 9、尽量少用全局变量;
10、编译错误解决,从前往后处理,提示出错的行不一定是错误的根因。
3.实验原理
霍夫曼编码原理
1)将信源符号的概率按减小的顺序排队。
2)把两个最小的概率相加,并继续这一步骤,始终将较高的概率分支放在右边,直到最后变成概率1。
3)画出由概率1处到每个信源符号的路径,顺序记下沿路径的0和1,所得就是该符号的霍夫曼码字。
4)将每对组合的左边一个指定为0,右边一个指定为1(或相反)。
树的遍历原理
- 递归遍历
先访问根节点,再访问左孩子节点,最后访问右孩子结点
- 访问根节点时直接调用visit函数
- 访问左孩子节点的时候先将根节点压进栈中,再访问左孩子结点。
- 当左孩子结点完全访问完了之后,取栈顶元素,访问右孩子结点。
- 对于1,2,3步进行循环,直到栈空终止循环。
解码原理:
<循环开始:条件为输入01串未被遍历完>
创建指针指向根节点,当为0时向左,当为1时向右。
当找到内容时将指针重置为根节点。
<循环终止>
ERROR_03的处理:
和解码过程相配合,当出现最终的一位不在叶子节点上的时候,认为解码失败
ERROR_02的处理:
当全部为abcdefg……时,即所有的出现过的字符权重均为1时,
或者当输入的小于二十时
认为出现错误ERROR_02
ERROR_01的判定
针对输入的aggc进行判断,当其为2时,认为入参正确,不做响应。
当其不为2时,认为入参出现问题,返回ERROR_01。
4.实验结果
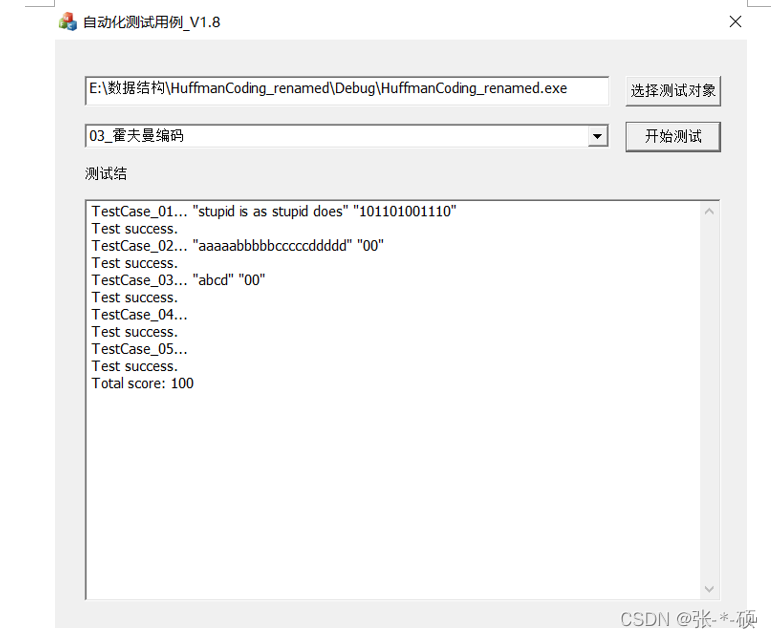
5.问题与思考
问题:
本次虽然较好的解决了霍夫曼编码的逻辑和代码,但是存在代码过长的问题。
同时,由于代码过长的问题,整体的构架不好观察和分析。
解决办法:
- 学习使用Cpp,使用面向对象的编程语言,将函数进行封装,便于调用和分析
- 将部分函数部分拆出来一个完整的头文件,或者直接拆成两个文件,便于之后的调用。
#include<stdio.h>
#include<malloc.h>
#include<string.h>
#define SElemType char
#define Status int
#define OK 2
#define TRUE 1
#define change 1//用于存放带权节点结构体的空间分配转换
#define both 3
#define left 1
#define right 2
#define FALSE 0
#define ERROR -1
#define OVERFLOW -2
#define ERROR_01 -3
#define ERROR_02 -4
#define ERROR_03 -5
#define InitSize 100
#define IncreaseSize 10
/*-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+定义存放带权节点并计算节点权值 -+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+*/
typedef struct NamePlusTimes
{
char* node;//用于存放出现过的字符
int* weight;//用预存方字符的权值
int Total_len;//用于存放总的路径长度
}Node_Weight;//定义存储节点和其带权路径长度的结构体
int IfInNodeList(char elem, Node_Weight* Cur_Node_Weight)
{
if (!Cur_Node_Weight) return ERROR;
int i = 1;
while (i <= Cur_Node_Weight->Total_len)
{
if (elem == Cur_Node_Weight->node[i - change]) return i;
if (i == Cur_Node_Weight->Total_len) return FALSE;
i++;
}
return FALSE;
}//判断当前的字符是否在带权节点结构题串里边里边,如果在,返回位置(角标+1),如果不在,FAlse。
Status PutInNodeList(char elem, Node_Weight* Cur_Node_Weight)
{
if (!Cur_Node_Weight) return ERROR;
//鲁棒性检测
Cur_Node_Weight->node = (char*)realloc(Cur_Node_Weight->node, (change + Cur_Node_Weight->Total_len++) * sizeof(char));
Cur_Node_Weight->weight = (int*)realloc(Cur_Node_Weight->weight, (change + Cur_Node_Weight->Total_len) * sizeof(int));
//动态扩张一位存放元素,总长度顺便加1
if (!Cur_Node_Weight->node) return OVERFLOW;
if (!Cur_Node_Weight->weight) return OVERFLOW;
//鲁棒性检测
Cur_Node_Weight->node[Cur_Node_Weight->Total_len - change] = elem;
Cur_Node_Weight->weight[Cur_Node_Weight->Total_len - change] = 0;
Cur_Node_Weight->node[Cur_Node_Weight->Total_len] = '\0';
return OK;
}//将元素elem放入Cur_Node_Weight之中,使用realloc实现可变长的分配。只实现存放进去,不实现计数
Status InitNode_Weight(Node_Weight* Cur_Node_Weight)
{
if (!Cur_Node_Weight) return ERROR;
Cur_Node_Weight->node = NULL;
Cur_Node_Weight->weight = NULL;
Cur_Node_Weight->Total_len = 0;
return OK;
}//生成一个Node_Weight结构体。其中node,weight均为空,用一位分配一位,适用于可变长的。
Status AddWeight(int Index, Node_Weight* Cur_Node_Weight)
{
if (!Cur_Node_Weight) return ERROR;
Cur_Node_Weight->weight[Index]++;
return OK;
}//对对应位置的权值加加
Status CreateNode_Weight(char** argv, Node_Weight* Cur_Node_Weight)
{
if (!Cur_Node_Weight) return ERROR;
InitNode_Weight(Cur_Node_Weight);//初始化
int FlagLength = strlen(argv[1]);//总循环的次数
int i = 0;
while (i < FlagLength)
{
if (!IfInNodeList(argv[1][i], Cur_Node_Weight))
{
PutInNodeList(argv[1][i], Cur_Node_Weight);//如果没在,就把他扔进去生成一个新的节点
}
i++;
}//把所有元素扔进节点中去.
i = 0;
while (i < FlagLength)
{
if (IfInNodeList(argv[1][i], Cur_Node_Weight)) AddWeight(IfInNodeList(argv[1][i], Cur_Node_Weight) - change, Cur_Node_Weight);
//如果在,那么对应位置+1
i++;
}
return OK;
}//生成节点及其带权长度,用于之后huffmantree的生成。
Status IfError_01(int input)
{
if (input == 3) return FALSE;
else
{
printf("ERROR_01");
return TRUE;
}
}//判断是不是出现了错误1
/*-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+定义数并进行霍夫曼树的生成 -+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+*/
typedef struct OTHERINFO
{
int index;//结点序号
int weight;//权重
int parent;//父节点
int lchild;//左孩子
int rchild;//右孩子
int du;//度
int plies;//层数
}otherinfo;
typedef struct BETREE
{
char name;
int weight;
struct BETREE* parent;
struct BETREE* lchild;
struct BETREE* rchild;
Status Visited;
otherinfo info;
}BetreeNode;//用于构建霍夫曼树的节点。
typedef struct ROW_BETREE_LIST
{
int Len;
BetreeNode* nodelist;//树节点列表,为指针列表
int* visited;
}RowBetreeList;//用于存放生节点们的串串,生节点指child和parent未定义的。
Status InitRowBetreeList(RowBetreeList* RowTreeList, Node_Weight* Cur_Node_Weight)
{
if (!RowTreeList) return ERROR;
int LENGTH = IncreaseSize + (Cur_Node_Weight->Total_len + 1) * Cur_Node_Weight->Total_len / 2;
RowTreeList->Len = Cur_Node_Weight->Total_len;
RowTreeList->nodelist = (BetreeNode*)malloc(LENGTH * sizeof(BetreeNode));
if (!RowTreeList->nodelist) return OVERFLOW;
RowTreeList->visited = (int*)malloc(LENGTH * sizeof(Status));
if (!RowTreeList->visited) return OVERFLOW;
return OK;
}//对存放生节点的串串进行初始化,用于存放生节点,生节点指child和parent未定义的。
Status InitRowBetreeNode(BetreeNode* target, char name, int weight, BetreeNode* parent, BetreeNode* lchild, BetreeNode* rchild)
{
if (!target) return ERROR;
target->name = name;
target->weight = weight;
target->parent = parent;
target->rchild = rchild;
target->lchild = lchild;
target->Visited = FALSE;//第一遍生成的时候所有节点固定标记为未访问的。
return OK;
}//对生节点进行初始化,生节点指child和parent未定义的。
Status Create_RowBetreeList(RowBetreeList* RowTreeList, Node_Weight* Cur_Node_Weight)
{
if (!RowTreeList || !Cur_Node_Weight) return ERROR;
InitRowBetreeList(RowTreeList, Cur_Node_Weight);
int i = 0;
while (i < Cur_Node_Weight->Total_len)
{
InitRowBetreeNode(&RowTreeList->nodelist[i], Cur_Node_Weight->node[i], Cur_Node_Weight->weight[i], NULL, NULL, NULL);
RowTreeList->visited[i] = FALSE;
i++;
}
return OK;
}//将所有的生节点存进生节点列表中去。
Status Create_Added_BeTree_Node(RowBetreeList* RowTreeList, int lchild, int rchild, int index)
{
if (!RowTreeList) return ERROR;
int weight = (RowTreeList->nodelist[lchild]).weight + RowTreeList->nodelist[rchild].weight;
RowTreeList->Len++;
InitRowBetreeNode(&RowTreeList->nodelist[(RowTreeList->Len) - change], '~', weight, NULL, &RowTreeList->nodelist[lchild], &RowTreeList->nodelist[rchild]);
RowTreeList->nodelist[lchild].parent = &RowTreeList->nodelist[(RowTreeList->Len) - change];
RowTreeList->nodelist[rchild].parent = &RowTreeList->nodelist[(RowTreeList->Len) - change];
RowTreeList->visited[lchild] = TRUE;
RowTreeList->nodelist[lchild].info.index = index;
RowTreeList->visited[rchild] = TRUE;
RowTreeList->nodelist[rchild].info.index = index + change;
RowTreeList->visited[RowTreeList->Len - change] = FALSE;
}//将第lchild和第rchild位进行处理,构造成一个小树,然后把这个小树扔进生节点列表里
int Not_Visited_amount(RowBetreeList* RowTreeList)
{
int count = 0;
int i = 0;
while (i < RowTreeList->Len)
{
if (RowTreeList->visited[i] == FALSE) count++;
i++;
}
return count;
}//对RowTreeList之中没有被访问的总长度进行计数并返回
int Find_lchild(RowBetreeList* RowTreeList)//左边小
{
int i = 0;
int lchild;
int flag = TRUE;
while (i < RowTreeList->Len)
{
if (RowTreeList->visited[i] == FALSE)
{
if (flag)
{
lchild = i;
flag = FALSE;
}//判断是不是第一次未被访问
else
{
if (RowTreeList->nodelist[i].weight <= RowTreeList->nodelist[lchild].weight)
{
if (RowTreeList->nodelist[i].weight < RowTreeList->nodelist[lchild].weight) lchild = i;//权重小则直接修改
else
{
if (RowTreeList->nodelist[i].name < RowTreeList->nodelist[lchild].name) lchild = i;//权重相等要比较一下字典序
}
}
}
}
i++;
}
return lchild;
}//返回左孩子节点
int Find_rchild(RowBetreeList* RowTreeList, int* lchild)
{
int i = 0;
int rchild;
int flag = TRUE;
while (i < RowTreeList->Len)
{
if (RowTreeList->visited[i] == FALSE && ((i) != *lchild))
{
if (flag && ((i) != *lchild))
{
rchild = i;
flag = FALSE;
}//判断是不是第一次未被访问
else
{
if ((RowTreeList->nodelist[i].weight <= RowTreeList->nodelist[rchild].weight) && i != *lchild)//防止lchild被访问两边导致树节点被生成了两边
{
if (RowTreeList->nodelist[i].weight < RowTreeList->nodelist[rchild].weight) rchild = i;//权重小直接修改
else
{
if (RowTreeList->nodelist[i].name < RowTreeList->nodelist[rchild].name) rchild = i;//全重大要比较一下字典序
}
}
}
}
i++;
}
return rchild;
}//寻找右孩子结点的下标。
Status Create_Huffman_Tree(RowBetreeList* RowTreeList, Node_Weight* Cur_Node_Weight)
{
Create_RowBetreeList(RowTreeList, Cur_Node_Weight);
int rchild;
int lchild;
int i = 1;
while (Not_Visited_amount(RowTreeList) > change)
{
lchild = Find_lchild(RowTreeList);
rchild = Find_rchild(RowTreeList, &lchild);
Create_Added_BeTree_Node(RowTreeList, lchild, rchild, i);
i += 2;
}
RowTreeList->nodelist[RowTreeList->Len - change].info.index = i;
return OK;
}//生成霍夫曼树,并将其头结点放在RowTreeList的最后一位,即角标为Cur_Node_Weight->Total_len-1的位置
Status If_Error_02(Node_Weight* Cur_Node_Weight)
{
if (!(Cur_Node_Weight)) return ERROR;
if (Cur_Node_Weight->Total_len <= 1)
{
printf("ERROR_02");
return TRUE;
}
int flag = TRUE;
int i = 0;
while (i < Cur_Node_Weight->Total_len)
{
if (Cur_Node_Weight->weight[i] != 1)
{
flag = FALSE;
}
i++;
}
if (flag)
{
printf("ERROR_02");
return TRUE;
}
return FALSE;
}//判断有没有输入,输入的是不是只有一个。
/*-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-进行遍历并且生成编码所对应的广义表 -+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+*/
typedef struct otherINFOLIST
{
int len;
otherinfo* info;
int maxsize;
}infolist;//存放的列表
Status InitInfoList(infolist* infos, RowBetreeList* RowTreeList)
{
if (!infos || !RowTreeList) return ERROR;
infos->maxsize = RowTreeList->Len;
infos->len = 0;
infos->info = (otherinfo*)malloc(infos->maxsize * sizeof(otherinfo));
return OK;
}//初始化列表
Status IfNotLeaf(BetreeNode* cursor)
{
if (!cursor) return ERROR;
if (cursor->lchild && cursor->rchild) return both;
if (cursor->lchild && (!cursor->rchild)) return left;
if ((!cursor->lchild) && (cursor->rchild)) return right;
if ((!cursor->lchild) && (!cursor->rchild)) return FALSE;
return ERROR;
}//判断其出度为几,由左节点还是右节点占据。
Status InputInfoList(infolist* infos, BetreeNode* node)
{
if (!infos || !node) return ERROR;
infos->len++;
switch (IfNotLeaf(node))
{
case both:infos->info[infos->len - change].du = 2; break;
case left:infos->info[infos->len - change].du = 1; break;
case right:infos->info[infos->len - change].du = 1; break;
default:infos->info[infos->len - change].du = 0; break;
}//对度进行初始化
infos->info[infos->len - change].index = node->info.index;
if (node->lchild)
{
infos->info[infos->len - change].lchild = node->lchild->info.index;
}
else infos->info[infos->len - change].lchild = 0;
if (node->rchild)
{
infos->info[infos->len - change].rchild = node->rchild->info.index;
}
else infos->info[infos->len - change].rchild = 0;
infos->info[infos->len - change].plies = node->info.plies;
if (node->parent)
{
infos->info[infos->len - change].parent = node->parent->info.index;
}
else infos->info[infos->len - change].parent = 0;
infos->info[infos->len - change].weight = node->weight;
return OK;
}//将该存的节点信息存进列表中
typedef struct CODENODE
{
int len;
char* CodeBase;//用于存放编码串的基址
char name;
}CodeNode;//定义存放一个字符编码的存储结构
typedef struct CODELIST
{
CodeNode* ListBase;//用于存放编码节点们
int len;
}CodeList;//存放结果的广义表。
Status InitCoedList(int max_size, struct CODELIST* target)
{
if (!target) return ERROR;
target->ListBase = (CodeNode*)malloc(max_size * sizeof(CodeNode));
if (!target->ListBase) return OVERFLOW;
target->len = 0;
return OK;
}//初始化广义表.
Status InitTempNode(CodeNode* target, int max_size)
{
if (!target) return ERROR;
target->CodeBase = (char*)malloc((max_size + change) * sizeof(char));
if (!target->CodeBase) return OVERFLOW;
return OK;
}//只对其进行分配内部地址,其长度和名称是随变的,最后要复制到广义表里边去。这里不强行分配。
Status IfRchildAccessb(BetreeNode* cursor)
{
if (!cursor) return ERROR;
if (cursor->rchild)
{
if (!cursor->rchild->Visited) return TRUE;//当右侧非空或者未被访问时,返回,TRUE(可访问的)。
else return FALSE;//反之返回FALSE,认为不可访问。
}
else return FALSE;//反之返回FALSE,认为不可访问。
}//判断右侧是否可以被访问。
Status cpy(char* output, char* input)
{
if (!output || !input) return ERROR;
int i = 0;
int maxSIZE = strlen(input);
while (i < maxSIZE)
{
output[i] = input[i];//进行顺序复制
i++;
}
return OK;
}
Status nodecopy(CodeNode* result, CodeNode* temp)
{
if (!result || !temp) return ERROR;
result->CodeBase = (char*)malloc((strlen(temp->CodeBase) + change) * sizeof(char));
if (!result->CodeBase) return OVERFLOW;
cpy(result->CodeBase, temp->CodeBase);//调用赋值函数
result->CodeBase[strlen(temp->CodeBase)] = '\0';
result->len = temp->len;
result->name = temp->name;
return OK;
}//将东西进行誊写,因为不能直接想等。
Status CreateCodeList(CodeList* MyCodeList, RowBetreeList* RowTreeList, Node_Weight* Cur_Node_Weight, infolist* infos)
{
int count = 0;//用于判断是否所有节点都被访问过了.
BetreeNode* root = &(RowTreeList->nodelist[RowTreeList->Len - 1]);
BetreeNode* cursor = root;
CodeNode* temp = (CodeNode*)malloc(sizeof(CodeNode));
if (!temp) return OVERFLOW;
InitCoedList(RowTreeList->Len, MyCodeList);
InitInfoList(infos, RowTreeList);
InitTempNode(temp, RowTreeList->Len);
int i = 0;//用于temp内部的长度判定。
int j = 0;//用于广义表的判断
int flag = 0;//root结点出现了两次,说明整个树都被访问完了
while (flag < 2)//只在端点进行访问,左右端点不进行访问。
{
while (cursor->lchild)
{
cursor = cursor->lchild;
temp->CodeBase[i] = '0';//向左转向为0
i++;
}//当左边可以访问时,先序遍历直到所有左边的节点的尽头
temp->CodeBase[i] = '\0';
temp->name = cursor->name;
temp->len = i;//当cursor到达可访问的最左侧时,对其进行读取和访问。
nodecopy(&MyCodeList->ListBase[j], temp);//将存在temp之中的东西扔进正式的存档里边去
count++;
cursor->Visited = TRUE;
j++;
while (!IfRchildAccessb(cursor) && flag < 2)
{
cursor->Visited = TRUE;//先序遍历,当右侧不可访问时,整个子树就被访问完了。
cursor->info.plies = i + change;
cursor = cursor->parent;//当不可访问时,向上退回
if (cursor == root) flag++;
i--;
}//访问制导右侧可以被访问
cursor = cursor->rchild;
temp->CodeBase[i] = '1';//向右侧转向为一
i++;
}
temp->CodeBase[temp->len] = '\0';
root->info.plies = 1;//根节点的度为1
free(temp);
return OK;
}
/*-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+查找并生成code串-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+*/
typedef struct LIST
{
int len;
int max_size;
char* base;
}List;
Status InitList(List* target)
{
if (!target) return ERROR;
target->len = 0;
target->max_size = InitSize;
target->base = (char*)malloc(InitSize * sizeof(char));
if (!target->base) return OVERFLOW;
return OK;
}//初始化列表,用于之后输出和操作的
Status StringCopy(List* list, CodeNode* node)
{
if (!list || !node) return ERROR;
if (list->len + node->len > list->max_size)
{
list->base = (char*)realloc(list->base, (InitSize + (node->len) / IncreaseSize + change) * sizeof(char));
if (!list->base) return OVERFLOW;
list->max_size = list->len + IncreaseSize;
}//当长度过长时,对其重新管理内存,让他正常加长
int i = list->len;
int j = 0;
while (j < node->len)
{
list->base[i] = node->CodeBase[j];
j++;
i++;
}//进行顺序复制
list->base[i] = '\0';//最后一位补上一个\0
list->len = i;
return OK;
}//将他进行复制,扔到list里边去
int Search(CodeList* MyCodeList, char target)
{
int i = 0;
int flag = FALSE;
while (!flag)
{
if (target == MyCodeList->ListBase[i].name)
{
flag = TRUE;
return i;
}
i++;
}
return ERROR;
}//找到相同的元素,最终返回其角标
Status CreateResult(List* list, CodeList* MyCodeList, char** argv)
{
if (!list || !MyCodeList) return ERROR;
InitList(list);
int i = 0;
int MAXLEN = strlen(argv[1]);
while (i < MAXLEN)
{
StringCopy(list, &MyCodeList->ListBase[Search(MyCodeList, argv[1][i])]);
i++;
}
return OK;
}//每一个字符进行写入编码时,将其压进一个长串的队列之中。防止形成伪字符串,后续工程无法直接调用。
/*-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+对编码进行解码操作-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+*/
Status IfError_03_1(BetreeNode* cursor, char input)
{
if (!cursor) return ERROR;
if (input == '0' && IfNotLeaf(cursor) == right) return TRUE;
if (input == '1' && IfNotLeaf(cursor) == left) return TRUE;
return FALSE;
}//判断是不是ERROR——03
Status EnList(List* list, char input)
{
if (!list) return ERROR;
if (list->len == list->max_size - change - change)//change内一位留给结尾符,另外一位留给最后装进去的
{
list->base = (char*)realloc(list->base, (list->max_size + IncreaseSize) * sizeof(char));
list->max_size = list->max_size + IncreaseSize;
}
list->base[list->len] = input;
list->len++;
list->base[list->len] = '\0';
return OK;
}//把东西扔进list里边去
Status DeCodeHulffman(char** argv, RowBetreeList* RowTreeList, List* decode)
{
if (!argv || !RowTreeList) return ERROR;
InitList(decode);
int flag_argv = strlen(argv[2]);
int i = 0;//给argv使用的
BetreeNode* cursor = &RowTreeList->nodelist[RowTreeList->Len - change];//当前指向树的位置。
while (i < flag_argv)
{
while (IfNotLeaf(cursor) && i < flag_argv)
{
if (IfError_03_1(cursor, argv[2][i]))
{
printf("ERROR_03");
return ERROR_03;
}
if (argv[2][i] == '0') cursor = cursor->lchild;
if (argv[2][i] == '1') cursor = cursor->rchild;
i++;
if (i == flag_argv)
{
EnList(decode, cursor->name);
goto k;//如果已经跑完了,就不要让他再回到根节点了
}
}
EnList(decode, cursor->name);//把叶子节点的值放进去
cursor = &RowTreeList->nodelist[RowTreeList->Len - change];
}
k:cursor = cursor;
if (!IfNotLeaf(cursor))//如果cursor不是叶子节点报错,反之不报错
{
return OK;
}
else
{
printf("ERROR_03");
return ERROR_03;
}
}
/*-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+在先序遍历的同时,生成树结点的列表,这个我写完才看见,直接插进源码里边去了-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+*/
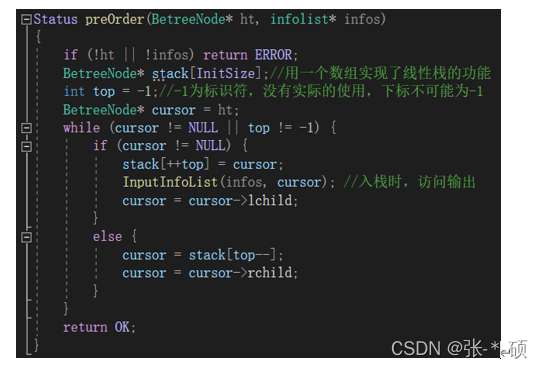
Status preOrder(BetreeNode* ht, infolist* infos)
{
if (!ht || !infos) return ERROR;
BetreeNode* stack[InitSize];//用一个数组实现了线性栈的功能
int top = -1;//-1为标识符,没有实际的使用,下标不可能为-1
BetreeNode* cursor = ht;
while (cursor != NULL || top != -1) {
if (cursor != NULL) {
stack[++top] = cursor;
InputInfoList(infos, cursor); //入栈时,访问输出
cursor = cursor->lchild;
}
else {
cursor = stack[top--];
cursor = cursor->rchild;
}
}
return OK;
}
void FREE(Node_Weight* Cur_Node_Weight, RowBetreeList* RowTreeList, CodeList* MyCodeList, List* list, infolist* infos)
{
free(Cur_Node_Weight);
free(RowTreeList);
free(MyCodeList);
free(list);
free(infos);
}//把所有free操作打个包
Status PRINT(infolist* infos)
{
if (!infos || infos->len < 1) return ERROR;
int i = 0;
while (i < infos->len)
{
printf("结点序号:%d weight:%d parent:%d lchild:%d rchild:%d 度:%d 层数:%d\n",
infos->info[i].index, infos->info[i].weight, infos->info[i].parent, infos->info[i].lchild, infos->info[i].rchild, infos->info[i].du, infos->info[i].plies);
i++;
}
return OK;
}//把infos里边的东西打印出来,这一点保证了不会出现伪串等问题,后续程序可以直接调用
int main(int aggc, char** argv)
{
if (IfError_01(aggc)) return ERROR_01;//判断是否有问题1
Node_Weight* Cur_Node_Weight = (Node_Weight*)malloc(sizeof(Node_Weight));//分配存放地址空间
if (!Cur_Node_Weight) return OVERFLOW;
CreateNode_Weight(argv, Cur_Node_Weight);//生成节点和其权重
if (If_Error_02(Cur_Node_Weight)) return ERROR_02;
RowBetreeList* RowTreeList = (RowBetreeList*)malloc(sizeof(RowBetreeList));//生成生节点串串,处理之后最后一位就是树的根节点
if (!RowTreeList) return OVERFLOW;
Create_Huffman_Tree(RowTreeList, Cur_Node_Weight);//生成霍夫曼树,树在RowTreeList的最后一位上边
CodeList* MyCodeList = (CodeList*)malloc(sizeof(struct CODELIST));
if (!MyCodeList) return OVERFLOW;
infolist* infos = (infolist*)malloc(sizeof(infolist));//生成树节点的数据
if (!infos) return OVERFLOW;
CreateCodeList(MyCodeList, RowTreeList, Cur_Node_Weight, infos);//将霍夫曼树编辑成为一个可以调用的广义表
List* list = (List*)malloc(sizeof(List));
if (!list) return OVERFLOW;
CreateResult(list, MyCodeList, argv);//每一个字符进行写入编码时,将其压进一个长串的队列之中。防止形成伪字符串,后续工程无法直接调用。
List* decode = (List*)malloc(sizeof(List));
if (!decode) return OVERFLOW;
if (DeCodeHulffman(argv, RowTreeList, decode) == ERROR_03) return ERROR_03;//对数进行解码操作
BetreeNode* root = &RowTreeList->nodelist[RowTreeList->Len - change];
preOrder(root, infos);
PRINT(infos);
printf("%s", list->base);
printf(" %s", decode->base);
FREE(Cur_Node_Weight, RowTreeList, MyCodeList, list, infos);//释放所有的内存结点
return 0;
}
















 2494
2494

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









