




 本文详细介绍了Redis的缓存类型、淘汰策略、与Memcache的对比,以及Redis的功能、数据结构、高可用性。重点讨论了Redis的LRU策略、与Memcache的区别、主从和哨兵系统,还涵盖了Redis的持久化、故障转移和常见问题。对于面试者来说,是全面了解和准备Redis面试题的宝贵资源。
本文详细介绍了Redis的缓存类型、淘汰策略、与Memcache的对比,以及Redis的功能、数据结构、高可用性。重点讨论了Redis的LRU策略、与Memcache的区别、主从和哨兵系统,还涵盖了Redis的持久化、故障转移和常见问题。对于面试者来说,是全面了解和准备Redis面试题的宝贵资源。
前言
缓存知识点一键获取Redis面试题
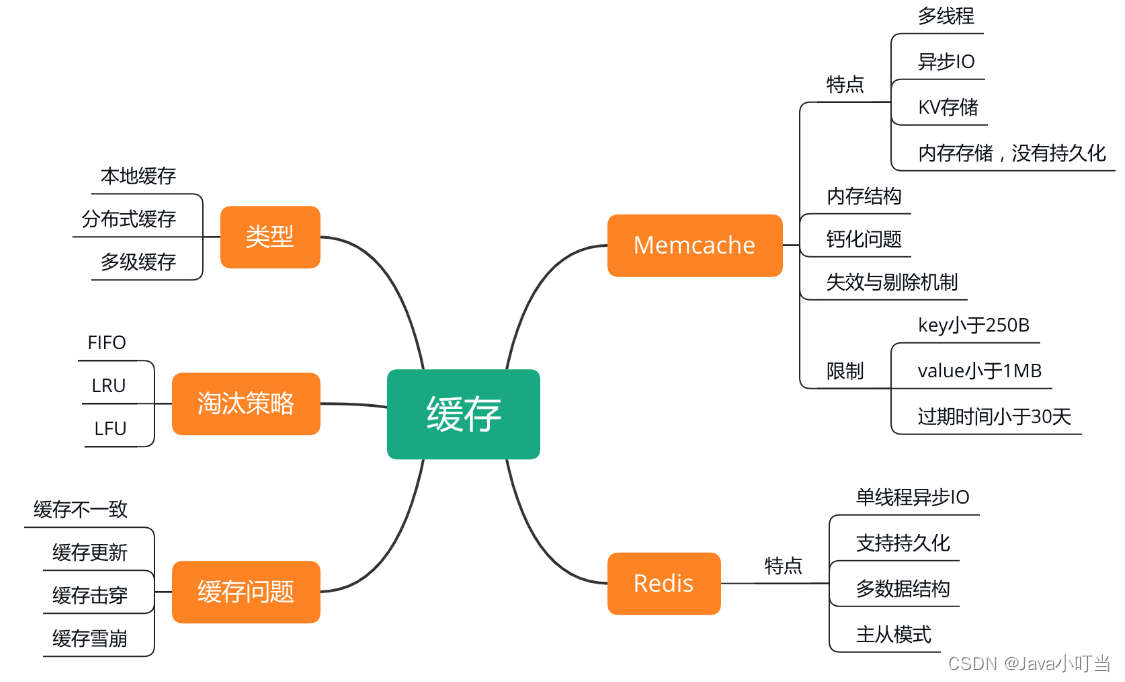
缓存有哪些类型?
缓存是高并发场景下提高热点数据访问性能的一个有效手段,在开发项目时会经常使用到。
缓存的类型分为: 本地缓存、分布式缓存和多级缓存。
本地缓存:
本地缓存就是在进程的内存中进行缓存,比如我们的 JVM 堆中,可以用 LRUMap 来实现,也可以使用 Ehcache 这样的工具来实现。
本地缓存是内存访问,没有远程交互开销,性能最好,但是受限于单机容量,一般缓存较小且无法扩展。
分布式缓存:
分布式缓存可以很好得解决这个问题。
分布式缓存一般都具有良好的水平扩展能力,对较大数据量的场景也能应付自如。缺点就是需要进行远程请求,性能不如本地缓存。
多级缓存:
为了平衡这种情况,实际业务中一般采用多级缓存,本地缓存只保存访问频率最高的部分热点数据,其他的热点数据放在分布式缓存中。
在目前的一线大厂中,这也是最常用的缓存方案,单考单一的缓存方案往往难以撑住很多高并发的场景。
淘汰策略
不管是本地缓存还是分布式缓存,为了保证较高性能,都是使用内存来保存数据,由于成本和内存限制,当存储的数据超过缓存容量时,需要对缓存的数据进行剔除。
一般的剔除策略有 FIFO 淘汰最早数据、LRU 剔除最近最少使用、和 LFU 剔除最近使用频率最低的数据几种策略。
-
noeviction:返回错误当内存限制达到并且客户端尝试执行会让更多内存被使用的命令(大部分的写入指令,但DEL和几个例外)
-
allkeys-lru: 尝试回收最少使用的键(LRU),使得新添加的数据有空间存放。
-
volatile-lru: 尝试回收最少使用的键(LRU),但仅限于在过期集合的键,使得新添加的数据有空间存放。
-
allkeys-random: 回收随机的键使得新添加的数据有空间存放。
-
volatile-random: 回收随机的键使得新添加的数据有空间存放,但仅限于在过期集合的键。
-
volatile-ttl: 回收在过期集合的键,并且优先回收存活时间(TTL)较短的键,使得新添加的数据有空间存放。
如果没有键满足回收的前提条件的话,策略volatile-lru, volatile-random以及volatile-ttl就和noeviction 差不多了。
其实在大家熟悉的LinkedHashMap中也实现了Lru算法的,实现如下:
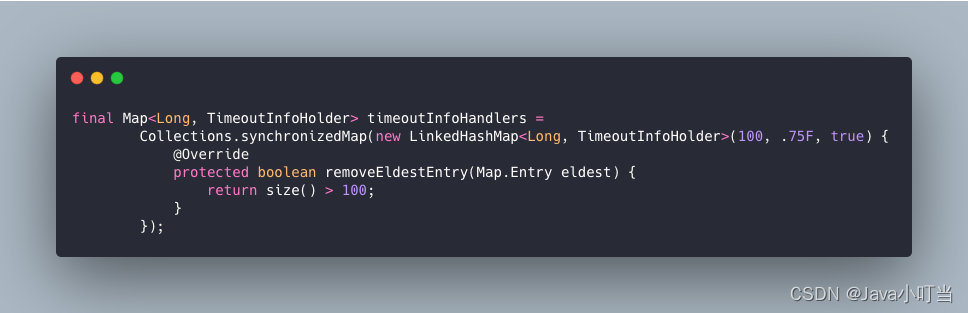
当容量超过100时,开始执行LRU策略:将最近最少未使用的 TimeoutInfoHolder 对象 evict 掉。
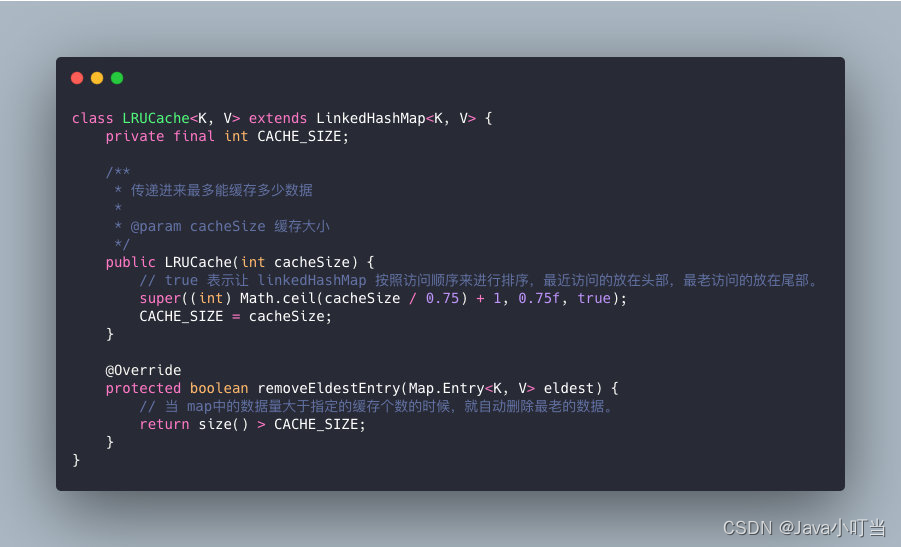
真实面试中会让你写LUR算法,你可别搞原始的那个,那真TM多,写不完的,你要么怼上面这个,要么怼下面这个,找一个数据结构实现下Java版本的LRU还是比较容易的,知道啥原理就好了。
Memcache
注意后面会把 Memcache 简称为 MC。
先来看看 MC 的特点:
- MC 处理请求时使用多线程异步 IO 的方式,可以合理利用 CPU 多核的优势,性能非常优秀;
- MC 功能简单,使用内存存储数据;
- MC 的内存结构以及钙化问题我就不细说了,大家可以查看官网了解下;
- MC 对缓存的数据可以设置失效期,过期后的数据会被清除;
- 失效的策略采用延迟失效,就是当再次使用数据时检查是否失效;
- 当容量存满时,会对缓存中的数据进行剔除,剔除时除了会对过期 key 进行清理,还会按 LRU 策略对数据进行剔除。
另外,使用 MC 有一些限制,这些限制在现在的互联网场景下很致命,成为大家选择Redis、MongoDB的重要原因:
- key 不能超过 250 个字节;
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









