




 本文围绕Kylin展开,介绍了新型分布式查询引擎Sparder,它由Spark application后端实现,启动受配置参数影响,还提到Kylin第一条SQL查询慢与Sparder启动有关。此外,说明了HDFS存储目录,最后汇总了Kylin4.0查询参数,建议在生产环境调大参数提升性能。
本文围绕Kylin展开,介绍了新型分布式查询引擎Sparder,它由Spark application后端实现,启动受配置参数影响,还提到Kylin第一条SQL查询慢与Sparder启动有关。此外,说明了HDFS存储目录,最后汇总了Kylin4.0查询参数,建议在生产环境调大参数提升性能。
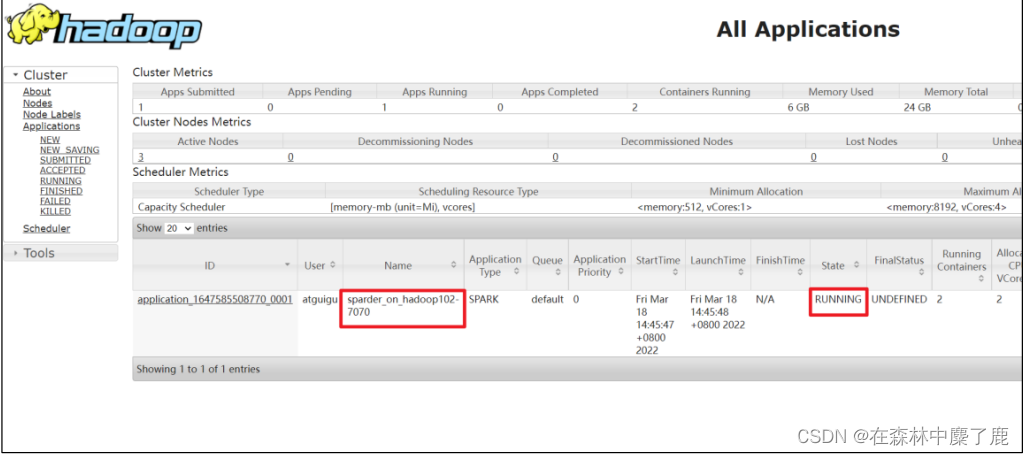
一、查询引擎 Sparder
Sparder (SparderContext) 是由 Spark application 后端实现的新型分布式查询引擎,它是作为一个 Long-running 的 Spark application 存在的。Sparder 会根据 kylin.query.spark-conf 开头的配置项中配置的 Spark 参数来获取 Yarn 资源,如果配置的资源参数过大,可能会影响构建任务甚至无法成功启动 Sparder,如果 Sparder 没有成功启动,则所有查询任务都会失败,因此请在 Kylin 的 WebUI 中检查 Sparder 状态,不过默认情况下,用于查询的 spark 参数会设置的比较小,在生产环境中,大家可以适当把这些参数调大一些,以提升查询性能。
kylin.query.auto-sparder-context-enabled-enabled 参数用于控制是否在启动 kylin 的同时启动Sparder,默认值为 false,即默认情况下会在执行第一条 SQL 的时候才启动 Sparder,因此 Kylin 的第一条 SQL 查询速度一般比较慢,因为包含了 Sparder 任务的启动时间。
二、HDFS 存储目录
根目录:/kylin/kylin_metadata
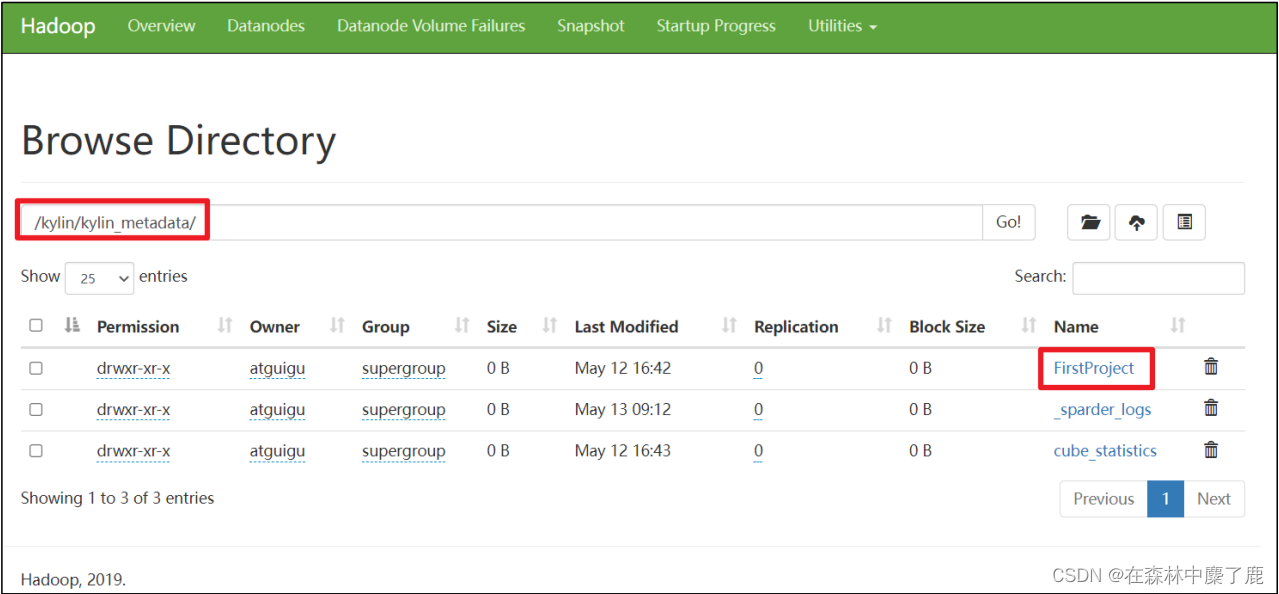
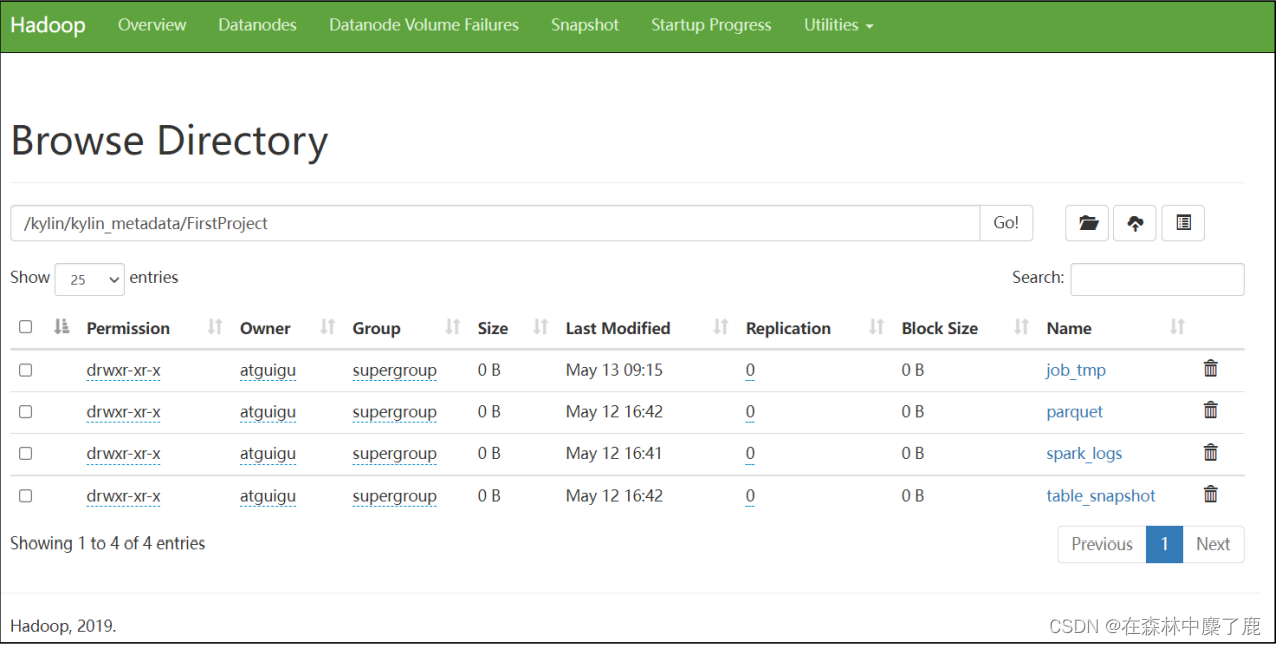
子目录:
- 临时文件存储目录:
/project_name/job_tmp - Cuboid 文件存储目录:
/project_name /parquet/cube_name/segment_name_XXX - 维度表快照存储目录:
/project_name /table_snapshot - Spark 运行日志目录:
/project_name/spark_logs
三、Kylin4.0 查询参数汇总
Kylin 查询参数全部以 kylin.query.spark-conf 开头,默认情况下,用于查询的 spark 参数会设置的比较小,在生产环境中,大家可以适当把这些参数调大一些,以提升查询性能。
####spark 运行模式####
#kylin.query.spark-conf.spark.master=yarn
####spark driver 核心数####
#kylin.query.spark-conf.spark.driver.cores=1
####spark driver 运行内存####
#kylin.query.spark-conf.spark.driver.memory=4G
####spark driver 运行堆外内存####
#kylin.query.spark-conf.spark.driver.memoryOverhead=1G
####spark executor 核心数####
#kylin.query.spark-conf.spark.executor.cores=1
####spark executor 个数####
#kylin.query.spark-conf.spark.executor.instances=1
####spark executor 运行内存####
#kylin.query.spark-conf.spark.executor.memory=4G
####spark executor 运行堆外内存####
#kylin.query.spark-conf.spark.executor.memoryOverhead=1G


















 1179
1179

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











