




1. 投影梯度下降法(PGD)
1.1 介绍
前面章节我们介绍了梯度下降法来解决无约束的非线性优化问题。那么如何解决带约束的非线性优化问题呢?一个直观的想法是:我们依旧先进行梯度下降到一个相对较小的点,然后再将这个点通过某种方式投影到可行域内。如图:
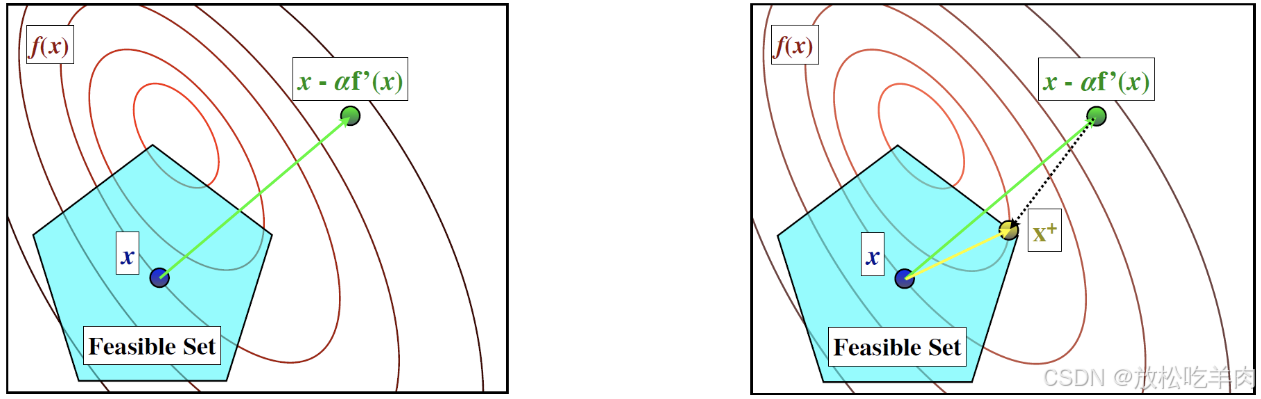
- 第一步:进行无约束的梯度下降:
x k + 1 2 = x k − η k ∇ f ( x k ) \mathbf{x}^{k+\frac{1}{2}}=\mathbf{x}^k-\eta_k\nabla f(\mathbf{x}^k) xk+21=xk−ηk∇f(xk)
- 第二步:将 x k + 1 2 \mathbf{x}^{k+\frac{1}{2}} xk+21 通过某种度量映射到可行域 Ω \Omega Ω 内最接近的点:
x k + 1 ∈ arg min x ∈ Ω ∣ ∣ x − x k + 1 2 ∣ ∣ \mathbf{x}^{k+1}\in\arg\min\limits_{\mathbf{x}\in\Omega}||\mathbf{x}-\mathbf{x}^{k+\frac{1}{2}}|| xk+1∈argx∈Ωmin∣∣x−xk+21∣∣
记”把 x \mathbf{x} x 投影到 Ω \Omega Ω 上”为: P Ω ( x ) = arg min x ′ ∈ Ω ∣ ∣ x ′ − x ∣ ∣ \mathcal{P}_\Omega(\mathbf{x})=\arg\min\limits_{\mathbf{x'\in\Omega}}||\mathbf{x'}-\mathbf{x}|| PΩ(x)=argx′∈Ωmin∣∣x′−x∣∣,对于凸可行域,投影 P Ω ( x ) \mathcal{P}_\Omega(\mathbf{x}) PΩ(x) 是唯一的。
1.2 理解
【回忆】:在无约束非线性优化中,梯度下降法可以看成是最小化某个点处的二阶估计:
x
k
+
1
=
arg
min
x
{
f
(
x
k
)
+
∇
f
(
x
k
)
T
(
x
−
x
k
)
+
1
2
η
k
∣
∣
x
−
x
k
∣
∣
2
}
.
\mathbf{x}^{k+1}=\arg\min\limits_{\mathbf{x}}\{f(\mathbf{x}^k)+\nabla f(\mathbf{x}^k)^T(\mathbf{x}-\mathbf{x}^k)+\frac{1}{2\eta_k}||\mathbf{x}-\mathbf{x}^k||^2\}.
xk+1=argxmin{f(xk)+∇f(xk)T(x−xk)+2ηk1∣∣x−xk∣∣2}.
加上约束后,
x
k
+
1
∈
arg
min
x
∈
Ω
{
f
(
x
k
)
+
∇
f
(
x
k
)
T
(
x
−
x
k
)
+
1
2
η
k
∣
∣
x
−
x
k
∣
∣
2
}
≡
arg
min
x
∈
Ω
{
η
k
f
(
x
k
)
⏟
constant
+
η
k
∇
f
(
x
k
)
T
(
x
−
x
k
)
+
1
2
∣
∣
x
−
x
k
∣
∣
2
}
(multiply by
η
k
)
≡
arg
min
x
∈
Ω
{
η
k
2
2
f
(
x
k
)
⏟
constant
+
η
k
∇
f
(
x
k
)
T
(
x
−
x
k
)
+
1
2
∣
∣
x
−
x
k
∣
∣
2
}
(
±
constants not rely on
x
)
≡
arg
min
x
∈
Ω
{
1
2
∣
∣
(
x
−
x
k
)
+
η
k
∇
f
(
x
k
)
∣
∣
2
}
≡
arg
min
x
∈
Ω
{
∣
∣
x
−
(
x
k
−
η
k
∇
f
(
x
k
)
)
⏟
gradient descent
∣
∣
2
}
.
\begin{align} \mathbf{x}^{k+1}&\in\arg\min\limits_{\mathbf{x}\in\Omega}\{f(\mathbf{x}^k)+\nabla f(\mathbf{x}^k)^T(\mathbf{x}-\mathbf{x}^k)+\frac{1}{2\eta_k}||\mathbf{x}-\mathbf{x}^k||^2\}\\ &\equiv \arg\min\limits_{\mathbf{x}\in\Omega}\{\underbrace{\eta_kf(\mathbf{x}^k)}_{\text{constant}}+\eta_k\nabla f(\mathbf{x}^k)^T(\mathbf{x}-\mathbf{x}^k)+\frac{1}{2}||\mathbf{x}-\mathbf{x}^k||^2\} \text{(multiply by $\eta_k$)}\\ &\equiv \arg\min\limits_{\mathbf{x}\in\Omega}\{\underbrace{\frac{\eta_k^2}{2}f(\mathbf{x}^k)}_{\text{constant}}+\eta_k\nabla f(\mathbf{x}^k)^T(\mathbf{x}-\mathbf{x}^k)+\frac{1}{2}||\mathbf{x}-\mathbf{x}^k||^2\} \text{($\pm$ constants not rely on $\mathbf{x}$)}\\ &\equiv \arg\min\limits_{\mathbf{x}\in\Omega}\{\frac{1}{2}||(\mathbf{x}-\mathbf{x^k})+\eta_k\nabla f(\mathbf{x}^k)||^2\}\\ &\equiv \arg\min\limits_{\mathbf{x}\in\Omega}\{||\mathbf{x}-\underbrace{(\mathbf{x}^k-\eta_k\nabla f(\mathbf{x}^k))}_{\text{gradient descent}}||^2\}. \end{align}
xk+1∈argx∈Ωmin{f(xk)+∇f(xk)T(x−xk)+2ηk1∣∣x−xk∣∣2}≡argx∈Ωmin{constant
ηkf(xk)+ηk∇f(xk)T(x−xk)+21∣∣x−xk∣∣2}(multiply by ηk)≡argx∈Ωmin{constant
2ηk2f(xk)+ηk∇f(xk)T(x−xk)+21∣∣x−xk∣∣2}(± constants not rely on x)≡argx∈Ωmin{21∣∣(x−xk)+ηk∇f(xk)∣∣2}≡argx∈Ωmin{∣∣x−gradient descent
(xk−ηk∇f(xk))∣∣2}.
1.3 适用场景
当投影操作计算方便时,即可行域较为简单时可用。以下是一些简单可行域的例子:
- 变量只有上界或下界: L ≤ x ≤ U L\leq \mathbf{x}\leq U L≤x≤U
- 只有线性等式约束: a T x = b \mathbf{a}^T\mathbf{x}=\mathbf{b} aTx=b
- 只有半空间约束: a T x ≤ b \mathbf{a}^T\mathbf{x}\leq\mathbf{b} aTx≤b
- 只有 norm-ball 约束: ∣ ∣ x ∣ ∣ p ≤ τ ||\mathbf{x}||_p\leq\tau ∣∣x∣∣p≤τ,for p = 1 , 2 , ∞ p=1,2,\infin p=1,2,∞
【例1】(使用投影梯度下降解SVM)
【例2】(将 L 1 L_1 L1 正则化,i.e.,LASSO回归,转换成约束优化问题)
2. 应用:软间隔支持向量机
2.1 引入松弛变量 ξ i \xi_i ξi
在之前的介绍中,我们假设数据点是能够用一个线性超平面分割的,于是我们形式化求解了硬间隔的SVMs。在实际应用中,我们常常很难遇到能够完全线性分离的数据集,如图:
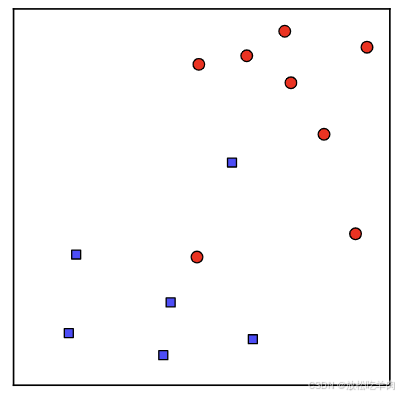
这种情况下,我们就无法找到
(
x
,
b
)
(\mathbf{x},b)
(x,b) 满足
y
i
(
x
T
s
i
+
b
)
≥
1
,
∀
i
=
1
,
⋯
,
m
y^i(\mathbf{x}^T\mathbf{s}^i+b)\geq1,\forall i =1,\cdots,m
yi(xTsi+b)≥1,∀i=1,⋯,m。所以我们试图为每一个训练样本
s
i
\mathbf{s}^i
si 引入一个松弛变量
ξ
i
≥
0
\xi_i\geq0
ξi≥0 来放宽原来的约束:
y
i
(
x
T
s
i
+
b
)
≥
1
−
ξ
i
y^i(\mathbf{x}^T\mathbf{s}^i+b)\geq1-\xi_i
yi(xTsi+b)≥1−ξi
其中,松弛变量
ξ
i
≥
0
\xi_i\geq0
ξi≥0 反应了原训练样本违反原来约束的程度。如果
ξ
i
=
0
\xi_i=0
ξi=0,说明对应的
s
i
\mathbf{s}^i
si 能够被 margin 分隔开。如果
ξ
i
≥
1
\xi_i\geq1
ξi≥1,则说明
s
i
\mathbf{s}^i
si 将会被错误的分类,因为在这个情况下
y
i
(
x
T
s
i
+
b
)
y^i(\mathbf{x}^T\mathbf{s}^i+b)
yi(xTsi+b) 可能会变成负数。
因此,我们通过最小化平均松弛变量 1 m ∑ ξ i \frac{1}{m}\sum\xi_i m1∑ξi 来使得平均约束违反程度最小。
2.2 用PGD求解软间隔SVM
我们将
C
m
∑
ξ
i
\frac{C}{m}\sum\xi_i
mC∑ξi 引入原问题目标函数,其中
C
C
C 权衡了
∣
∣
x
∣
∣
2
||\mathbf{x}||^2
∣∣x∣∣2 和
∑
ξ
i
\sum\xi_i
∑ξi 。为了简化问题,我们忽略
b
\mathbf{b}
b,则软间隔的SVM原问题为:
min
x
,
ξ
1
2
∣
∣
x
∣
∣
2
+
C
m
∑
i
=
1
m
ξ
i
s.t.
y
i
(
x
T
x
i
)
≥
1
−
ξ
i
,
ξ
i
≥
0
,
∀
i
=
1
,
⋯
,
m
\min\limits_{\mathbf{x},\xi}\frac{1}{2}||\mathbf{x}||^2+\frac{C}{m}\sum_{i=1}^m\xi_i\\ \text{s.t. }y^i(\mathbf{x}^T\mathbf{x}^i)\geq1-\xi_i,\xi_i\geq0,\forall i=1,\cdots,m
x,ξmin21∣∣x∣∣2+mCi=1∑mξis.t. yi(xTxi)≥1−ξi,ξi≥0,∀i=1,⋯,m
使用 KKT 条件我们可以推导出软间隔SVM对偶问题:
max
λ
∑
i
=
1
m
λ
i
−
1
2
∑
i
=
1
m
∑
j
=
1
m
λ
i
λ
j
y
i
y
j
(
s
i
)
T
s
j
s.t.
λ
i
∈
[
0
,
C
/
m
]
,
∀
i
=
1
,
⋯
,
m
\max\limits_{\lambda}\sum_{i=1}^m\lambda_i-\frac{1}{2}\sum_{i=1}^m\sum_{j=1}^m\lambda_i\lambda_jy^iy^j(\mathbf{s}^i)^T\mathbf{s}^j\\ \text{s.t. } \lambda_i\in [0,C/m],\forall i=1,\cdots,m
λmaxi=1∑mλi−21i=1∑mj=1∑mλiλjyiyj(si)Tsjs.t. λi∈[0,C/m],∀i=1,⋯,m
用对偶函数表示为:
max
λ
q
(
λ
)
:
=
∑
i
=
1
m
λ
i
−
1
2
λ
T
Q
λ
s.t.
λ
i
∈
[
0
,
C
/
m
]
,
∀
i
=
1
,
⋯
,
m
where
Q
:
=
[
(
y
1
)
2
(
s
1
)
T
s
1
⋯
y
1
y
m
(
s
1
)
T
s
m
⋮
⋱
⋮
y
m
y
1
(
s
m
)
T
s
1
⋯
(
y
m
)
2
(
s
m
)
T
s
m
]
\max\limits_{\lambda}q(\lambda):=\sum_{i=1}^m\lambda_i-\frac{1}{2}\lambda^TQ\lambda\\ \text{s.t. }\lambda_i\in[0,C/m],\forall i=1,\cdots,m\\ \text{where } Q:=\left[ \begin{matrix} (y^1)^2(\mathbf{s}^1)^T\mathbf{s}^1 & \cdots & y^1y^m(\mathbf{s}^1)^T\mathbf{s}^m\\ \vdots & \ddots & \vdots\\ y^my^1(\mathbf{s}^m)^T\mathbf{s}^1 & \cdots & (y^m)^2(\mathbf{s}^m)^T\mathbf{s}^m \end{matrix} \right]
λmaxq(λ):=i=1∑mλi−21λTQλs.t. λi∈[0,C/m],∀i=1,⋯,mwhere Q:=
(y1)2(s1)Ts1⋮ymy1(sm)Ts1⋯⋱⋯y1ym(s1)Tsm⋮(ym)2(sm)Tsm
接下来对其使用PGD算法:
- step 1:初始化 λ 0 ∈ R m \lambda_0\in \R^m λ0∈Rm 和 Q Q Q
- step 2:for
k
=
0
,
1
,
⋯
,
t
−
1
k=0,1,\cdots,t-1
k=0,1,⋯,t−1 do
- step 2.1: λ k + 1 2 = λ k − η k ∇ q ( λ k ) \lambda_{k+\frac{1}{2}}=\lambda_k-\eta_k\nabla q(\lambda_k) λk+21=λk−ηk∇q(λk)
- step 2.2: λ k + 1 = min { max { 0 , λ 1 + 1 2 } , C m } \lambda_{k+1}=\min\{\max\{0,\lambda_{1+\frac{1}{2}}\},\frac{C}{m}\} λk+1=min{max{0,λ1+21},mC}
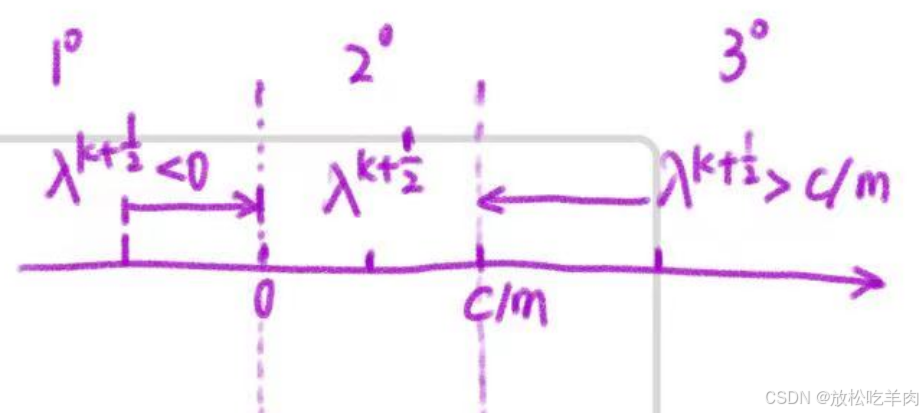
【说明】:在step 2.2中,
λ
k
+
1
=
arg
min
λ
∣
∣
λ
−
λ
k
+
1
2
∣
∣
\lambda_{k+1}=\arg\min\limits_{\lambda}||\lambda-\lambda_{k+\frac{1}{2}}||
λk+1=argλmin∣∣λ−λk+21∣∣,画图可知,当
λ
k
+
1
2
<
0
\lambda_{k+\frac{1}{2}}<0
λk+21<0 时,把它归到0,当
λ
k
+
1
2
>
C
m
\lambda_{k+\frac{1}{2}}>\frac{C}{m}
λk+21>mC 时,在 C/m 处截断,即
λ
k
+
1
=
min
{
max
{
0
,
λ
1
+
1
2
}
,
C
m
}
\lambda_{k+1}=\min\{\max\{0,\lambda_{1+\frac{1}{2}}\},\frac{C}{m}\}
λk+1=min{max{0,λ1+21},mC}。

















 1527
1527

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









