







摘要 (Summary)
The 3 ways to compute the feature importance for the scikit-learn Random Forest was presented:
提出了三种计算scikit-learn随机森林特征重要性的方法:
- built-in feature importance
内置功能的重要性
- permutation-based importance
基于置换的重要性
- computed with SHAP values
用SHAP值计算
内置随机森林重要性 (Built-in Random Forest Importance)
基尼重要性 (或平均减少杂质),由随机森林结构计算得出。
我将展示如何使用scikit-learn软件包和Boston数据集(房价回归任务)来计算随机森林的特征重要性。
boston = load_boston()
X = pd.DataFrame(boston.data, columns=boston.feature_names)
y = boston.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=12)使随机森林回归器具有100个决策树:
rf = RandomForestRegressor(n_estimators=100)rf.fit(X_train, y_train)要从“随机森林”模型中获取要素重要性,请使用feature_importances_参数:
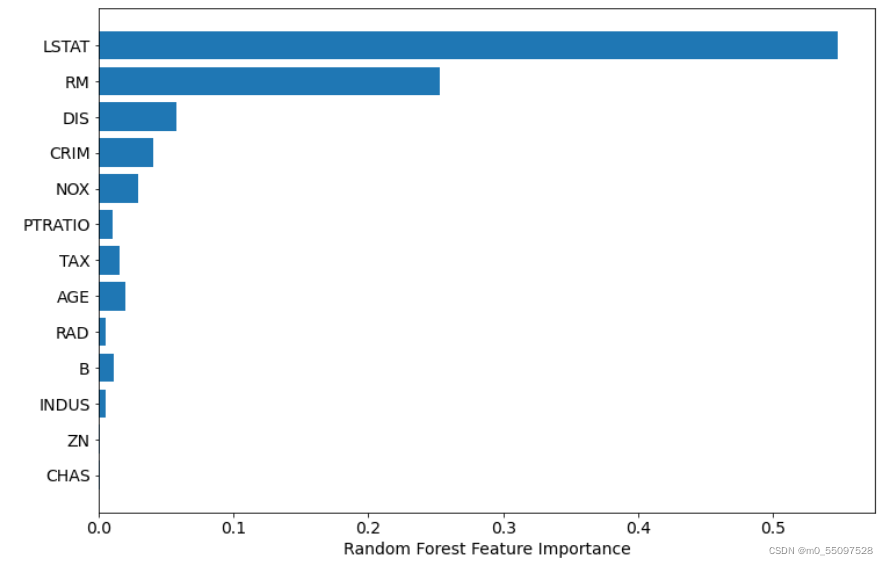
rf.feature_importances_array([0.04054781, 0.00149293, 0.00576977, 0.00071805, 0.02944643, 0.25261155, 0.01969354, 0.05781783, 0.0050257 , 0.01615872, 0.01066154, 0.01185997, 0.54819617])plt.barh(boston.feature_names, rf.feature_importances_)
基于排列的重要性 (Permutation-based Importance)
基于置换的重要性可用于克服使用平均杂质减少计算出的默认特征重要性的缺点。 它在scikit-learn作为permutation_importance方法实现。该方法将随机地对每个功能进行随机排序,并计算模型性能的变化。 最影响性能的功能是最重要的功能。
计算排列重要性:
perm_importance = permutation_importance(rf, X_test, y_test)
绘制重要性:
sorted_idx = perm_importance.importances_mean.argsort()plt.barh(boston.feature_names[sorted_idx], perm_importance.importances_mean[sorted_idx])plt.xlabel("Permutation Importance")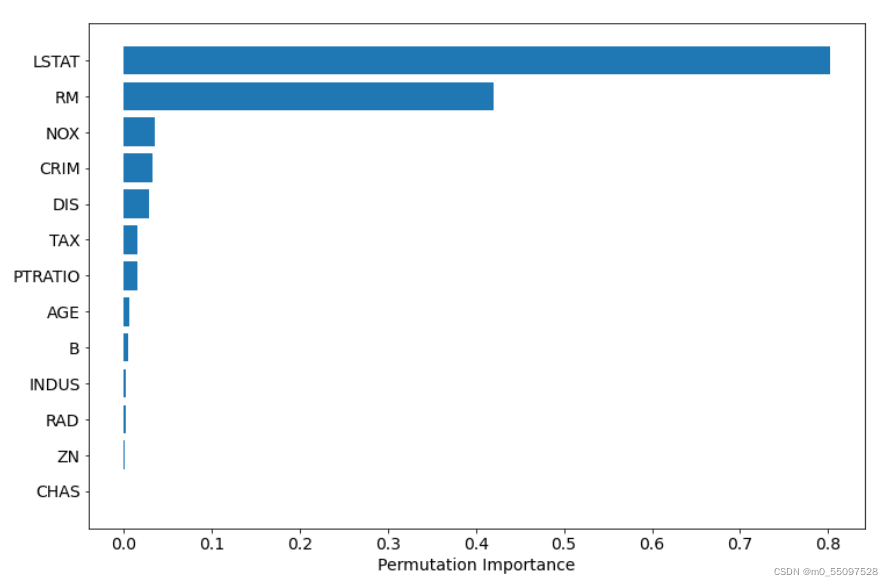
注: 基于排列的重要性非常消耗计算资源。
从SHAP值计算重要性 (Compute Importance from SHAP Values)
可以使用SHAP解释(与模型无关)来计算随机森林中的特征重要性。 它使用博弈论中的Shapley值来估计每个特征如何对预测做出贡献。 它可以轻松安装( pip install shap )并与scikit-learn随机森林一起使用:
explainer = shap.TreeExplainer(rf)shap_values = explainer.shap_values(X_test)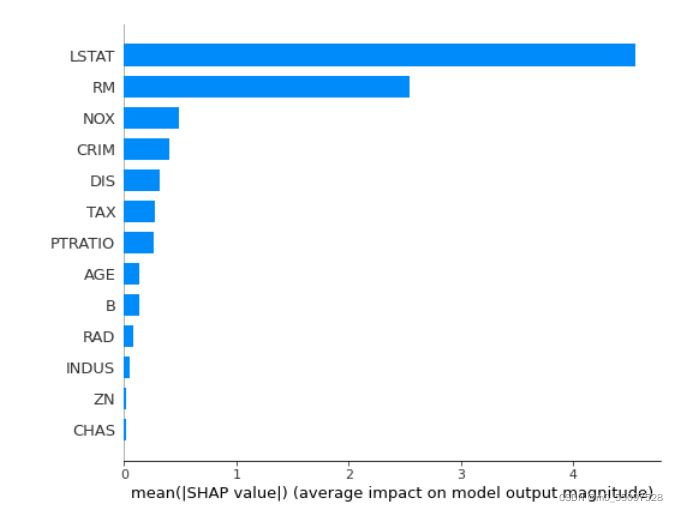
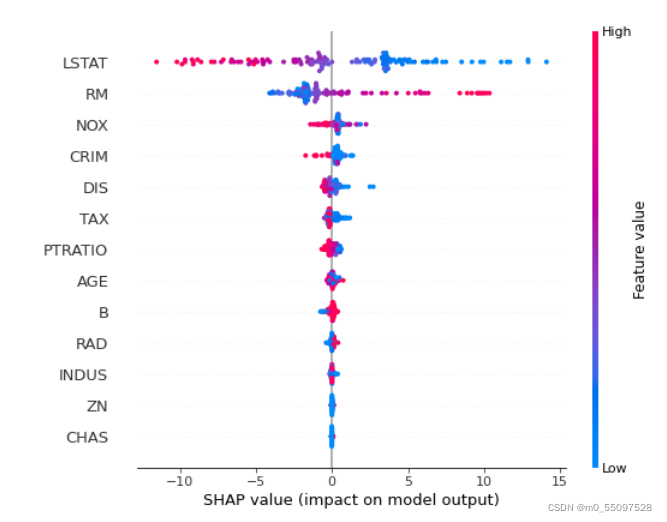
使用更多细节绘制特征重要性,以显示特征值:
shap.summary_plot(shap_values, X_test)


















 1023
1023

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









