




 本文深入探讨了Redis的核心特性,包括基于内存的高速操作、高效的压缩列表和跳跃表数据结构、单线程模型以及I/O多路复用。文章详细解释了Redis如何利用SDS和zipList优化存储,以及skipList实现排序功能。此外,还介绍了Redis的持久化策略,如RDB和AOF,以及如何通过主从复制和哨兵系统保障高可用性。
本文深入探讨了Redis的核心特性,包括基于内存的高速操作、高效的压缩列表和跳跃表数据结构、单线程模型以及I/O多路复用。文章详细解释了Redis如何利用SDS和zipList优化存储,以及skipList实现排序功能。此外,还介绍了Redis的持久化策略,如RDB和AOF,以及如何通过主从复制和哨兵系统保障高可用性。
前言
本篇主要将Redis核心内容过了一遍,涉及到数据结构、内存模型、IO模型、持久化RDB和AOF、主从复制原理、哨兵原理、cluster原理。

Redis为什么这么快?
很多人只知道是K/V NoSQl内存数据库,单线程……这都是没有全面理解Redis导致无法继续深问下去。
这个问题是基础摸底,我们可以从Redis不同数据类型底层的数据结构实现、完全基于内存、IO多路复用网络模型、线程模型、渐进式rehash……
到底有多快?
我们可以先说到底有多快,根据官方数据,Redis QPS可以达到约100000(每秒请求数),有兴趣的可以参考官方的基准程序测试《How fast is Redis?》,地址:https://redis.io/topics/benchmarks
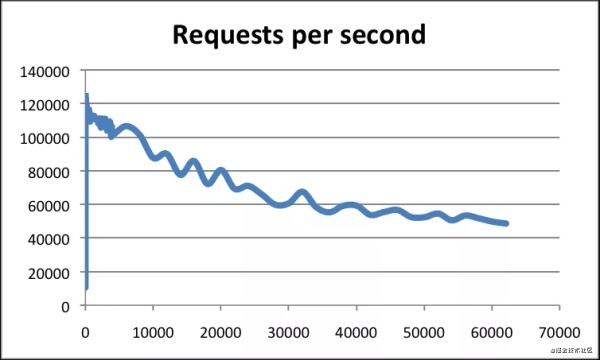
基准测试
横轴是连接数,纵轴是QPS。
这张图反映了一个数量级,通过量化让面试官觉得你有看过官方文档,很严谨。
基于内存实现
Redis是基于内存的数据库,跟磁盘数据库相比,完全吊打磁盘的速度。
不论读写操作都是在内存上完成的,我们分别对比下内存操作与磁盘操作的差异。
磁盘调用
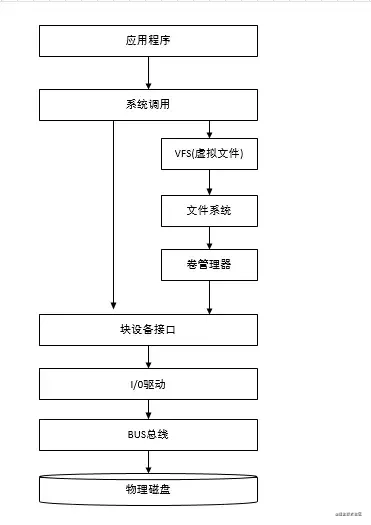
内存操作
内存直接由CPU控制,也就是CPU内部集成的内存控制器,所以说内存是直接与CPU对接,享受与CPU通信的最优带宽。
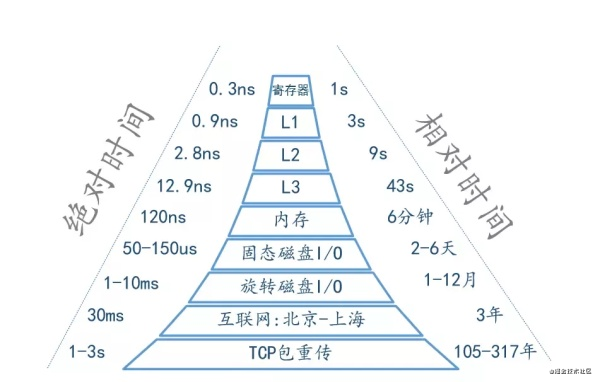
最后以一张图量化系统的各种延时时间(部分数据引用 Brendan Gregg)
高效的数据结构
学习MySQL的时候我知道为了提高检索速度使用了B+Tree数据结构,所以Redis速度快应该也跟数据结构有关。
Redis一共有5种数据类型,String、List、Hash、Set、SortedSet。
不同的数据类型底层使用了一种或者多种数据结构来支撑,目的就是为了追求更快的速度。
码哥寄语:我们可以分别说明每种数据类型底层的数据结构优点,很多人只知道数据类型,而说出底层数据结构就能让人眼前一亮。
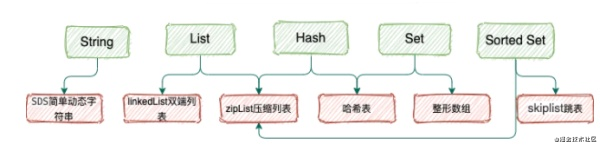
SDS简单动态字符串优势
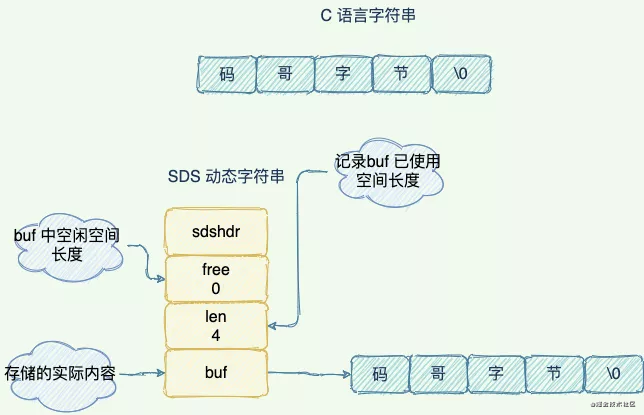
C语言字符串与SDS
1.SDS中len保存这字符串的长度,O(1) 时间复杂度查询字符串长度信息。
2.空间预分配:SDS被修改后,程序不仅会为SDS分配所需要的必须空间,还会分配额外的未使用空间。
3.惰性空间释放:当对SDS进行缩短操作时,程序并不会回收多余的内存空间,而是使用free字段将这些字节数量记录下来不释放,后面如果需要 append 操作,则直接使用free中未使用的空间,减少了内存的分配。
zipList 压缩列表
压缩列表是 List 、hash、 sorted Set 三种数据类型底层实现之一。
当一个列表只有少量数据的时候,并且每个列表项要么就是小整数值,要么就是长度比较短的字符串,那么 Redis 就会使用压缩列表来做列表键的底层实现。

ziplist
这样内存紧凑,节约内存。
quicklist后续版本对列表数据结构进行了改造,使用 quicklist 代替了 ziplist 和 linkedlist。
quicklist 是 ziplist 和 linkedli
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









