



 文章介绍了如何使用Python进行线性回归模型的构建,包括设置截距和标准化。还涉及到了时间序列数据分析,如设置索引、重采样。在数据预处理方面,讨论了处理缺失值、重复值的方法。此外,提到了模型训练,如LightGBM的使用,以及模型评估的多种指标。
文章介绍了如何使用Python进行线性回归模型的构建,包括设置截距和标准化。还涉及到了时间序列数据分析,如设置索引、重采样。在数据预处理方面,讨论了处理缺失值、重复值的方法。此外,提到了模型训练,如LightGBM的使用,以及模型评估的多种指标。
常用函数总结
线性回归模型
from sklearn import linear_model
clf = linear_model.LinearRegression(fit_intercept=True, normalize=True)
# fit_intercept: 默认为True, 表示需要计算截距
# normalize:
clf.fit(x, y) # 你和线性模型
k = clf.coef_ # 斜率
b = clf.intercept_ # 截距
y_pred = clf.predict(x) # 预测 y 值
时间序列数据
import pandas as pd
...
df = pd.DataFrame(pd.read_excel(file))
df = df.set_index('COL_NAME', drop=True) # 将COL_NAME列设置为索引 drop=True表示将该列从数据表中删除
df1 = df.to_peroid('M') # to_peroid(freq) 按照freq指定的格式显示数据 'M' 按月显示, 'Q' 按季度显示 'A' 按年度显示
# 重采样
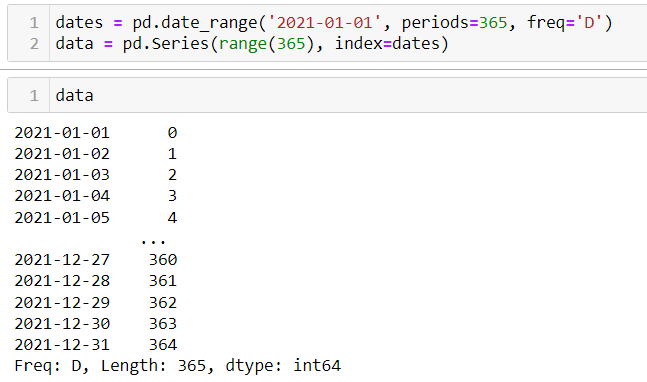

杂项
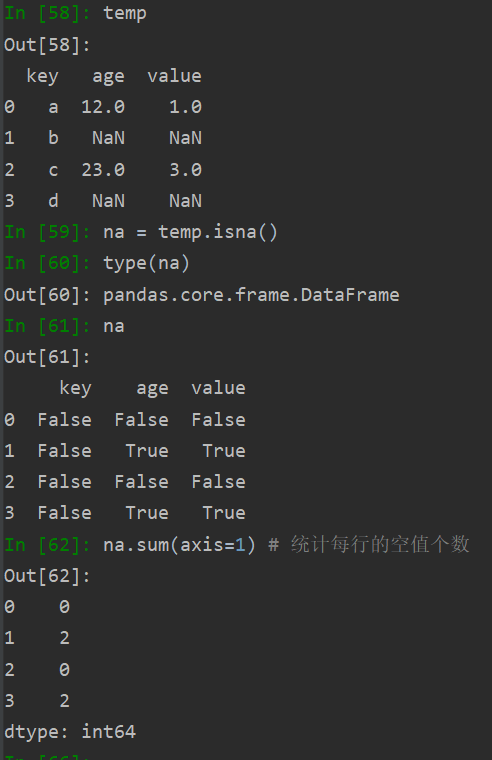
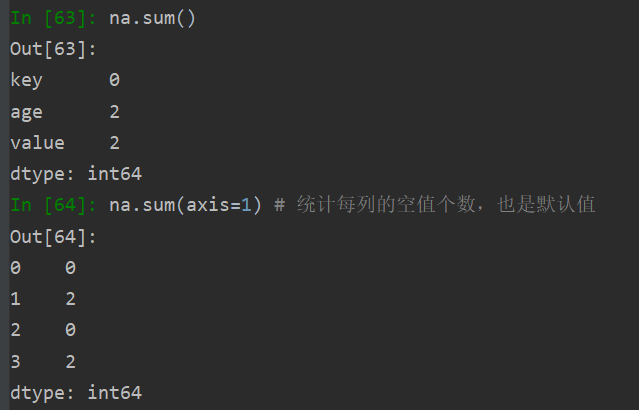
isna

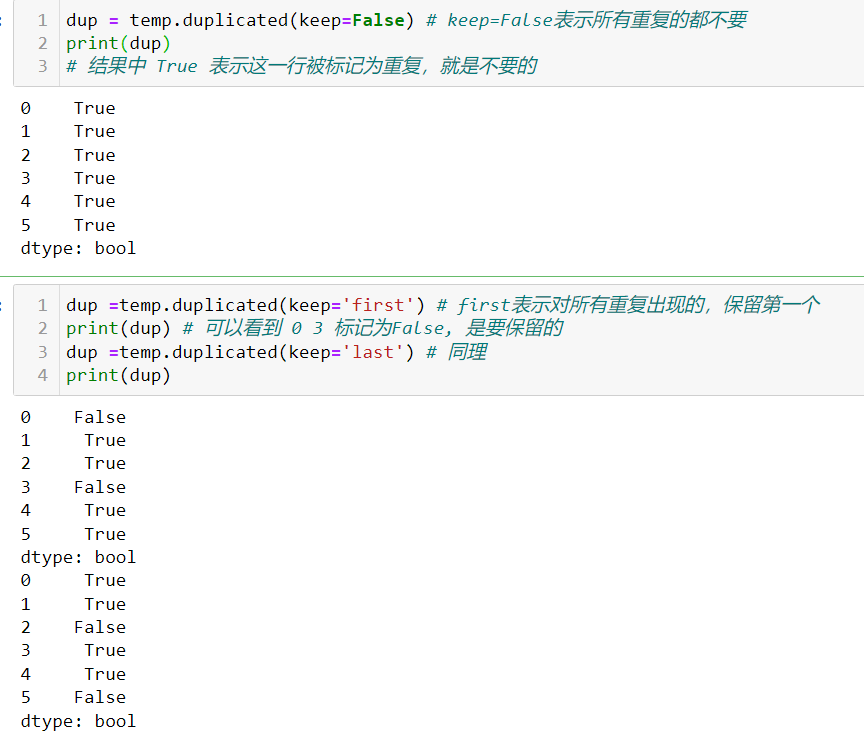
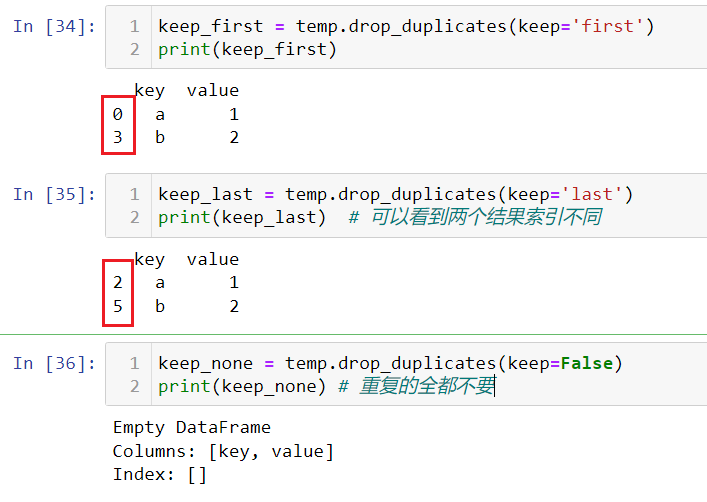
duplicated() drop_duplicates()

duplicated(keep=keep) keep说明了保留重复行中的哪些

dropna()
参考这里
df.dropna(axis=0/1, how='all'/'any', inplace=True/False)
axis=0 表示对行进行检查,axis=1表示对列进行检查
all 表示整行或整列都为na才删除;any表示只要有na就删除。
data = pandas.read_csv(file_name) # type(data) is DataFrame
del data[COL_NAME] # 从data中删除COL_NAME列
data.dropna(axis=0, how='any', inplace=True) # 删除包含空值的行
#删除前可先用 isnull()判断一下
# data[COL_NAME].isnull() 统计该属性为空的行
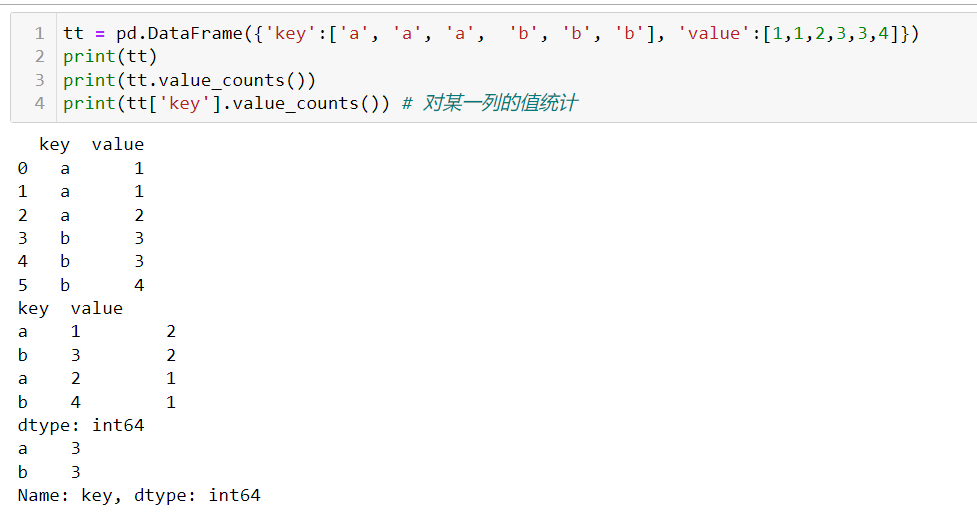
value_counts()
get_dummies
groupby resample to_datetime .etc
标准化
from sklearn.preprocessing import StandardScaler
sc = StandardScaler() # StandardScaler 对象,用于进行标准差标准化的初始化
df = sc.fit_transform(data.iloc[:,3:]) # 对括号中的参数进行标准化
# 将数据集划分为训练集 和 测试集
xtrain, xval, ytrain, yval = train_test_split(df, data['label'],
test_size=0.2, random_state=2021)
# 模型构建,模型初始化,使用LightGBM库中的LGBMClassifier类进行基于梯度提升决策树(GBDT)算法的分类
model_lgb = lightgbm.LGBMClassifier(n_estimators=1000, # 训练次数
max_depth=8, # 树的深度
num_leaves=25, # 树的最大叶子树
colsample_bytree=0.5, # 特征采样率
learning_rate=0.1, # 学习速率
metric='auc' # 模型评价指标
)
# 执行模型训练,用于拟合(训练)LightGBM模型
model_lgb.fit(xtrain, ytrain, # 训练数据的特征(输入),训练数据的标签(输出)。
eval_metric='auc',
# 验证的评价指标,评价指标使用'AUC'(Area Under the Curve)来衡量模型性能。您可以根据需要选择其他评价指标,如准确率('accuracy')或对数损失('logloss')等
eval_set=[(xtrain, ytrain), (xval, yval)], # 验证数据集的设置。在训练过程中,将使用验证数据集来监测模型的性能。第一个元组是训练数据集,第二个元组是验证数据集
verbose=True, # 是否打印训练信息,例如每棵树的评估结果。
early_stopping_rounds=100 # 多少次模型精度没有提升时,模型停止训练,以避免过拟合。
)
# 模型评价,model_lgb可能是一个已经训练好的LightGBM模型,而best_score_则是该模型在训练过程中获得的最佳得分。
print(model_lgb.best_score_)
# 预测标签
pres = model_lgb.predict(xval)
print(pres)
# 预测是否重复购买的概率
presprob = model_lgb.predict_proba(xval)[:, 1]
# predict_proba是LightGBM模型的一个方法,用于返回每个样本属于各个类别的概率。在这里,[:,1]表示取所有行的第二列,即取出预测为正类的概率。
print(presprob)
#####################
print(confusion_matrix(labels, predict_labels))
#####################
# 输出 confusion matrix 来衡量模型性能
# 预测为正类 预测为负类
#真实为正类 TP FN
#真实为负类 FP TN
print(classification_report(labels, predict_labels))
# 用于生成分类模型的分类报告,包括准确率(precision)、召回率(recall)、F1-score、支持数(support)等指标
print('准确率:', precision_score(labels, predict_labels)) # 类似有 recall_score(labels, predict_labels)
print('F1值:', f1_score(labels, predict_labels)) # F1 分数 = 2 * (精确率 * 召回率) / (精确率 + 召回率)
print('AUC值:', roc_auc_score(labels, presprob))
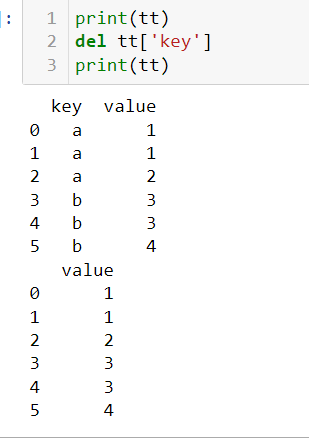
del
删除某些变量,也可以是变量的某一部分
参考资料
拣着可能会考的看一下就好,结合他们给的例子
set_index: 参考
set_index(COL)默认参数中drop=True.
reset_index()中默认参数drop=False.
groupby(COL).agg(‘mean’): 参考
groupby()的结果不能直接查看,实际上是按照COL分组后的若干个dataframe。分组后还要用 .agg({'salary':'median','age':'mean'})这样进行聚合操作。
可以给不同的列设置不同的聚合操作。


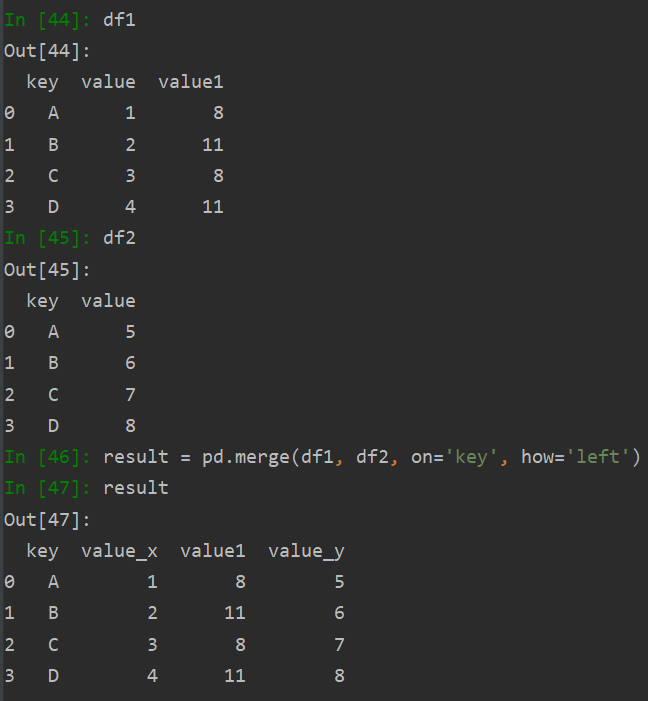
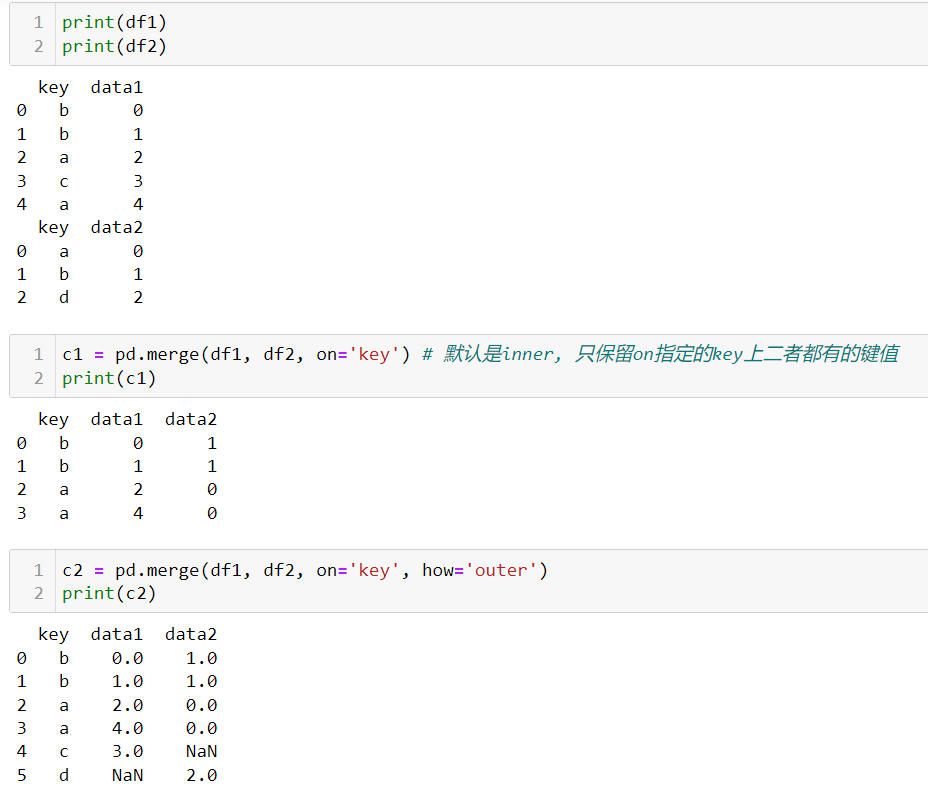
pandas.merge(left_df, right_df, on=‘COL’, how='left):
参考1同时对比了merge concat join,知道几个参数就行
参考2
调用时,分别是
pd.merge(df1, df2, ...)
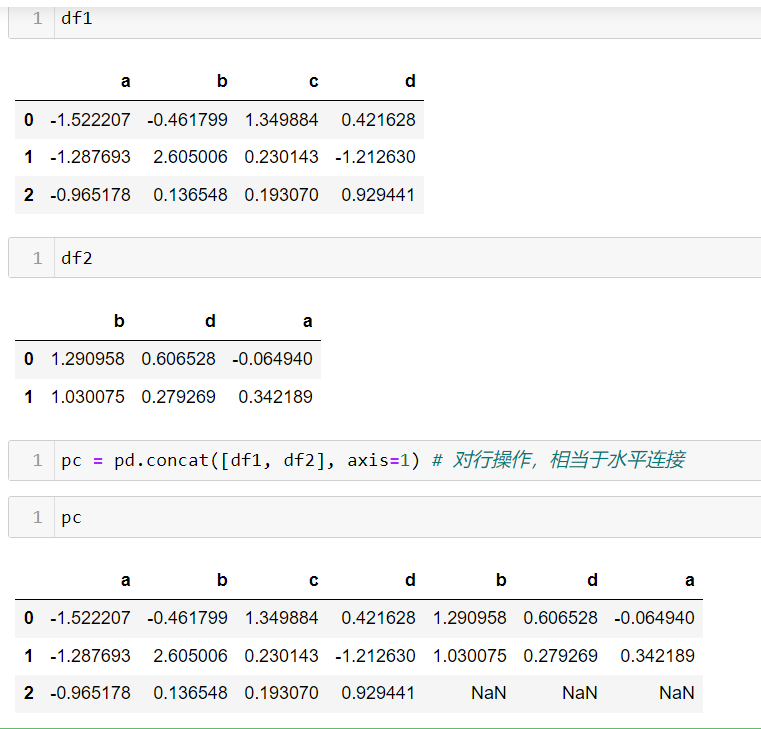
pd.concat([df1, df2], axis=0) # 对行操作,相当于水平连接
df1.join(df2, ...)
concat例子
merge例子
pd.merge(left, right, on=COL, how=how)
how表示连接方式, left, right, inner, outer
left表示保留left表信息
right表示保留right表信息
inner表示保留left right交集信息
outer表示保留二者并集信息

pandas检查行、列是否有缺失值
https://blog.youkuaiyun.com/gqyann/article/details/104919020
[455]pandas.DataFrame基本操作及缺失值处理 https://blog.youkuaiyun.com/xc_zhou/article/details/84993074
查看、删除重复元素
https://blog.youkuaiyun.com/weixin_44943394/article/details/103930179
数据清洗(重复、缺失、异常) https://zhuanlan.zhihu.com/p/493672291
pandas数据日期函数之date_range()、resample()与to_period() https://blog.youkuaiyun.com/m0_69435474/article/details/124339573

















 3663
3663

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









