







 本文是编程小白的自学笔记,介绍了如何在Python中进行网络爬虫,包括设置headers以模拟浏览器访问,获取网页的User-Agent,以及如何通过多页循环获取Top200的数据。示例代码展示了使用requests库进行请求和正则表达式提取信息的方法。
本文是编程小白的自学笔记,介绍了如何在Python中进行网络爬虫,包括设置headers以模拟浏览器访问,获取网页的User-Agent,以及如何通过多页循环获取Top200的数据。示例代码展示了使用requests库进行请求和正则表达式提取信息的方法。
系列文章目录
编程小白的自学笔记六(python中类的静态方法和动态方法)
目录
前面我们已经学习了第三方模块requests模块的get函数,今天我们继续深入学习
一、如何查找网页的headers
通过上次的学习,我们发现我们需要传参headers来骗过服务器,从而让服务器相信是一个正常浏览器在访问它,并不是每一台计算的headers都相同,我们怎么知道呢?我们可以使用浏览器正常访问,然后在检查模式下查看,具体操作如下:
1、打开网页的检查模式。用谷歌浏览器打开网页后,右击鼠标,点击检查。
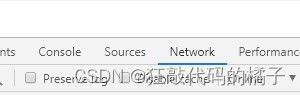
2、选择Network。打开检查模式后,我们在右边的检查模式窗口,点击Network。
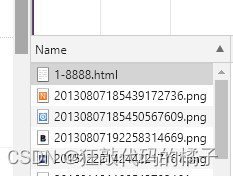
3、选择name。打开Network后,我们发现没有内容,这时点击键盘上的F5键,页面刷新后,出现了name选项卡。
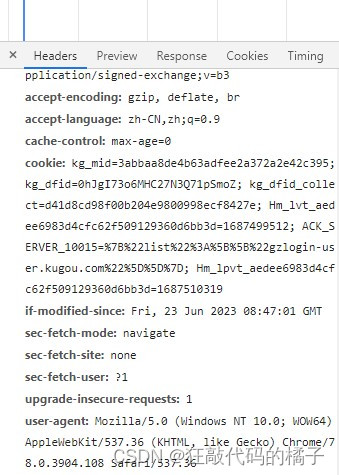
4、查找User-Agent。点击name选项卡里的html文件,然后在右边找到User-Agent,然后把里面的内容复制到python就行了,代码如下:
import re
url = 'https://www.kugou.com/yy/rank/home/1-8888.html'
h = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36'}
try:
req = requests.get(url,headers=h)
songs = re.findall(r'<li.*?title="(.*?)"',req.text)
for song in songs:
print(song)
except:
print('查询失败')结果输出和上一篇文章一样。
二、如何查找top200数据
上面的代码只能获取一个网页的数据,只能获得top20的数据,我们想要获取top200的数据,难道要写个十个代码。
No~,经过研究链接,我们发现,把后面的1-8888改成2-8888就翻页到第二面,以此类推,top180-200的链接是10-8888,链接本质上是以字符串的形式传给url,这样我们可以设置一个变量,通过for循环的形式,自动改变url的地址。我们来看一下代码:
import requests
import re
for i in range(1,11):
url = f'https://www.kugou.com/yy/rank/home/{i}-8888.html'
h = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36'}
try:
req = requests.get(url,headers=h)
songs = re.findall(r'<li.*?title="(.*?)"',req.text)
for song in songs:
print(song)
except:
print('查询失败')输出的结果为:
苏星婕 - 听悲伤的情歌
指尖笑 - 不问ciaga
郭顶 - 凄美地
一只白羊 - 等不到的你
任夏 - 悲伤的爱情
张靓颖、王赫野 - 是你 (Live)
Mae Stephens - If We Ever Broke Up (Explicit)
Kui Kui - 宝贝在干嘛
张紫豪 - 可不可以
周杰伦 - 说好的幸福呢
周杰伦 - 晴天
汪苏泷、吉克隽逸 - Letting Go (Live)
承桓 - 我会等
蔡健雅 - Letting Go
任夏 - 失眠情歌 (Live合唱版)
苏星婕 - 吹着晚风想起你
周杰伦 - 我落泪情绪零碎
云狗蛋 - 天若有情
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1016
1016

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











