



根据博客 Android-View 绘制原理(01)-JAVA层分析_android view draw原理分析-优快云博客
提出了我的疑问 Canvas RenderNode updateDisplayListDirty 这些东西的关系
您的理解在基本方向上是对的,但让我详细解释一下 Android 中 updateDisplayListDirty、指令集合、Canvas 和 RenderNode 之间的关系:
RenderNode 与渲染过程
在 Android 的渲染系统中:
- RenderNode:
- 是一个存储渲染操作的容器
- 包含了视图的绘制命令和属性信息
- 可以被缓存和重用,提高渲染效率
- DisplayList:
- 实际上是 RenderNode 内部的绘制命令列表
- 存储了一系列需要执行的渲染指令
- 通过
updateDisplayListDirty方法更新这些指令
- Canvas:
- 是应用层与渲染系统交互的接口
- 提供了各种绘制方法(drawRect、drawText 等)
- 当我们调用 Canvas 的绘制方法时,它会转换为渲染指令
updateDisplayListDirty 与 Canvas 的关系
updateDisplayListDirty 方法在 View 类中实现,主要作用是:
- 创建或获取一个 RenderNode
- 使用 DisplayListCanvas(特殊的 Canvas 实现)录制绘制指令
- 当视图调用 onDraw() 方法时,它使用提供的 Canvas 执行绘制
- 这些绘制命令被记录到 DisplayList 中
- 最终生成或更新 RenderNode
Canvas 和 DisplayList 不是可替代关系,而是协作关系:
- Canvas 是绘制接口,应用通过它表达"画什么"
- DisplayList 是指令集合,记录"如何画"
- RenderNode 是整个结构的容器,包含了 DisplayList 和其他渲染属性
所以不是"有一个就可以了",而是它们在渲染管线中扮演不同角色:Canvas 是应用用来绘制的工具,而 DisplayList 是记录这些绘制指令的容器,两者共同构成了 Android 的高效渲染系统。
看完后我的疑问变成了,既然 updateDisplayListDirty 是一个指令集合 在硬件加速的情况下,一个渲染当VSYNC信号来了,进行三大流程进行获取surfaceControl然后进行 绘制,绘制时候先新建RenderNode 然后获取 RenderNode 的
RecordingCanvas canvas = mRootNode.beginRecording(mSurfaceWidth, mSurfaceHeight);
RecordingCanvas 然后把它变成后续的 Canvas
最后
public void endRecording() {
if (mCurrentRecordingCanvas == null) {
throw new IllegalStateException(
"No recording in progress, forgot to call #beginRecording()?");
}
RecordingCanvas canvas = mCurrentRecordingCanvas;
mCurrentRecordingCanvas = null;
canvas.finishRecording(this);
canvas.recycle();
}finishRecording 把 当前的 RenderNode 传过去 然后进行绘制
那么我的问题是 之后surfaceFlinger是否绘制的是指令集合?是否是当RecordingCanvas 执行一次生成一个指令就绘制一部分还是 finishRecording 后一起进行绘制?
您的问题涉及到 Android 渲染流水线的关键细节,我来详细解释:
finishRecording 与渲染流程
在 Android 的硬件加速渲染流程中,当 finishRecording() 被调用时:
- 指令集完成阶段:
finishRecording()标志着 RecordingCanvas 已经完成所有绘制命令的记录- 此时,所有来自
onDraw()的绘制操作已经被转换为渲染指令并存储在 RenderNode 中 - 这些指令并不会立即触发绘制
- 批处理渲染模式:
- SurfaceFlinger 不会 在每条指令生成后立即渲染
- 系统采用批处理模式,收集完所有指令后一次性处理
- 这种方式大大提高了渲染效率,避免了频繁的状态切换和上下文切换
- 渲染时机:
- 在
ViewRootImpl.performTraversals()完成后,会调用ThreadedRenderer.draw() - 此时,所有视图的 RenderNode 都已准备就绪
- 系统会将这些渲染命令通过 HWUI 传递给 GPU
- SurfaceFlinger 会在下一个 VSYNC 信号到来时合成并显示结果
- 在
- SurfaceFlinger 处理:
- SurfaceFlinger 接收的是已经处理过的图层数据
- 它主要负责合成多个应用的图层,而不是执行具体的绘制指令
- 实际的指令执行发生在 GPU 上,在应用进程的渲染线程中
所以,回答您的核心问题:系统是在 finishRecording() 后,将完整的指令集合一次性提交给渲染管线进行处理,而不是每生成一条指令就执行一次渲染。这种批处理模式是现代图形渲染系统的普遍做法,可以最大限度地减少 GPU 状态切换,提高渲染效率。
需要注意的是,RecordingCanvas 记录的指令集和 SurfaceFlinger 处理的内容在概念上有区别——前者是应用内的绘制指令,后者处理的是已经渲染好的图层。
那这些指令在哪被处理?
这些渲染指令的处理发生在多个层次的渲染管线中,让我详细解释这个流程:
渲染指令的处理路径
- 应用进程中的处理:
- 当
finishRecording()完成后,渲染指令首先在应用自己的渲染线程中处理 ThreadedRenderer类负责协调这个过程- 具体处理由 HWUI (Hardware User Interface) 库在原生层完成
- 在这一阶段,渲染指令被转换为 GPU 可以理解的命令(如 OpenGL ES 或 Vulkan 调用)
- 当
- RenderThread 中的执行:
- Android 使用专门的 RenderThread(渲染线程)处理这些指令
- 这个线程与主线程分离,可以并行处理渲染工作
- 渲染指令在这里被组织成命令缓冲区(Command Buffer)
- 这些命令最终会通过图形驱动提交给 GPU
- GPU 执行阶段:
- GPU 接收这些渲染命令并执行实际的像素处理
- 渲染结果被写入到应用的 Surface 对应的图形缓冲区中
- 这个过程完全由 GPU 硬件加速完成
- SurfaceFlinger 的角色:
- SurfaceFlinger 不处理原始渲染指令,而是处理已渲染好的图层
- 它从各个应用获取已经渲染好的图形缓冲区
- 然后进行合成(Composition)操作,决定不同应用的图层如何叠加显示
- 最后将合成结果提交给显示硬件
具体源码路径
如果您想在源码中追踪这个处理过程:
ThreadedRenderer.nSyncAndDrawFrame()是关键的入口点,它通过 JNI 调用原生层代码- 在原生层,
android_view_ThreadedRenderer.cpp包含了相关实现 - 进一步深入到
libs/hwui/目录,特别是RenderProxy和RenderThread相关类 - 最终的 GPU 命令提交通过图形驱动 API(如 OpenGL ES 或 Vulkan)完成
所以,渲染指令主要在应用自己的渲染线程中被处理和执行,而不是在 SurfaceFlinger 中。SurfaceFlinger 的工作是在所有应用都完成各自的渲染后,组合这些结果并显示到屏幕上。
看完第二篇Android-View绘制原理(02)-VSync原理之SurfaceFlinger篇_android surface绘制-优快云博客
决定画个时序图吧,时序图对这块能更有帮助
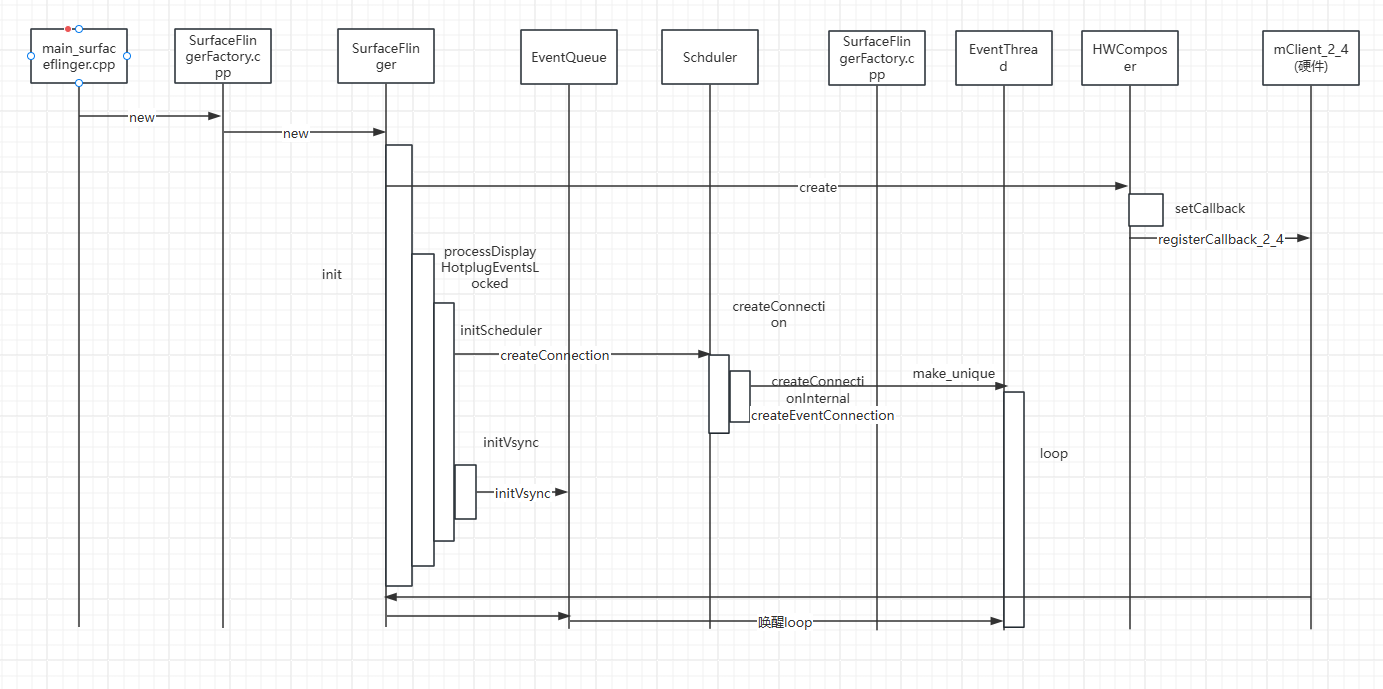
看第三篇
Android-View绘制原理(03)-Vsync原理之App篇_connection->resynccallback();-优快云博客
先做一下总结 VSYNC信号到底是怎么从系统走到APP的
C++ 经常使用文件互相通信么?为什么SurfaceFlinger跟APP层通信VSYNC不使用binder或者使用socket使用文件操作符呢
为什么不用 Binder?
它不适合高频率、低延迟、精细同步类的场景,原因如下:
| 高延迟 | Binder 通信涉及 context switch、队列排队 |
| 非事件驱动 | 不适合做 epoll 监听事件 |
| 高频通信负载大 | 每秒 60/120 次同步会占用太多资源 |
| 线程切换成本大 | 频繁唤醒目标线程开销大 |
为什么用文件描述符(FD)配合 epoll?
Android 使用 DisplayEventReceiver + epoll + Fd 来监听 VSYNC 信号,主要基于以下几个优势:
-
epoll是 Linux 的高性能 I/O 事件监听机制; -
App 可以将
DisplayEventReceiver提供的 FD 注册进Looper中; -
一旦 VSYNC 到来,FD 变得可读,主线程被唤醒进行绘制操作;
-
实现“被动唤醒”机制,避免忙轮询,节能省资源。
说白了binder开销大,fd+looper这种开销小,适合这种毫秒级别的场景
FD 通信不但效率高,而且适合事件触发型、频繁、延迟敏感的场景;而 Binder 更适合复杂的数据交互和权限管理。
那这个FD通信是管道通信么?FD是否拿到对象然后生成文件操作符直接就能调动访问?这样的通信可以跨进程么?
它只是一个内核资源的“句柄”,但原理类似:写一端触发,读一端被 epoll 唤醒。
在一端调用send接口另一端必须调用read接口才能接收到对吧,而不是直接触发类里的方法,可以跨进程的
常见的玩法是通过AIDL传递fd操作符给系统,系统通过fd操作符和APP层跨进程通信
VSYNC为什么不是真的16ms一帧?为什么需要APP发出需要更新才更新
VSYNC 是固定 16.6ms(60Hz)触发一次,但系统只有在“应用请求更新”时才会真正执行绘制和提交帧(合成)。
但真正绘制需要 APP 主动请求
为什么这样设计?
没必要每帧绘制静态内容,避免 CPU/GPU 资源浪费
ViewRootImpl 先走进行post需要VSYNC信号到底层同时把三大流程封装成任务,底层进行返回之后再直接绘制任务
private void postCallbackDelayedInternal(int callbackType,
Object action, Object token, long delayMillis) {
synchronized (mLock) {
final long now = SystemClock.uptimeMillis();
final long dueTime = now + delayMillis;
mCallbackQueues[callbackType].addCallbackLocked(dueTime, action, token);
if (dueTime <= now) {
scheduleFrameLocked(now);
} else {
Message msg = mHandler.obtainMessage(MSG_DO_SCHEDULE_CALLBACK, action);
msg.arg1 = callbackType;
msg.setAsynchronous(true);
mHandler.sendMessageAtTime(msg, dueTime);
}
}
} 看了文章4
Android-View绘制原理(04)-生成Surface_android.view.surfacecontrol-优快云博客
产生了一个问题,surfaceControl 直接就能将内容送显 那么之前文章1学到的 Canvas 和 RenderNode 又是怎么串联到一起的?这个应该是之前漏掉的
WMS获取有效的surfaceControl
surfaceControl获取 到layer 在surfaceFlinger,然后 mAttachInfo.mThreadedRenderer.setSurfaceControl(mSurfaceControl, mBlastBufferQueue); 获取到了 mSurfaceControl 和 mBlastBufferQueue
然后再获取到 RenderNode 这个指令集合 最后 跟surfaceControl进行通信生成指令集合的buffer,最后进行绘制
正常来讲
MediaCodec 配合 SurfaceControl 直接就能进行绘制
BLASTBufferQueue 是做什么的?里面的元素,我绘制时候是向哪个元素提交数据啊?提交完里面为什么有个生产消费模型啊?解决了什么问题?为什么不能直接提交给surfaceFlinger,为什么要有个生产消费模型?
一、BLASTBufferQueue 是做什么的?
它的核心作用是:
在客户端和 SurfaceFlinger 之间高效管理图像缓冲的生产与消费过程,同时保证事务的一致性和时序正确性。
二、里面的元素是啥?我绘制时是往哪个元素提交数据?
BLASTBufferQueue 内部的关键元素包括:
-
GraphicBufferProducer:客户端通过它把 buffer 提交进去。 -
GraphicBufferConsumer(由 SurfaceFlinger 拿着):SurfaceFlinger 从它那里消费 buffer 进行合成。 -
内部的
Surface/SurfaceControl关联的ANativeWindow:你绘制的时候,就是向这个ANativeWindow提交 buffer。 -
事务同步模块:确保 buffer 和它所绑定的 SurfaceControl 的位置、大小、变换等属性一起生效。
你调用:
ANativeWindow_lock(...);
绘制内容;
ANativeWindow_unlockAndPost(...);最终走到的是 BLASTBufferQueue 封装的 GraphicBufferProducer。
为什么里面是生产者-消费者模型?解决了什么问题?
这是 BufferQueue 和 BLASTBufferQueue 的核心设计:解耦生产者(App/UI线程)和消费者(SurfaceFlinger/合成线程)。
作用如下:
-
跨线程/进程同步:App 负责生产 buffer,但 SurfaceFlinger 合成是在另一个线程/进程中进行的,需要通过共享内存 + sync fence 机制协调。
-
避免绘制阻塞合成,反之亦然:防止合成时 App 还在写入 buffer,或 App 因等待 SurfaceFlinger 合成完阻塞。
-
复用缓冲区减少拷贝和内存分配开销:buffer 是循环复用的,避免每帧都 malloc。
-
控制帧率与掉帧策略:如果生产太快,buffer queue 会阻塞或丢帧,控制提交节奏。

















 228
228

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









