







 本文介绍了如何在mmdetection框架下对Deformable DETR进行debug,详细阐述了从项目运行、网络框架到主要模块如ResNet50、ChannelMapper和DeformableDETR的断点调试过程。通过对各模块的深入理解,揭示了Deformable DETR在解决DETR收敛速度和小目标检测问题上的改进。
本文介绍了如何在mmdetection框架下对Deformable DETR进行debug,详细阐述了从项目运行、网络框架到主要模块如ResNet50、ChannelMapper和DeformableDETR的断点调试过程。通过对各模块的深入理解,揭示了Deformable DETR在解决DETR收敛速度和小目标检测问题上的改进。
文章目录
前言
通过对mmdetection项目实战学习,在此记录下如何通过单步调试debug,来更好的梳理整个网络的逻辑。
一、deformable-detr简介
DETR消除了目标检任务中的手工设计痕迹,但是存在收敛慢以及Transformer的自注意力造成的特征图分辨率不能太高的问题,这就导致了小目标检测性能很差。Deformable DETR只在参考点附近采样少量的key来计算注意力,因此收敛快。
论文精度可参考链接: link
论文视频讲解可参考链接:link
二、使用mmdetection对deformable-detr进行debug
2.1 项目运行
首先在mmdetection的项目文件下的configs/defromable-detr文件夹下选择deformable-detr_r50_16xb2-50e_coco.py文件,指定好数据集路径
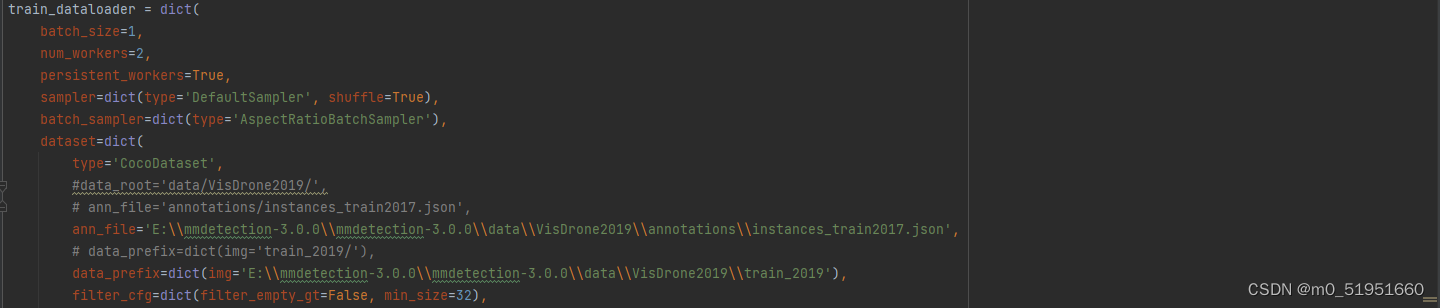
我这里采用的是visdrone2019数据集,将其转换成coco数据集格式后,修改mmdet/datasets/路径下的下coco.py的类别数后,便可运行整个项目。
具体细节见链接:link
注意需要修改数据集路径,之后将deformable-detr_r50_16xb2-50e_coco.py文件路径传入train.py后就可以debug train.py
2.2网络框架
首先我们需要了解整个项目框架是如何运行的,其与DETR的主体框架类似,如下图
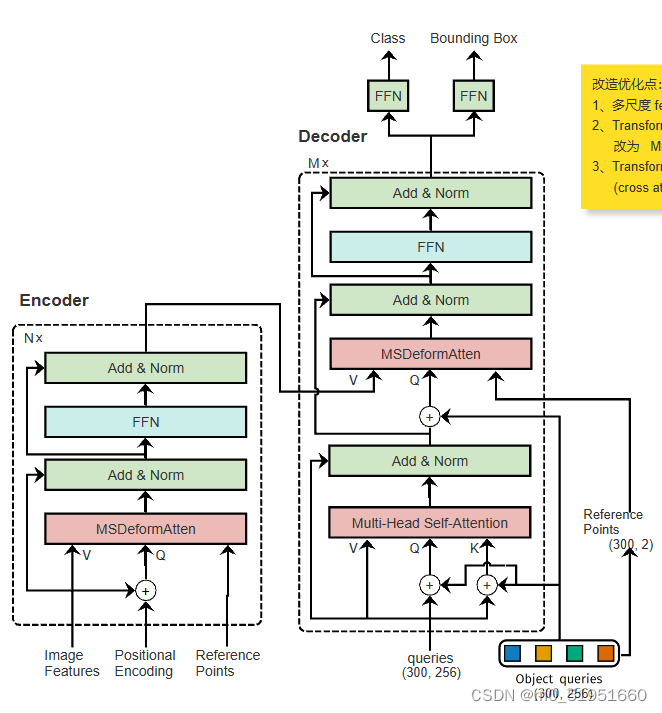
根据论文的网络结构图以及源码的model部分能够发现,其采用的检测器deformableDETR,backbone为ResNet50,neck为ChannelMapper,之后便是encoder和decoder部分
DeformableDETR(
(data_preprocessor): DetDataPreprocessor()
(backbone): ResNet(
(conv1): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(maxpool): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
(layer1): ResLayer(
(0): Bottleneck(
(conv1): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
init_cfg={'type': 'Constant', 'val': 0, 'override': {'name': 'norm3'}}
(1): Bottleneck(
(conv1): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
init_cfg={'type': 'Constant', 'val': 0, 'override': {'name': 'norm3'}}
(2): Bottleneck(
(conv1): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
init_cfg={'type': 'Constant', 'val': 0, 'override': {'name': 'norm3'}}
)
(layer2): ResLayer(
(0): Bottleneck(
(conv1): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
init_cfg={'type': 'Constant', 'val': 0, 'override': {'name': 'norm3'}}
(1): Bottleneck(
(conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
init_cfg={'type': 'Constant', 'val': 0, 'override': {'name': 'norm3'}}
(2): Bottleneck(
(conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
init_cfg={'type': 'Constant', 'val': 0, 'override': {'name': 'norm3'}}
(3): Bottleneck(
(conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
init_cfg={'type': 'Constant', 'val': 0, 'override': {'name': 'norm3'}}
)
(layer3): ResLayer(
(0): Bottleneck(
(conv1): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(512, 1024, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
init_cfg={'type': 'Constant', 'val': 0, 'override': {'name': 'norm3'}}
(1): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
init_cfg={'type': 'Constant', 'val': 0, 'override': {'name': 'norm3'}}
(2): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
init_cfg={'type': 'Constant', 'val': 0, 'override': {'name': 'norm3'}}
(3): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
init_cfg={'type': 'Constant', 'val': 0, 'override': {'name': 'norm3'}}
(4): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
init_cfg={'type': 'Constant', 'val': 0, 'override': {'name': 'norm3'}}
(5): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
init_cfg={'type': 'Constant', 'val': 0, 'override': {'name': 'norm3'}}
)
(layer4): ResLayer(
(0): Bottleneck(
(conv1): Conv2d(1024, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(1024, 2048, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
init_cfg={'type': 'Constant', 'val': 0, 'override': {'name': 'norm3'}}
(1): Bottleneck(
(conv1): Conv2d(2048, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
init_cfg={'type': 'Constant', 'val': 0, 'override': {'name': 'norm3'}}
(2): Bottleneck(
(conv1): Conv2d(2048, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
init_cfg={'type': 'Constant', 'val': 0, 'override': {'name': 'norm3'}}
)
)
init_cfg=[{'type': 'Kaiming', 'layer': 'Conv2d'}, {'type': 'Constant', 'val': 1, 'layer': ['_BatchNorm', 'GroupNorm']}]
(neck): ChannelMapper(
(convs): ModuleList(
(0): ConvModule(
(conv): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(gn): GroupNorm(32, 256, eps=1e-05, affine=True)
)
(1): ConvModule(
(conv): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(gn): GroupNorm(32, 256, eps=1e-05, affine=True)
)
(2): ConvModule(
(conv): Conv2d(2048, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(gn): GroupNorm(32, 256, eps=1e-05, affine=True)
)
)
(extra_convs): ModuleList(
(0): ConvModule(
(conv): Conv2d(2048, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(gn): GroupNorm(32, 256, eps=1e-05, affine=True)
)
)
)
init_cfg={'type': 'Xavier', 'layer': 'Conv2d', 'distribution': 'uniform'}
(bbox_head): DeformableDETRHead(
(loss_cls): FocalLoss()
(loss_bbox): L1Loss()
(loss_iou): GIoULoss()
(cls_branches): ModuleList(
(0): Linear(in_features=256, out_features=10, bias=True)
(1): Linear(in_features=256, out_features=10, bias=True)
(2): Linear(in_features=256, out_features=10, bias=True)
(3): Linear(in_features=256, out_features=10, bias=True)
(4): Linear(in_features=256, out_features=10, bias=True)
(5): Linear(in_features=256, out_features=10, bias=True)
)
(reg_branches): ModuleList(
(0): Sequential(
(0): Linear(in_features=256, out_features=256, bias=True)
(1): ReLU()
(2): Linear(in_features=256, out_features=256, bias=True)
(3): ReLU()
(4): Linear(in_features=256, out_features=4, bias=True)
)
(1): Sequential(
(0): Linear(in_features=256, out_features=256, bias=True)
(1): ReLU()
(2): Linear(in_features=256, out_features=256, bias=True)
(3): ReLU()
(4): Linear(in_features=256, out_features=4, bias=True)
)
(2): Sequential(
(0): Linear(in_features=256, out_features=256, bias=True)
(1): ReLU()
(2): Linear(in_features=256, out_features=256, bias=True)
(3): ReLU()
(4): Linear(in_features=256, out_features=4, bias=True)
)
(3): Sequential(
(0): Linear(in_features=256, out_features=256, bias=True)
(1): ReLU()
(2): Linear(in_features=256, out_features=256, bias=True)
(3): ReLU()
(4): Linear(in_features=256, out_features=4, bias=True)
)
(4): Sequential(
(0): Linear(in_features=256, out_features=256, bias=True)
(1): ReLU()
(2): Linear(in_features=256, out_features=256, bias=True)
(3): ReLU()
(4): Linear(in_features=256, out_features=4, bias=True)
)
(5): Sequential(
(0): Linear(in_features=256, out_features=256, bias=True)
(1): ReLU()
(2): Linear(in_features=256, out_features=256, bias=True)
(3): ReLU()
(4): Linear(in_features=256, out_features=4, bias=True)
)
)
)
(positional_encoding): SinePositionalEncoding(num_feats=128, temperature=10000, normalize=True, scale=6.283185307179586, eps=1e-06)
(encoder): DeformableDetrTransformerEncoder(
(layers): ModuleList(
(0): DeformableDetrTransformerEncoderLayer(
(self_attn): MultiScaleDeformableAttention(
(dropout): Dropout(p=0.1, inplace=False)
(sampling_offsets): Linear(in_features=256, out_features=256, bias=True)
(attention_weights): Linear(in_features=256, out_features=128, bias=True)
(value_proj): Linear(in_features=256, out_features=256, bias=True)
(output_proj): Linear(in_features=256, out_features=256, bias=True)
)
(ffn): FFN(
(layers): Sequential(
(0): Sequential(
(0): Linear(in_features=256, out_features=1024, bias=True)
(1): ReLU(inplace=True)
(2): Dropout(p=0.1, inplace=False)
)
(1): Linear(in_features=1024, out_features=256, bias=True)
(2): Dropout(p=0.1, inplace=False)
)
(dropout_layer): Identity()
(gamma2): Identity()
)
(norms): ModuleList(
(0): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(1): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
)
)
(1): DeformableDetrTransformerEncoderLayer(
(self_attn): MultiScaleDeformableAttention(
(dropout): Dropout(p=0.1, inplace=False)
(sampling_offsets): Linear(in_features=256, out_features=256, bias=True)
(attention_weights): Linear(in_features=256, out_features=128, bias=True)
(value_proj): Linear(in_features=256, out_features=256, bias=True)
(output_proj): Linear(in_features=256, out_features=256, bias=True)
)
(ffn): FFN(
(layers): Sequential(
(0): Sequential(
(0): Linear(in_features=256, out_features=1024, bias=True)
(1): ReLU(inplace=True)
(2): Dropout(p=0.1, inplace=False)
)
(1): Linear(in_features=1024, out_features=256, bias=True)
(2): Dropout(p=0.1, inplace=False)
)
(dropout_layer): Identity()
(gamma2): Identity()
)
(norms): ModuleList(
(0): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(1): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
)
)
(2): DeformableDetrTransformerEncoderLayer(
(self_attn): MultiScaleDeformableAttention(
(dropout): Dropout(p=0.1, inplace=False)
(sampling_offsets): Linear(in_features=256, out_features=256, bias=True)
(attention_weights): Linear(in_features=256, out_features=128, bias=True)
(value_proj): Linear(in_features=256, out_features=256, bias=True)
(output_proj): Linear(in_features=256, out_features=256, bias=True)
)
(ffn): FFN(
(layers): Sequential(
(0): Sequential(
(0): Linear(in_features=256, out_features=1024, bias=True)
(1): ReLU(inplace=True)
(2): Dropout(p=0.1, inplace=False)
)
(1): Linear(in_features=1024, out_features=256, bias=True)
(2): Dropout(p=0.1, inplace=False)
)
(dropout_layer): Identity()
(gamma2): Identity()
)
(norms): ModuleList(
(0): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(1): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
)
)
(3): DeformableDetrTransformerEncoderLayer(
(self_attn): MultiScaleDeformableAttention(
(dropout): Dropout(p=0.1, inplace=False)
(sampling_offsets): Linear(in_features=256, out_features=256, bias=True)
(attention_weights): Linear(in_features=256, out_features=128, bias=True)
(value_proj): Linear(in_features=256, out_features=256, bias=True)
(output_proj): Linear(in_features=256, out_features=256, bias=True)
)
(ffn): FFN(
(layers): Sequential(
(0): Sequential(
(0): Linear(in_features=256, out_features=1024, bias=True)
(1): ReLU(inplace=True)
(2): Dropout(p=0.1, inplace=False)
)
(1): Linear(in_features=1024, out_features=256, bias=True)
(2): Dropout(p=0.1, inplace=False)
)
(dropout_layer): Identity()
(gamma2): Identity()
)
(norms): ModuleList(
(0): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(1): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
)
)
(4): DeformableDetrTransformerEncoderLayer(
(self_attn): MultiScaleDeformableAttention(
(dropout): Dropout(p=0.1, inplace=False)
(sampling_offsets): Linear(in_features=256, out_features=256, bias=True)
(attention_weights): Linear(in_features=256, out_features=128, bias=True)
(value_proj): Linear(in_features=256, out_features=256, bias=True)
(output_proj): Linear(in_features=256, out_features=256, bias=True)
)
(ffn): FFN(
(layers): Sequential(
(0): Sequential(
(0): Linear(in_features=256, out_features=1024, bias=True)
(1): ReLU(inplace=True)
(2): Dropout(p=0.1, inplace=False)
)
(1): Linear(in_features=1024, out_features=256, bias=True)
(2): Dropout(p=0.1, inplace=False)
)
(dropout_layer): Identity()
(gamma2): Identity()
)
(norms): ModuleList(
(0): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(1): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
)
)
(5): DeformableDetrTransformerEncoderLayer(
(self_attn): MultiScaleDeformableAttention(
(dropout): Dropout(p=0.1, inplace=False)
(sampling_offsets): Linear(in_features=256, out_features=256, bias=True)
(attention_weights): Linear(in_features=256, out_features=128, bias=True)
(value_proj): Linear(in_features=256, out_features=256, bias=True)
(output_proj): Linear(in_features=256, out_features=256, bias=True)
)
(ffn): FFN(
(layers): Sequential(
(0): Sequential(
(0): Linear(in_features=256, out_features=1024, bias=True)
(1): ReLU(inplace=True)
(2): Dropout(p=0.1, inplace=False)
)
(1): Linear(in_features=1024, out_features=256, bias=True)
(2): Dropout(p=0.1, inplace=False)
)
(dropout_layer): Identity()
(gamma2): Identity()
)
(norms): ModuleList(
(0): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(1): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
)
)
)
)
(decoder): DeformableDetrTransformerDecoder(
(layers): ModuleList(
(0): DeformableDetrTransformerDecoderLayer(
(self_attn): MultiheadAttention(
(attn): MultiheadAttention(
(out_proj): NonDynamicallyQuantizableLinear(in_features=256, out_features=256, bias=True)
)
(proj_drop): Dropout(p=0.0, inplace=False)
(dropout_layer): Dropout(p=0.1, inplace=False)
)
(cross_attn): MultiScaleDeformableAttention(
(dropout): Dropout(p=0.1, inplace=False)
(sampling_offsets): Linear(in_features=256, out_features=256, bias=True)
(attention_weights): Linear(in_features=256, out_features=128, bias=True)
(value_proj): Linear(in_features=256, out_features=256, bias=True)
(output_proj): Linear(in_features=256, out_features=256, bias=True)
)
(ffn): FFN(
(layers): Sequential(
(0): Sequential(
(0): Linear(in_features=256, out_features=1024, bias=True)
(1): ReLU(inplace=True)
(2): Dropout(p=0.1, inplace=False)
)
(1): Linear(in_features=1024, out_features=256, bias=True)
(2): Dropout(p=0.1, inplace=False)
)
(dropout_layer): Identity()
(gamma2): Identity()
)
(norms): ModuleList(
(0): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(1): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(2): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
)
)
(1): DeformableDetrTransformerDecoderLayer(
(self_attn): MultiheadAttention(
(attn): MultiheadAttention(
(out_proj): NonDynamicallyQuantizableLinear(in_features=256, out_features=256, bias=True)
)
(proj_drop): Dropout(p=0.0, inplace=False)
(dropout_layer): Dropout(p=0.1, inplace=False)
)
(cross_attn): MultiScaleDeformableAttention(
(dropout): Dropout(p=0.1, inplace=False)
(sampling_offsets): Linear(in_features=256, out_features=256, bias=True)
(attention_weights): Linear(in_features=256, out_features=128, bias=True)
(value_proj): Linear(in_features=256, out_features=256, bias=True)
(output_proj): Linear(in_features=256, out_features=256, bias=True)
)
(ffn): FFN(
(layers): Sequential(
(0): Sequential(
(0): Linear(in_features=256, out_features=1024, bias=True)
(1): ReLU(inplace=True)
(2): Dropout(p=0.1, inplace=False)
)
(1): Linear(in_features=1024, out_features=256, bias=True)
(2): Dropout(p=0.1, inplace=False)
)
(dropout_layer): Identity()
(gamma2): Identity()
)
(norms): ModuleList(
(0): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(1): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(2): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
)
)
(2): DeformableDetrTransformerDecoderLayer(
(self_attn): MultiheadAttention(
(attn): MultiheadAttention(
(out_proj): NonDynamicallyQuantizableLinear(in_features=256, out_features=256, bias=True)
)
(proj_drop): Dropout(p=0.0, inplace=False)
(dropout_layer): Dropout(p=0.1, inplace=False)
)
(cross_attn): MultiScaleDeformableAttention(
(dropout): Dropout(p=0.1, inplace=False)
(sampling_offsets): Linear(in_features=256, out_features=256, bias=True)
(attention_weights): Linear(in_features=256, out_features=128, bias=True)
(value_proj): Linear(in_features=256, out_features=256, bias=True)
(output_proj): Linear(in_features=256, out_features=256, bias=True)
)
(ffn): FFN(
(layers): Sequential(
(0): Sequential(
(0): Linear(in_features=256, out_features=1024, bias=True)
(1): ReLU(inplace=True)
(2): Dropout(p=0.1, inplace=False)
)
(1): Linear(in_features=1024, out_features=256, bias=True)
(2): Dropout(p=0.1, inplace=False)
)
(dropout_layer): Identity()
(gamma2): Identity()
)
(norms): ModuleList(
(0): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(1): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(2): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
)
)
(3): DeformableDetrTransformerDecoderLayer(
(self_attn): MultiheadAttention(
(attn): MultiheadAttention(
(out_proj): NonDynamicallyQuantizableLinear(in_features=256, out_features=256, bias=True)
)
(proj_drop): Dropout(p=0.0, inplace=False)
(dropout_layer): Dropout(p=0.1, inplace=False)
)
(cross_attn): MultiScaleDeformableAttention(
(dropout): Dropout(p=0.1, inplace=False)
(sampling_offsets): Linear(in_features=256, out_features=256, bias=True)
(attention_weights): Linear(in_features=256, out_features=128, bias=True)
(value_proj): Linear(in_features=256, out_features=256, bias=True)
(output_proj): Linear(in_features=256, out_features=256, bias=True)
)
(ffn): FFN(
(layers): Sequential(
(0): Sequential(
(0): Linear(in_features=256, out_features=1024, bias=True)
(1): ReLU(inplace=True)
(2): Dropout(p=0.1, inplace=False)
)
(1): Linear(in_features=1024, out_features=256, bias=True)
(2): Dropout(p=0.1, inplace=False)
)
(dropout_layer): Identity()
(gamma2): Identity()
)
(norms): ModuleList(
(0): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(1): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(2): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
)
)
(4): DeformableDetrTransformerDecoderLayer(
(self_attn): MultiheadAttention(
(attn): MultiheadAttention(
(out_proj): NonDynamicallyQuantizableLinear(in_features=256, out_features=256, bias=True)
)
(proj_drop): Dropout(p=0.0, inplace=False)
(dropout_layer): Dropout(p=0.1, inplace=False)
)
(cross_attn): MultiScaleDeformableAttention(
(dropout): Dropout(p=0.1, inplace=False)
(sampling_offsets): Linear(in_features=256, out_features=256, bias=True)
(attention_weights): Linear(in_features=256, out_features=128, bias=True)
(value_proj): Linear(in_features=256, out_features=256, bias=True)
(output_proj): Linear(in_features=256, out_features=256, bias=True)
)
(ffn): FFN(
(layers): Sequential(
(0): Sequential(
(0): Linear(in_features=256, out_features=1024, bias=True)
(1): ReLU(inplace=True)
(2): Dropout(p=0.1, inplace=False)
)
(1): Linear(in_features=1024, out_features=256, bias=True)
(2): Dropout(p=0.1, inplace=False)
)
(dropout_layer): Identity()
(gamma2): Identity()
)
(norms): ModuleList(
(0): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(1): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(2): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
)
)
(5): DeformableDetrTransformerDecoderLayer(
(self_attn): MultiheadAttention(
(attn): MultiheadAttention(
(out_proj): NonDynamicallyQuantizableLinear(in_features=256, out_features=256, bias=True)
)
(proj_drop): Dropout(p=0.0, inplace=False)
(dropout_layer): Dropout(p=0.1, inplace=False)
)
(cross_attn): MultiScaleDeformableAttention(
(gamma2): Identity()
)
(norms): ModuleList(
(0): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(1): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(2): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
)
)
)
)
)
)
(query_embedding): Embedding(300, 512)
(reference_points_fc): Linear(in_features=256, out_features=2, bias=True)
)
三、主要模块的断点及debug
3.1 Backbone : resnet50
进入到mmdet/models/backbones/resnet.py文件中,在其resnet类中的前向传播打上断点。如果不会找类在哪个文件可以选中调用的类,shift+cltr+f进行搜索
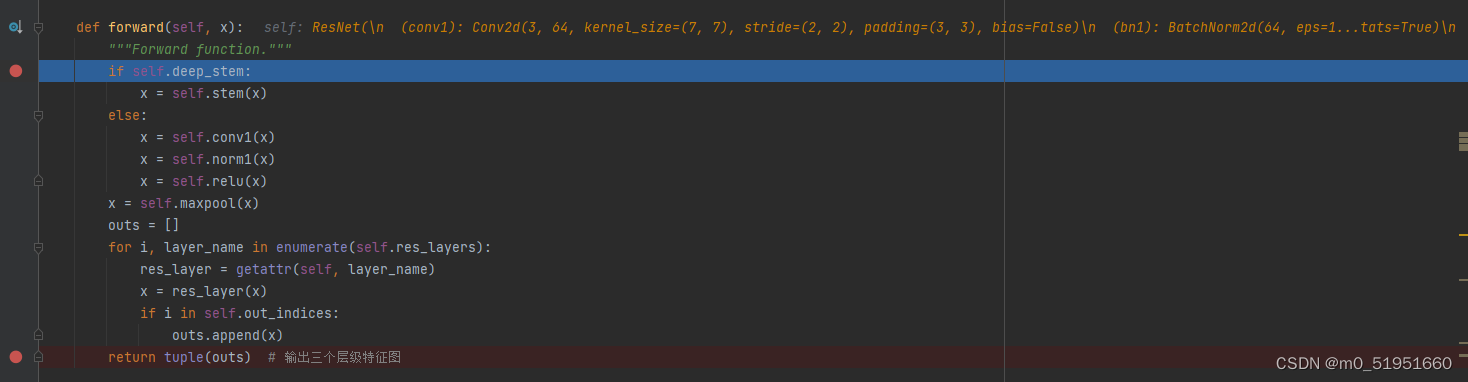 x.shape是我们输入图像的(batch,channel,h w),self调用的是resnet50网络结构,通过索引out_indices来决定从resnet50中的哪几个stage输出特征图,out_indices=(1, 2, 3)这里是从1,2,3状态分别输出特征图,即outs[]
x.shape是我们输入图像的(batch,channel,h w),self调用的是resnet50网络结构,通过索引out_indices来决定从resnet50中的哪几个stage输出特征图,out_indices=(1, 2, 3)这里是从1,2,3状态分别输出特征图,即outs[]

3.2 Neck:channel_mapper
3.3 DeformableDETR
进入到mmdet/models/detectors/deformable_detr.py文件找到 DeformableDETR(DetectionTransformer)类,也就是我们的检测器。
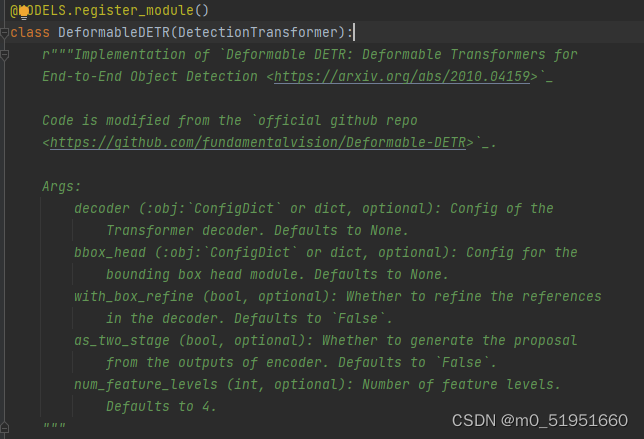 往下滑可以找到pre_transformer部分,在注释下面第一行程序打上断点。pre_transformer部分其需要的参数为mlvl_feats(neck层最后输出的4个层级特征图)以及batch_data_samples。
往下滑可以找到pre_transformer部分,在注释下面第一行程序打上断点。pre_transformer部分其需要的参数为mlvl_feats(neck层最后输出的4个层级特征图)以及batch_data_samples。
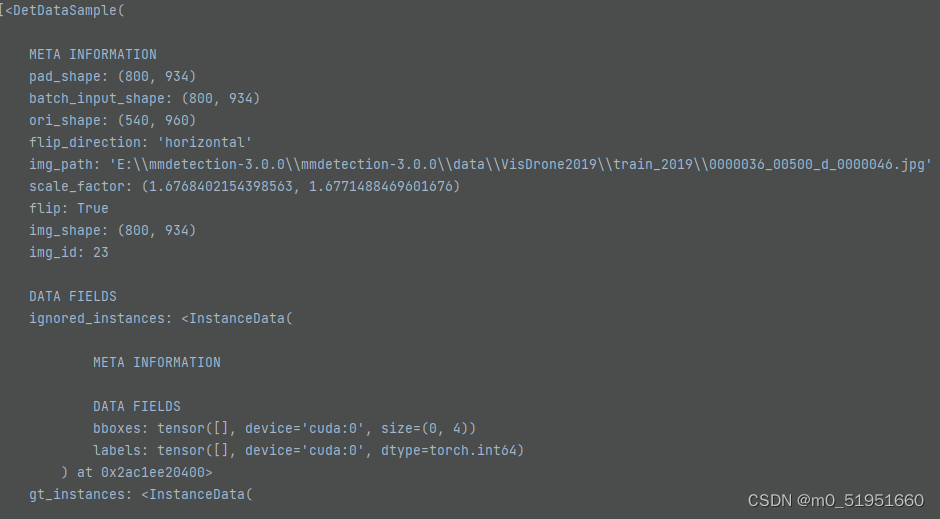
mlvl_feats如下:

batch_data_samples(批处理数据样本),其中内容有图像大小:800x943,初始大小:540x960,图像中gt_box的4个参数以及类别
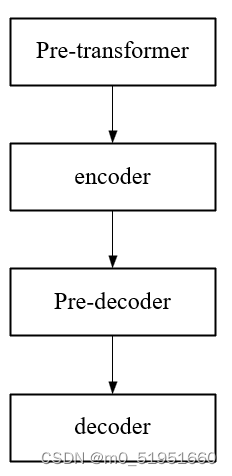
同时在注释中可以发现transformer的前向传播路径为:
通过打上断点对pre-transformer部分进行debug,可以得到
batch_size = mlvl_feats[0].size(0) # 从neck层输出的 mlvl_feats 多层级特征(4)
# construct binary masks for the transformer.
assert batch_data_samples is not None
batch_input_shape = batch_data_samples[0].batch_input_shape
# batch_input_shape(800,943)
img_shape_list = [sample.img_shape for sample in batch_data_samples]
input_img_h, input_img_w = batch_input_shape
masks = mlvl_feats[0].new_ones((batch_size, input_img_h, input_img_w))
for img_id in range(batch_size):
img_h, img_w = img_shape_list[img_id]
masks[img_id, :img_h, :img_w] = 0
# NOTE following the official DETR repo, non-zero values representing
# ignored positions, while zero values means valid positions.
mlvl_masks = []
mlvl_pos_embeds = []
for feat in mlvl_feats:
mlvl_masks.append( # 遍历四个层级特征,从而生成mlvl_masks,即四个层级的mask
F.interpolate(masks[None],
size=feat.shape[-2:]).to(torch.bool).squeeze(0))
mlvl_pos_embeds.append(self.positional_encoding(mlvl_masks[-1]))
feat_flatten = []
lvl_pos_embed_flatten = []
mask_flatten = []
spatial_shapes = []
for lvl, (feat, mask, pos_embed) in enumerate(
zip(mlvl_feats, mlvl_masks, mlvl_pos_embeds)):
batch_size, c, h, w = feat.shape
# [bs, c, h_lvl, w_lvl] -> [bs, h_lvl*w_lvl, c]即feat (1,256,50,59)变为(1,2950,256)
feat = feat.view(batch_size, c, -1).permute(0, 2, 1)
pos_embed = pos_embed.view(batch_size, c, -1).permute(0, 2, 1)
lvl_pos_embed = pos_embed + self.level_embed[lvl].view(1, 1, -1)
# [bs, h_lvl, w_lvl] -> [bs, h_lvl*w_lvl]
mask = mask.flatten(1)
spatial_shape = (h, w) # 特征图的(h,w)
feat_flatten.append(feat)
lvl_pos_embed_flatten.append(lvl_pos_embed)
mask_flatten.append(mask)
spatial_shapes.append(spatial_shape)
# (bs, num_feat_points, dim)
feat_flatten = torch.cat(feat_flatten, 1) # 将四个特征图拉长拼接在一起
lvl_pos_embed_flatten = torch.cat(lvl_pos_embed_flatten, 1)
# (bs, num_feat_points), where num_feat_points = sum_lvl(h_lvl*w_lvl)
mask_flatten = torch.cat(mask_flatten, 1)
spatial_shapes = torch.as_tensor( # (num_level, 2)
spatial_shapes,
dtype=torch.long,
device=feat_flatten.device)
level_start_index = torch.cat((
spatial_shapes.new_zeros((1, )), # (num_level)
spatial_shapes.prod(1).cumsum(0)[:-1]))
valid_ratios = torch.stack( # (bs, num_level, 2)
[self.get_valid_ratio(m) for m in mlvl_masks], 1)
encoder_inputs_dict = dict(
feat=feat_flatten, # shape(1,5624,256) 将四个特征图拉长拼接在一起得到
feat_mask=mask_flatten, # shape(1,5624)将四个不同特征图的mask拉长拼接在一起得到
feat_pos=lvl_pos_embed_flatten, # shape(1,5624,256)将四个不同特征图的position_emding 拉长拼接在一起
spatial_shapes=spatial_shapes, # shape(4,2)代表四个层级,每个层级的两个维度
level_start_index=level_start_index, # shape(4) 不同特征层在拉长序列中的起始位置
valid_ratios=valid_ratios) # shape(1,4,2)
decoder_inputs_dict = dict(
memory_mask=mask_flatten,
spatial_shapes=spatial_shapes,
level_start_index=level_start_index,
valid_ratios=valid_ratios)
return encoder_inputs_dict, decoder_inputs_dict
关于valid_ratio的分析:

这里这张图可以是 batch_input,也可以是任意一个 level 的 feature。如果用 real_feat 表示没有被 padding 的部分,用 padded_feat 表示整个padding后的图。那么valid_ratio 可以理解为 real_feat 的宽高比 padded_feat 的宽高。由于本任务中输入的batch为1(即输入一张图像),因此不会存在填充(padding),所以vaild_ratios为1。
关于mask的分析:
(1)创建:在 pre_encoder() 中根据 batch_data_samples 的信息构建了这个 mask。
(2)原因:DETR允许输入的 batch 中的图片具有不同的尺寸,对于不同尺寸的图片,会在两张图的右侧和下侧 padding,来对齐两张图的尺寸,但是 padding 的部分毕竟不是图像部分,且DETR需要对图像进行位置编码,如果不知道哪里是padding的部分可能会影响位置编码。在计算attention的时候,Transformer也不应该关注这些padding的部分。因此DETR 用 掩码 mask 记录了 padding 的位置。
reference point的确定
在Encoder中,reference point确定方法为用了torch.meshgrid方法,调用的函数如下(get_reference_points),将四个层级的特征图中每个特征图中的特征点取坐标,将其归一化,再拼接在一起后得到reference_points.
# 获取各层特征图中每个像素点相对于Vaild值的相对坐标作为reference_points
reference_points_list = []
for lvl, (H, W) in enumerate(spatial_shapes): # 对四个层级取坐标
ref_y, ref_x = torch.meshgrid(
torch.linspace(
0.5, H - 0.5, H, dtype=torch.float32, device=device), # H,W为不同层级特征图的高和宽
torch.linspace(
0.5, W - 0.5, W, dtype=torch.float32, device=device))
# 对取出的坐标做归一化
ref_y = ref_y.reshape(-1)[None] / (
valid_ratios[:, None, lvl, 1] * H)
ref_x = ref_x.reshape(-1)[None] / (
valid_ratios[:, None, lvl, 0] * W)
ref = torch.stack((ref_x, ref_y), -1) # 得到不同层级归一化后的相对坐标位置
reference_points_list.append(ref) # 得到四个层级特征图的相对坐标位置(四个列表)
reference_points = torch.cat(reference_points_list, 1) # 将四个层级的相对坐标位置拼接到一起,其shape为(bs, sum(hw), 2)
# 拼接得到的序列上的坐标对应于四个特征图上的相对坐标可能是小数,特征图上的相对坐标周围的四个像素点通过双线性插值来得到对应于序列上的坐标的特征
reference_points = reference_points[:, :, None] * valid_ratios[:, None] # None表示新加一个维度,实现两者相乘,由于valid_ratios为1,即类似复制操作,当输入batch不为1,即valid_ratios不为1时,两者相乘表示采样点在真实特征图上的位置
# [bs, sum(hw), num_level, 2] (batch,四个层级特征图的相对位置坐标的总长度,4个层级对序列中的相对坐标贡献特征,相对坐标位置的x,y)
return reference_points
而在Decoder中,参考点的获取方法为object queries通过一个nn.Linear得到每个对应的reference point。
enc_outputs_class, enc_outputs_coord = None, None
query_embed = self.query_embedding.weight
query_pos, query = torch.split(query_embed, c, dim=1)
query_pos = query_pos.unsqueeze(0).expand(batch_size, -1, -1)
query = query.unsqueeze(0).expand(batch_size, -1, -1)
reference_points = self.reference_points_fc(query_pos).sigmoid();
self.reference_points_fc是调用网络结构中的(reference_points_fc): Linear(in_features=256, out_features=2, bias=True)全连接层,将输入的query(1,300,256),维度为256的向量映射到输出维度为2的向量,得到的reference_points的shape为(1,300,2)
特征图经过全连接层FFN的作用是将前面提取到的特征综合起来。全连接层的每一个节点都与上一层的所有节点相连,这样可以将前一层的特征信息通过权重和偏置进行加权求和,然后通过激活函数进行非线性变换,得到新的特征表示。全连接层的作用是将低级的特征抽象为更高级的特征,从而提取更加复杂的模式和特征。通过全连接层,神经网络可以学习到更加抽象和高层次的特征表示,进而用于分类、回归等任务
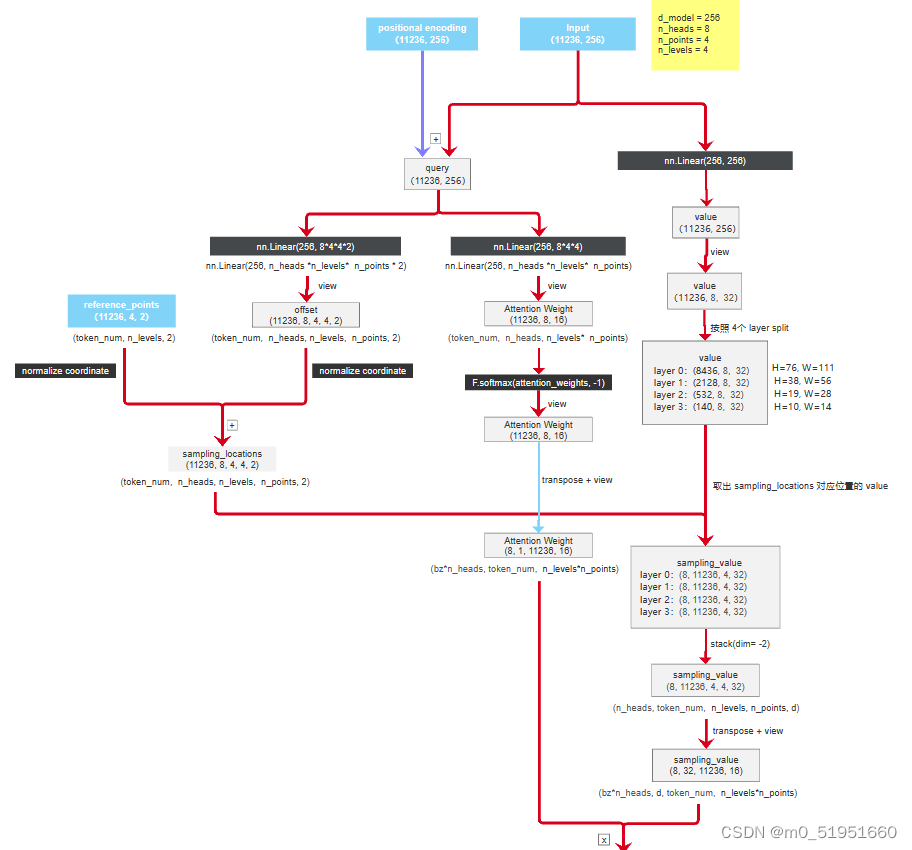
3.4 MultiScaleDeformableAttention
下面介绍的是整个deformableDETR最核心的部分MultiScaleDeformableAttention。其网络结构如下
// MultiScaleDeformableAttention的网络结构
(layers): ModuleList(
(0): DeformableDetrTransformerEncoderLayer(
(self_attn): MultiScaleDeformableAttention(
(dropout): Dropout(p=0.1, inplace=False)
(sampling_offsets): Linear(in_features=256, out_features=256, bias=True)
(attention_weights): Linear(in_features=256, out_features=128, bias=True)
(value_proj): Linear(in_features=256, out_features=256, bias=True)
(output_proj): Linear(in_features=256, out_features=256, bias=True)
)
主要包括四个全连接层,分别生成offsets(sampling_offsets),attention_weights,value(value_proj),output(output_proj)。
在deformable_detr.py中的forword_encoder中,最先进入的就是MSDeformAttention,其工作流程如下图。
// An highlighted block
if value is None:
value = query
if identity is None:
identity = query
if query_pos is not None:
query = query + query_pos
if not self.batch_first:
# change to (bs, num_query ,embed_dims)
query = query.permute(1, 0, 2)
value = value.permute(1, 0, 2)
bs, num_query, _ = query.shape
bs, num_value, _ = value.shape
assert (spatial_shapes[:, 0] * spatial_shapes[:, 1]).sum() == num_value
value = self.value_proj(value)
if key_padding_mask is not None:
value = value.masked_fill(key_padding_mask[..., None], 0.0)
value = value.view(bs, num_value, self.num_heads, -1)
sampling_offsets = self.sampling_offsets(query).view(
bs, num_query, self.num_heads, self.num_levels, self.num_points, 2)
attention_weights = self.attention_weights(query).view(
bs, num_query, self.num_heads, self.num_levels * self.num_points)
attention_weights = attention_weights.softmax(-1)
attention_weights = attention_weights.view(bs, num_query,
self.num_heads,
self.num_levels,
self.num_points)
if reference_points.shape[-1] == 2:
offset_normalizer = torch.stack(
[spatial_shapes[..., 1], spatial_shapes[..., 0]], -1)
sampling_locations = reference_points[:, :, None, :, None, :] \
+ sampling_offsets \
/ offset_normalizer[None, None, None, :, None, :]
elif reference_points.shape[-1] == 4:
sampling_locations = reference_points[:, :, None, :, None, :2] \
+ sampling_offsets / self.num_points \
* reference_points[:, :, None, :, None, 2:] \
* 0.5
else:
raise ValueError(
f'Last dim of reference_points must be'
f' 2 or 4, but get {reference_points.shape[-1]} instead.')
if ((IS_CUDA_AVAILABLE and value.is_cuda)
or (IS_MLU_AVAILABLE and value.is_mlu)):
output = MultiScaleDeformableAttnFunction.apply(
value, spatial_shapes, level_start_index, sampling_locations,
attention_weights, self.im2col_step)
else:
output = multi_scale_deformable_attn_pytorch(
value, spatial_shapes, sampling_locations, attention_weights)
output = self.output_proj(output)
if not self.batch_first:
# (num_query, bs ,embed_dims)
output = output.permute(1, 0, 2)
return self.dropout(output) + identity
其中对于MultiScaleDeformableAttnFunction函数,其代码如下:
// An highlighted block
def ms_deform_attn_core_pytorch(value, value_spatial_shapes, sampling_locations, attention_weights):
# for debug and test only,
# need to use cuda version instead
N_, S_, M_, D_ = value.shape
_, Lq_, M_, L_, P_, _ = sampling_locations.shape
value_list = value.split([H_ * W_ for H_, W_ in value_spatial_shapes], dim=1)
sampling_grids = 2 * sampling_locations - 1
sampling_value_list = []
for lid_, (H_, W_) in enumerate(value_spatial_shapes):
# N_, H_*W_, M_, D_ -> N_, H_*W_, M_*D_ -> N_, M_*D_, H_*W_ -> N_*M_, D_, H_, W_
value_l_ = value_list[lid_].flatten(2).transpose(1, 2).reshape(N_*M_, D_, H_, W_)
# N_, Lq_, M_, P_, 2 -> N_, M_, Lq_, P_, 2 -> N_*M_, Lq_, P_, 2
sampling_grid_l_ = sampling_grids[:, :, :, lid_].transpose(1, 2).flatten(0, 1)
# N_*M_, D_, Lq_, P_
sampling_value_l_ = F.grid_sample(value_l_, sampling_grid_l_,
mode='bilinear', padding_mode='zeros', align_corners=False)
sampling_value_list.append(sampling_value_l_)
# (N_, Lq_, M_, L_, P_) -> (N_, M_, Lq_, L_, P_) -> (N_, M_, 1, Lq_, L_*P_)
attention_weights = attention_weights.transpose(1, 2).reshape(N_*M_, 1, Lq_, L_*P_)
output = (torch.stack(sampling_value_list, dim=-2).flatten(-2) * attention_weights).sum(-1).view(N_, M_*D_, Lq_)
return output.transpose(1, 2).contiguous()
总结
提示:这里对文章进行总结:

















 4146
4146

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









