



基于深度学习的智能水果分类系统设计
一、题目背景
随着人们对健康饮食的关注度不断提高,水果作为一种重要的营养食品备受青睐。然而,在市场上存在大量的水果品种和品质差异,消费者往往难以准确地识别和选择水果。因此,开发一个基于深度学习的智能水果分类系统成为了迫切的需求。
二、设计需求
基于深度学习的智能水果分类系统需要满足以下设计需求:
1、数据集收集和划分:系统需要具备数据集收集和划分的功能,收集包含各种水果的图像数据,并对这些图片进行划分,分为训练集和测试集。
2、模型选择和训练:系统需要选择适合水果分类任务的深度学习模型,并使用标注好的数据对模型进行训练。模型训练需要考虑到准确性和效率,以便在实时应用中提高系统的响应速度。
3、特征提取和分类:系统需要实现对水果图像的特征提取和分类功能。通过提取水果图像的特征表示,并通过分类器将特征映射到具体的水果类别,实现水果的自动分类。
4、用户界面设计:系统需要拥有一个用户友好的界面,并展示水果的分类结果和相关信息。
5、可扩展性和稳定性:系统需要具备良好的可扩展性,以便适应未来不断增加的水果品种和新的特征。同时,系统需要具备高效的计算能力和稳定的运行环境,保障用户体验。
通过满足以上设计需求,基于深度学习的智能水果分类系统将能够准确、快速地为用户提供水果分类和相关信息。
三、设计环境
设备:笔记本电脑
系统:Windows11
软件:Pycharm、python3.9
深度学习框架:TensorFlow2.3
深度学习模型:卷积神经网络CNN、MobileNet模型
UI界面设计:pyqt5
四、用例描述
以下是基于深度学习的智能水果分类系统的几个典型用例分析:
1、水果识别:用户可以通过上传或拍摄水果图像的方式,使用智能水果分类系统进行水果识别。系统根据图像的特征提取和分类算法,快速准确地判断水果的种类,并返回相应的结果,帮助用户辨识水果。
2、购买建议:智能水果分类系统不仅可以提供水果的分类和营养信息,还可以结合市场价格和用户需求给出购买建议。系统可以推荐性价比较高的水果品种,帮助用户在购买时做出更明智的选择。
3、品质鉴别:除了识别水果的种类,智能水果分类系统还可以对水果的品质进行鉴别。通过分析水果的外观特征,如颜色、形状、表面纹理等,系统可以评估水果的成熟度和新鲜度,帮助用户选购优质的水果。
4、水果收藏和管理:智能水果分类系统可以提供水果收藏和管理的功能。用户可以将已识别的水果保存到个人收藏夹中,记录水果的种类、购买时间等信息,方便用户追踪水果的摄入情况和管理饮食健康。
5、数据分析和统计:智能水果分类系统还可以对用户的水果摄入进行数据分析和统计。系统可以根据用户上传的水果图像和相关信息,生成饮食摄入报告,帮助用户了解自己的饮食习惯,并给予相应的改善建议。
通过以上几个典型用例,基于深度学习的智能水果分类系统可以满足用户识别水果、获取营养信息、获得购买建议等多种需求,提供便捷准确的水果分类服务,促进用户健康饮食和生活方式的改善。
五、流程图
5.1 传统图像识别原理
传统的水果图像识别系统的一般过程如下图1所示,主要工作集中在图像预处理和特征提取阶段。
在大多数的识别任务中,实验所用图像往往是在严格限定的环境中采集的,消除了外界环境对图像的影响。但是实际环境中图像易受到光照变化、水果反光、遮挡等因素的影响,这在不同程度上影响着水果图像的识别准确率。
在传统的水果图像识别系统中,通常是对水果的纹理、颜色、形状等特征进行提取和识别。

图1 传统图像识别过程
5.2 深度学习水果识别
卷积神经网络CNN是一种专门为识别二维特征而设计的多层神经网络,它的结构如下图2、3所示,这种结构对平移、缩放、旋转等变形具有高度的不变性。
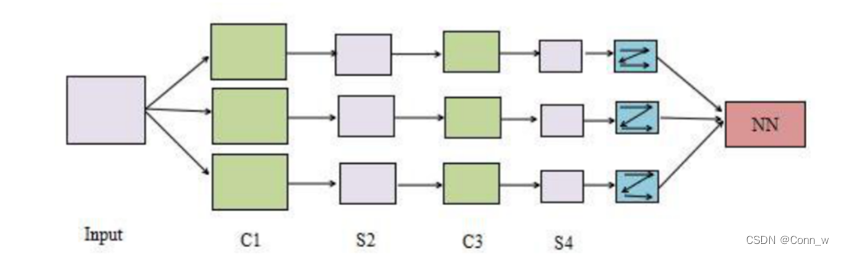
图2 CNN结构图
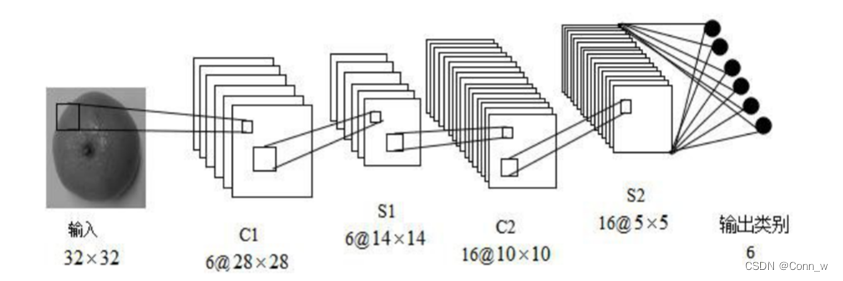
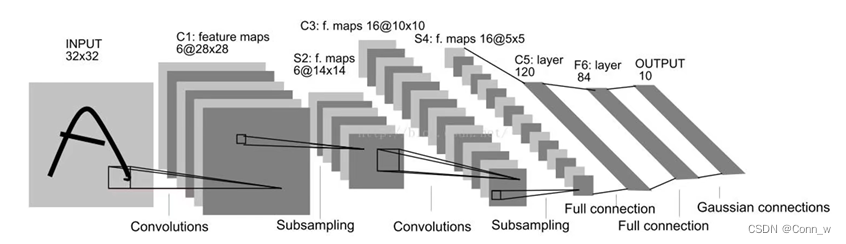
图3 CNN架构
5.3 系统流程图
利用深度学习进行水果识别分类是一种常见的计算机视觉任务,下面是一个基本的步骤来实现这个任务:
1、数据收集:收集大量的水果图像数据集,确保各个类别的水果都有足够的样本。这些图像应该包含不同角度、不同大小和不同背景的水果。
2、数据预处理:对数据进行预处理以准备训练。这包括图像重采样、大小调整、灰度化或彩色处理等。还可以考虑使用数据增强技术,如旋转、平移、缩放等,以扩充数据集。
3、构建深度学习模型:选择适合水果识别分类的深度学习模型,如卷积神经网络(CNN)。CNN在图像分类任务中表现良好。
4、模型训练:使用准备好的数据集对深度学习模型进行训练。将数据集分为训练集和验证集,使用训练集来训练模型,使用验证集来评估模型性能并进行调优。
5、模型评估:使用测试集对训练好的模型进行评估,计算分类准确率、精确率、召回率等指标。根据评估结果来判断模型的性能。
6、模型应用:将训练好的模型应用到实际场景中进行水果识别分类。输入一张待分类的水果图像,通过模型进行预测,得到水果的类别标签。
流程图如下图4所示,

图4 深度学习过程
系统流程图如下图5所示,

图5 系统流程图
六、详细设计
6.1 代码结构
主要是通过Tensorflow训练两组模型来执行分类任务,模型的结构如下:
images目录主要是放置一些图片,包括测试的图片和UI界面使用的图片;
models目录下放置训练好的两组模型,分别是CNN模型和MobileNet的模型;
results目录下放置的是训练的训练过程的一些可视化的图,两个图是两个模型训练过程中训练集和验证集准确率和loss变化曲线;
get_data.py 爬虫程序,可以爬取百度的图片;
window.py 是界面文件,主要是利用pyqt5完成的界面,通过上传图片可以对图片种类进行预测;
testmodel.py是测试文件,主要是用于测试两组模型在验证集上的准确率;
train_cnn.py是训练CNN模型的代码;
train_mobilenet.py 是训练MobileNet模型的代码;
requirements.txt是本项目需要的包。
6.2 模型构建与训练
1、使用tf.keras.preprocessing.image_dataset_from_directory直接从指定的目录中加载数据集并统一处理为指定的大小,代码如下:
# 数据集加载函数,指明数据集的位置并统一处理为imgheight*imgwidth的大小,同时设置batch
def data_load(data_dir, test_data_dir, img_height, img_width, batch_size):
# 加载训练集
train_ds = tf.keras.preprocessing.image_dataset_from_directory(
data_dir,
label_mode='categorical',
seed=123,
image_size=(img_height, img_width),
batch_size=batch_size)
# 加载测试集
val_ds = tf.keras.preprocessing.image_dataset_from_directory(
test_data_dir,
label_mode='categorical',
seed=123,
image_size=(img_height, img_width),
batch_size=batch_size)
class_names = train_ds.class_names
# 返回处理之后的训练集、验证集和类名
return train_ds, val_ds, class_names
2、模型的构建方面借助keras来完成,只需要将需要的层叠加到一起,并指明我们所需的优化器和损失函数即可,代码如下:
# 构建CNN模型
def model_load(IMG_SHAPE=(224, 224, 3), class_num=6):
# 搭建模型
model = tf.keras.models.Sequential([
# 对模型做归一化的处理,将0-255之间的数字统一处理到0到1之间
tf.keras.layers.experimental.preprocessing.Rescaling(1. / 255, input_shape=IMG_SHAPE),
# 卷积层,该卷积层的输出为32个通道,卷积核的大小是3*3,激活函数为relu
tf.keras.layers.Conv2D(32, (3, 3), activation='relu'),
# 添加池化层,池化的kernel大小是2*2
tf.keras.layers.MaxPooling2D(2, 2),
# Add another convolution
# 卷积层,输出为64个通道,卷积核大小为3*3,激活函数为relu
tf.keras.layers.Conv2D(64, (3, 3), activation='relu'),
# 池化层,最大池化,对2*2的区域进行池化操作
tf.keras.layers.MaxPooling2D(2, 2),
# 将二维的输出转化为一维
tf.keras.layers.Flatten(),
# The same 128 dense layers, and 10 output layers as in the pre-convolution example:
tf.keras.layers.Dense(128, activation='relu'),
# 通过softmax函数将模型输出为类名长度的神经元上,激活函数采用softmax对应概率值
tf.keras.layers.Dense(class_num, activation='softmax')
])
# 输出模型信息
model.summary()
# 指明模型的训练参数,优化器为sgd优化器,损失函数为交叉熵损失函数
model.compile(optimizer='sgd', loss='categorical_crossentropy', metrics=['accuracy'])
# 返回模型
return model
# 构建mobilenet模型
# 模型加载,指定图片处理的大小和是否进行迁移学习
def model_load(IMG_SHAPE=(224, 224, 3), class_num=12):
# 微调的过程中不需要进行归一化的处理
# 加载预训练的mobilenet模型
base_model = tf.keras.applications.MobileNetV2(input_shape=IMG_SHAPE,
include_top=False, weights='imagenet')
# 将模型的主干参数进行冻结
base_model.trainable = False
model = tf.keras.models.Sequential([
# 进行归一化的处理
tf.keras.layers.experimental.preprocessing.Rescaling(1. / 127.5, offset=-1, input_shape=IMG_SHAPE),
# 设置主干模型
base_model,
# 对主干模型的输出进行全局平均池化
tf.keras.layers.GlobalAveragePooling2D(),
# 通过全连接层映射到最后的分类数目上
tf.keras.layers.Dense(class_num, activation='softmax')
])
model.summary()
# 模型训练的优化器为adam优化器,模型的损失函数为交叉熵损失函数
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
return model
3、训练的主流程中,先加载数据,再加载模型,最后将数据送入模型中进行训练,使用的是model.fit函数,可以自由指定训练的轮数,最终模型会保存在models目录下,训练过程中的可视化结果会保存在reuslts目录下,代码如下:
def train(epochs):
# 开始训练,记录开始时间
begin_time = time()
# 加载数据集
train_ds, val_ds, class_names = data_load("../data/vegetable_fruit/image_data",
"../data/vegetable_fruit/test_image_data", 224, 224, 16)
print(class_names)
# 加载模型
model = model_load(class_num=len(class_names))
# 指明训练的轮数epoch,开始训练
history = model.fit(train_ds, validation_data=val_ds, epochs=epochs)
# 保存模型
model.save("models/cnn_fv.h5")
# 记录结束时间
end_time = time()
run_time = end_time - begin_time
print('该循环程序运行时间:', run_time, "s") # 该循环程序运行时间: 1.4201874732
# 绘制模型训练过程图
show_loss_acc(history)
4、模型测试和模型训练基本一致,只是在模型加载的部分,直接调用保存好的模型即可,不在进行模型参数的调整,以CNN模型的测试为例,首先加载数据,然后加载模型,最后使用model.evaluate方法对模型进行测试。代码如下:
def test_cnn():
# 加载数据集
train_ds, val_ds, class_names = data_load("../data/vegetable_fruit/image_data",
"../data/vegetable_fruit/test_image_data", 224, 224, 16)
# 加载模型
model = tf.keras.models.load_model("models/cnn_fv.h5")
# model.summary()
# 测试
loss, accuracy = model.evaluate(val_ds)
# 输出结果
print('CNN test accuracy :', accuracy)
CNN与mobilenetV2模型训练过程如下图6所示,
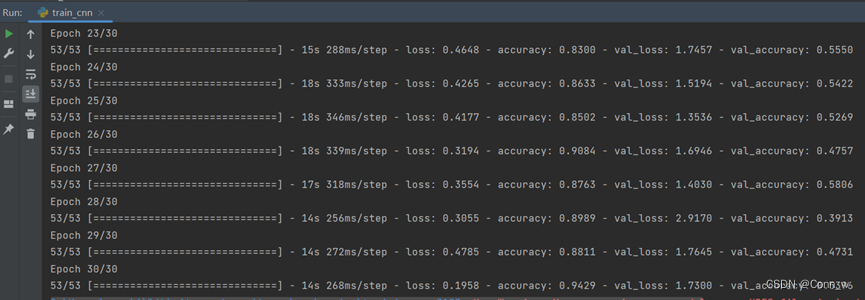
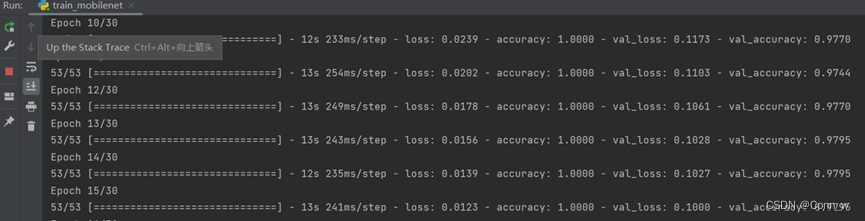
图6 cnn与mobilenet模型训练过程
6.3 运行结果与模型选择
模型运行时会记录训练数据并且结束时会在results目录下生成模型准确率和损失率曲线。测试之后在命令行中会输出每个模型的准确率,并且会在results目录下生成相应的热力图。通过数据和图片对比发现,通过Mobilenet模型训练后的识别0.97准确率要高于cnn模型的0.55,因此最终选用Mobilenet模型作为水果识别系统的预测模型。
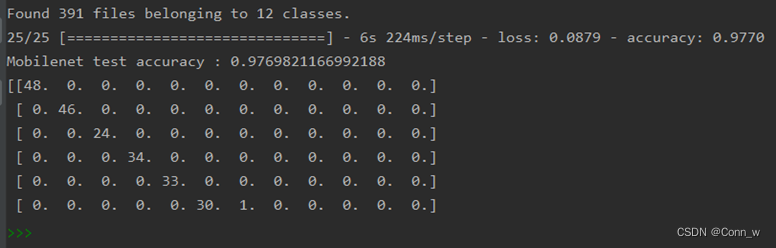
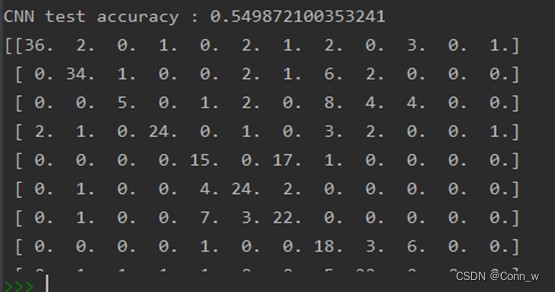
图7 测试模型准确率对比
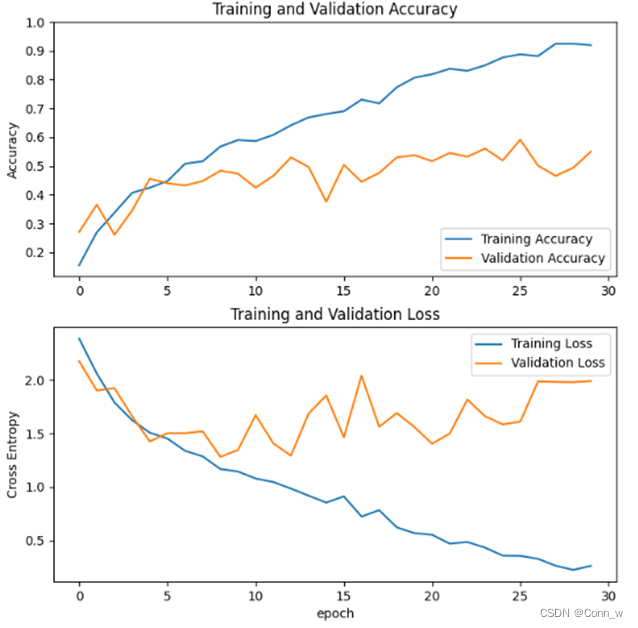
图8 cnn模型准确率和损失率曲线
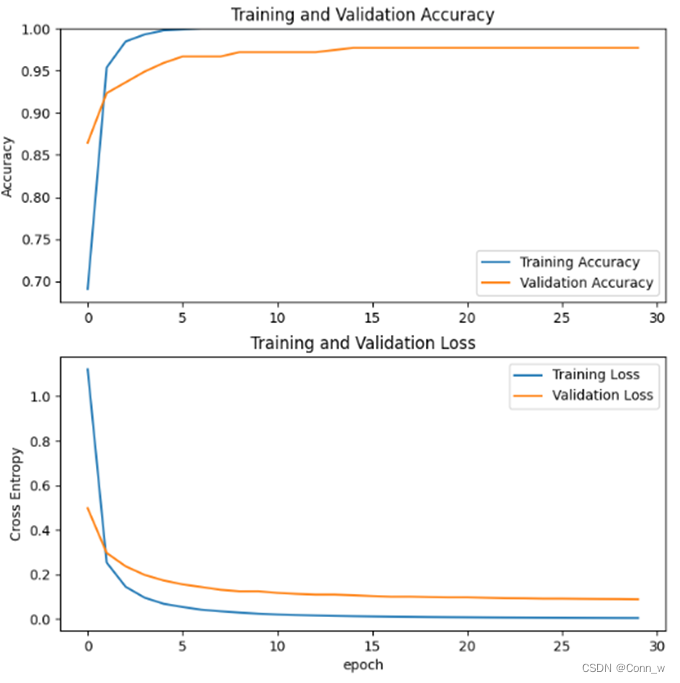
图9 mobilenet模型准确率和损失率曲线
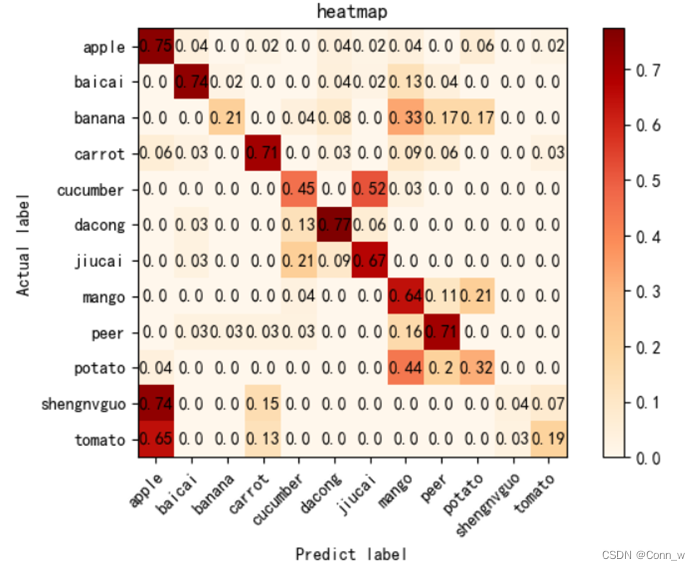
图10 cnn模型热力图
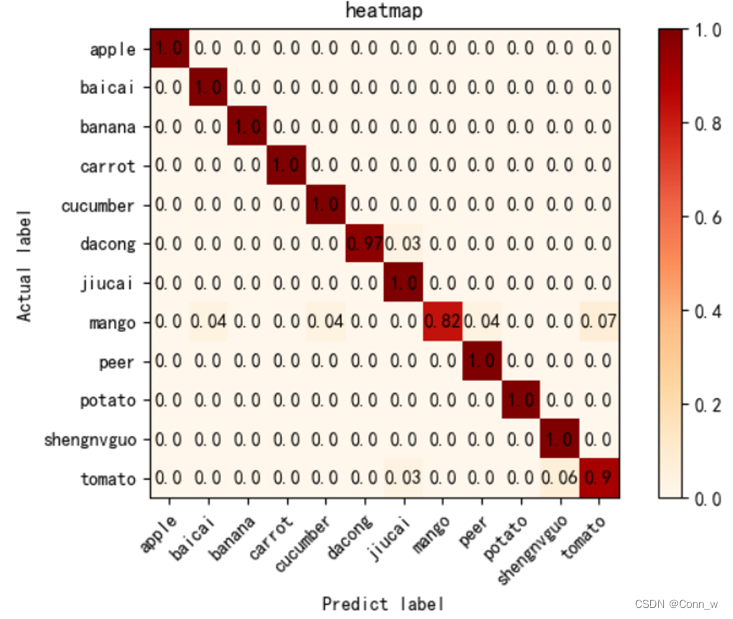
图11 mobilenet模型热力图
6.4 系统图片处理与预测
系统识别过程,通过UI界面的按钮上传图片进行识别,对图片进行统一的预处理操作, 生成可供系统识别的矩阵信息,然后调用已生成的模型进行识别并显示结果。代码如下:
# 上传并显示图片
def change_img(self):
openfile_name = QFileDialog.getOpenFileName(self, 'chose files', '',
'Image files(*.jpg *.png *jpeg)') # 打开文件选择框选择文件
img_name = openfile_name[0] # 获取图片名称
if img_name == '':
pass
else:
target_image_name = "images/tmp_up." + img_name.split(".")[-1] # 将图片移动到当前目录
shutil.copy(img_name, target_image_name)
self.to_predict_name = target_image_name
img_init = cv2.imread(self.to_predict_name) # 打开图片
h, w, c = img_init.shape
scale = 400 / h
img_show = cv2.resize(img_init, (0, 0), fx=scale, fy=scale) # 将图片的大小统一调整到400的高,方便界面显示
cv2.imwrite("images/show.png", img_show)
img_init = cv2.resize(img_init, (224, 224)) # 将图片大小调整到224*224用于模型推理
cv2.imwrite('images/target.png', img_init)
self.img_label.setPixmap(QPixmap("images/show.png"))
self.result.setText("等待识别")
# 预测图片
def predict_img(self):
img = Image.open('images/target.png') # 读取图片
img = np.asarray(img) # 将图片转化为numpy的数组
outputs = self.model.predict(img.reshape(1, 224, 224, 3)) # 将图片输入模型得到结果
result_index = int(np.argmax(outputs))
result = self.class_names[result_index] # 获得对应的水果名称
self.result.setText(result) # 在界面上做显示
七、系统界面
1、如图,主页左边为待识别图片,右边可以点击上传图片
2、上传图片后点击开始识别,右边区域会显示识别结果,如图:
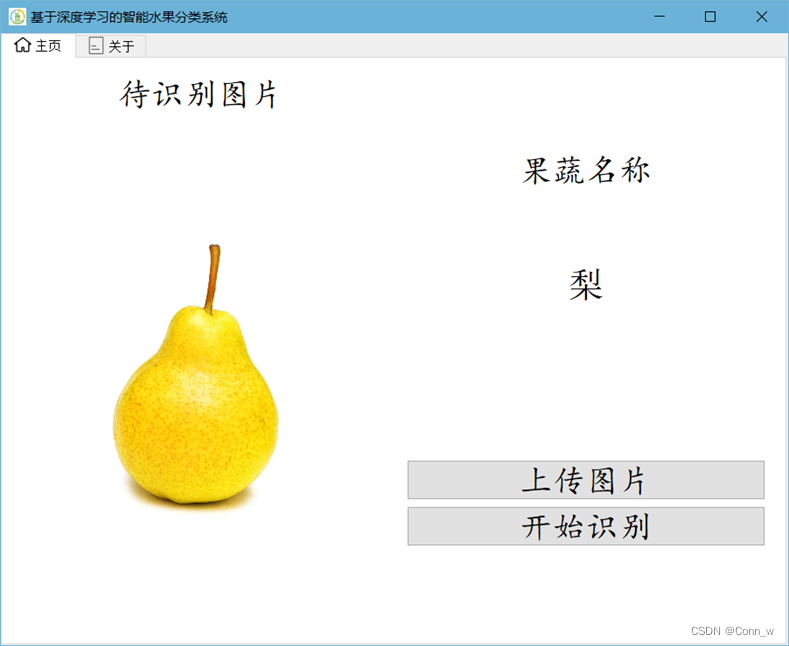
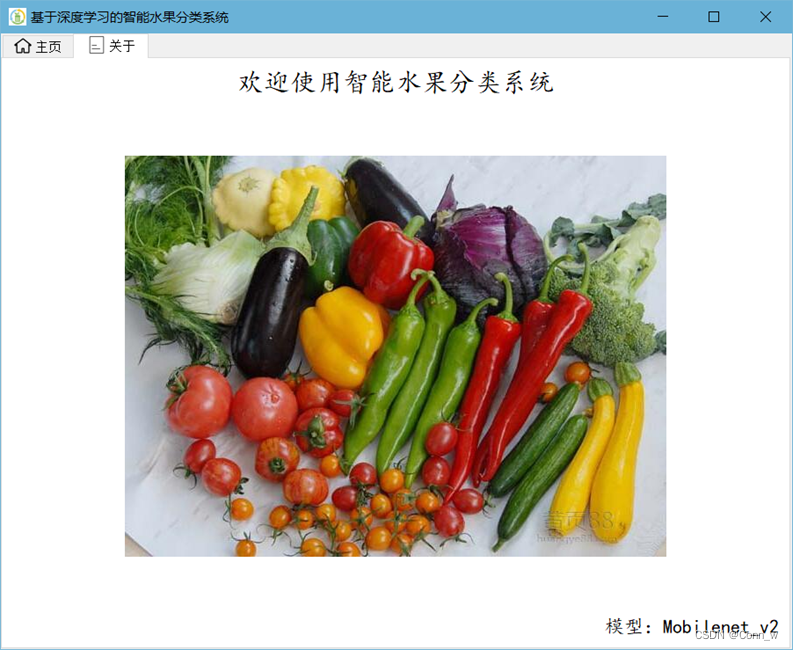
3、“关于”一栏中显示系统所使用的深度学习模型




















 598
598



 到【灌水乐园】发言
到【灌水乐园】发言









