




 本文详述了Kafka在处理万亿级消息时的关键挑战,包括集群版本升级、数据迁移、流量限制、监控告警、资源隔离等。通过分析Kafka开源版本的缺陷,提出了一套全面的集群管理方案,包括自动化工具、平台化管理和性能优化措施,以确保集群的高可用、高可靠、高性能和安全性。
本文详述了Kafka在处理万亿级消息时的关键挑战,包括集群版本升级、数据迁移、流量限制、监控告警、资源隔离等。通过分析Kafka开源版本的缺陷,提出了一套全面的集群管理方案,包括自动化工具、平台化管理和性能优化措施,以确保集群的高可用、高可靠、高性能和安全性。
前言
一、Kafka应用
本文主要总结当Kafka集群流量达到 万亿级记录/天或者十万亿级记录/天。
甚至更高后,我们需要具备哪些能力才能保障集群高可用、高可靠、高性能、高吞吐、安全的运行。
关于Kafka的知识点总结了一个图谱,分享给大家:
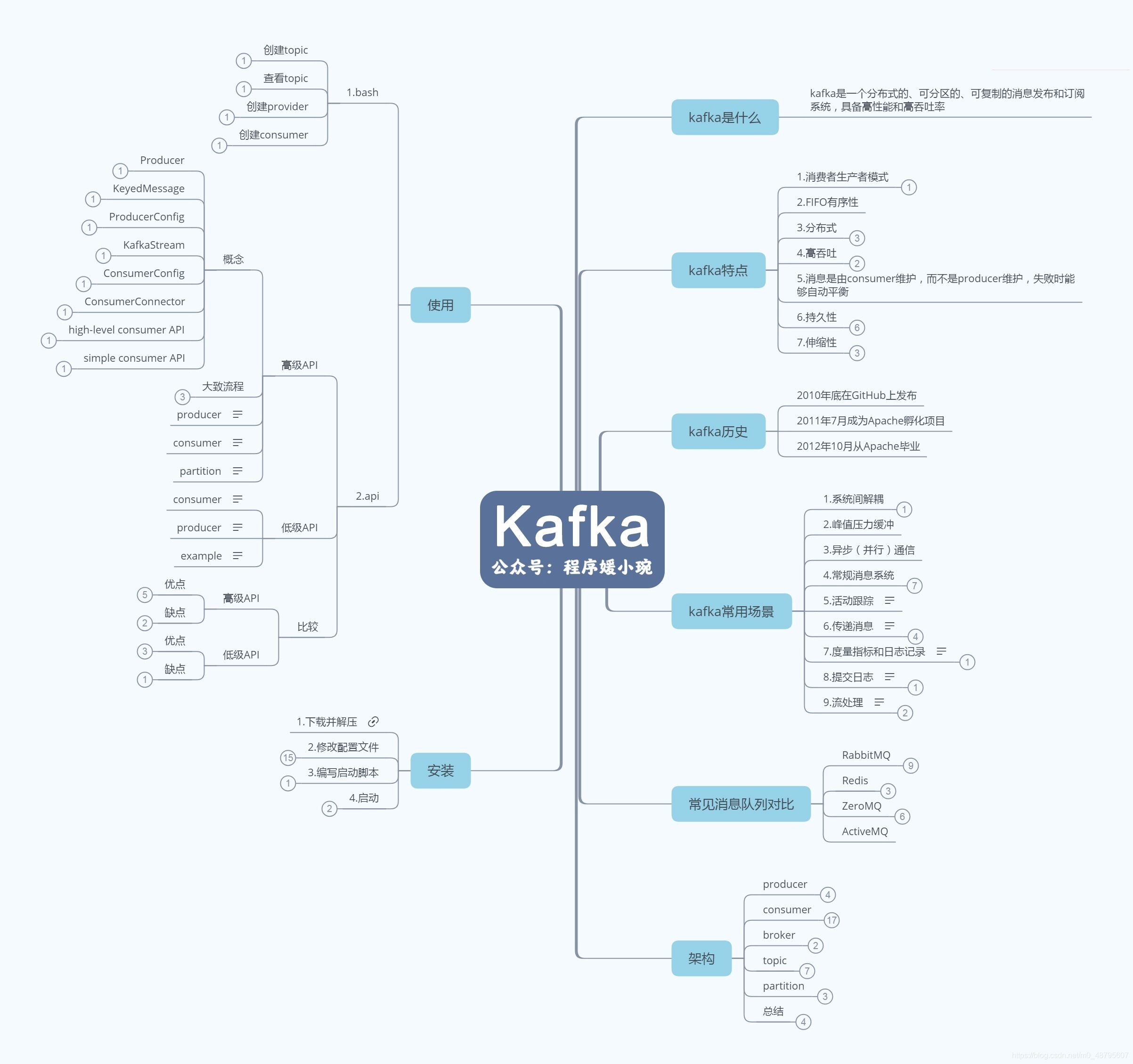
这里总结内容主要针对Kafka2.1.1版本,包括集群版本升级、数据迁移、流量限制、监控告警、负载均衡、集群扩/缩容、资源隔离、集群容灾、集群安全、性能优化、平台化、开源版本缺陷、社区动态等方面。本文主要是介绍核心脉络,不做过多细节讲解。下面我们先来看看Kafka作为数据中枢的一些核心应用场景。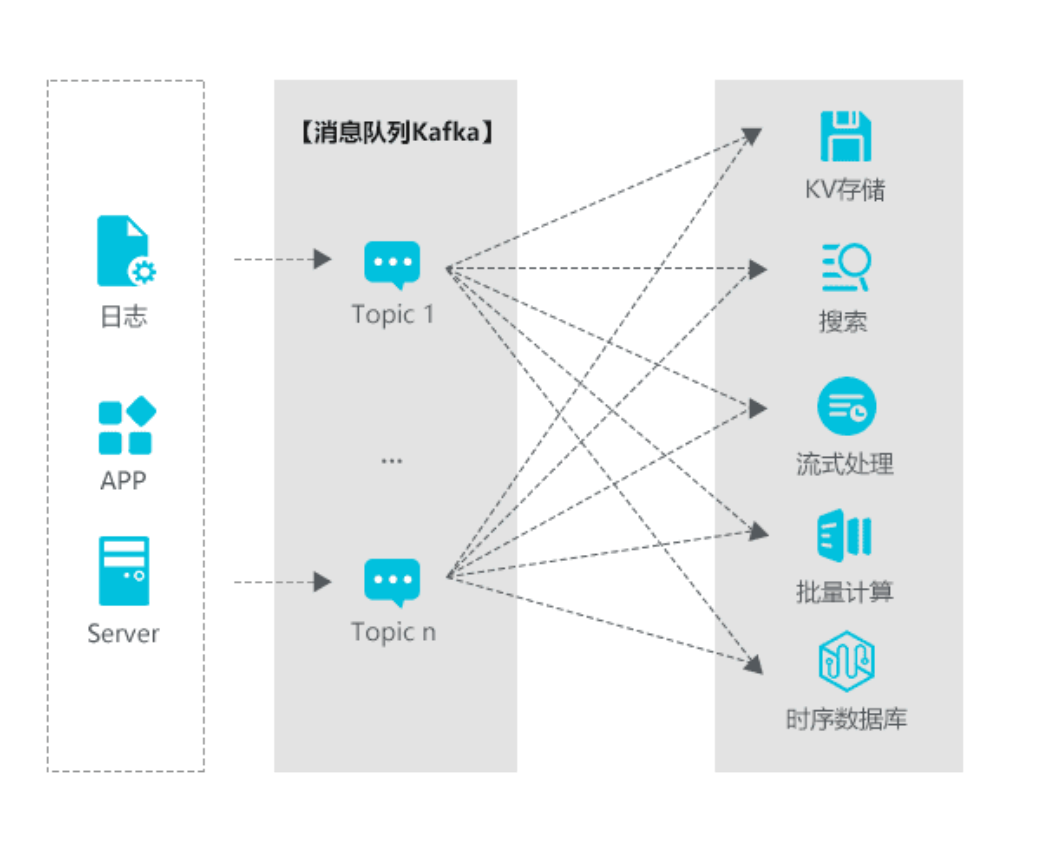
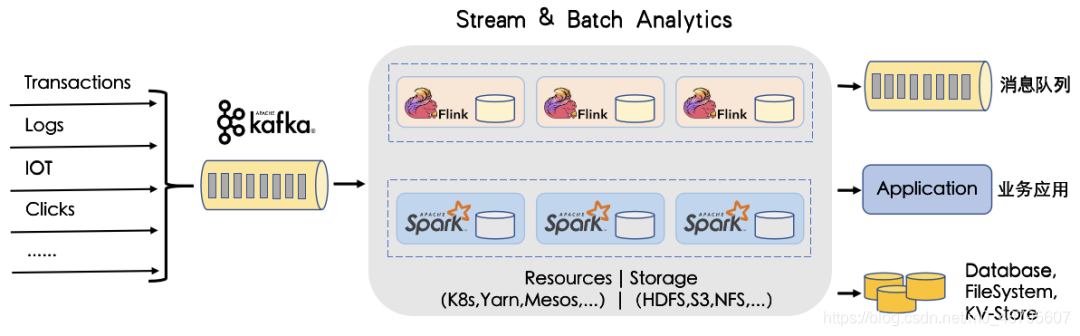
下图展示了一些主流的数据处理流程,Kafka起到一个数据中枢的作用。
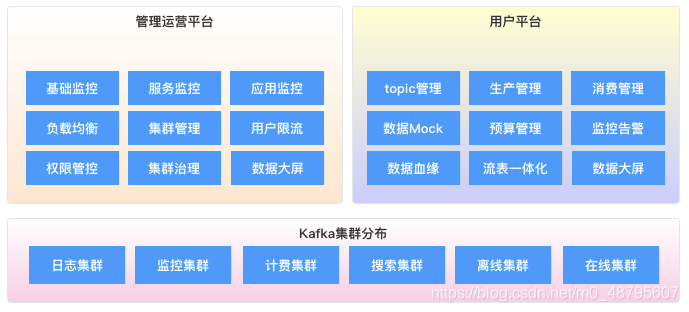
接下来看看我们Kafka平台整体架构;
1.1 版本升级
1.1.1 开源版本如何进行版本滚动升级与回退
官网地址:http://kafka.apache.org
1.1.1.2 源码改造如何升级与回退
由于在升级过程中,必然出现新旧代码逻辑交替的情况。集群内部部分节点是开源版本,另外一部分节点是改造后的版本。所以,需要考虑在升级过程中,新旧代码混合的情况,如何兼容以及出现故障时如何回退。
1.2 数据迁移
由于Kafka集群的架构特点,这必然导致集群内流量负载不均衡的情况,所以我们需要做一些数据迁移来实现集群不同节点间的流量均衡。Kafka开源版本为数据迁移提供了一个脚本工具“bin/kafka-reassign-partitions.sh”,如果自己没有实现自动负载均衡,可以使用此脚本。
开源版本提供的这个脚本生成迁移计划完全是人工干预的,当集群规模非常大时,迁移效率变得非常低下,一般以天为单位进行计算。当然,我们可以实现一套自动化的均衡程序,当负载均衡实现自动化以后,基本使用调用内部提供的API,由程序去帮我们生成迁移计划及执行迁移任务。需要注意的是,迁移计划有指定数据目录和不指定数据目录两种,指定数据目录的需要配置ACL安全认证。
官网地址:http://kafka.apache.org
1.2.1 broker间数据迁移
不指定数据目录
//未指定迁移目录的迁移计划
{
"version":1,
"partitions":[
{
"topic":"yyj4","partition":0,"replicas":[1000003,1000004]},
{
"topic":"yyj4","partition":1,"replicas":[1000003,1000004]},
{
"topic":"yyj4","partition":2,"replicas":[1000003,1000004]}
]
}
指定数据目录
//指定迁移目录的迁移计划
{
"version":1,
"partitions":[
{
"topic":"yyj1","partition":0,"replicas":[1000006,1000005],"log_dirs":["/data1/bigdata/mydata1","/data1/bigdata/mydata3"]},
{
"topic":"yyj1","partition":1,"replicas":[1000006,1000005],"log_dirs":["/data1/bigdata/mydata1","/data1/bigdata/mydata3"]},
{
"topic":"yyj1","partition":2,"replicas":[1000006,1000005],"log_dirs":["/data1/bigdata/mydata1","/data1/bigdata/mydata3"]}
]
}
1.2.2 broker内部磁盘间数据迁移
生产环境的服务器一般都是挂载多块硬盘,比如4块/12块等;那么可能出现在Kafka集群内部,各broker间流量比较均衡,但是在broker内部,各磁盘间流量不均衡,导致部分磁盘过载,从而影响集群性能和稳定,也没有较好的利用硬件资源。在这种情况下,我们就需要对broker内部多块磁盘的流量做负载均衡,让流量更均匀的分布到各磁盘上。
1.2.3 并发数据迁移
当前Kafka开源版本(2.1.1版本)提供的副本迁移工具“bin/kafka-reassign-partitions.sh”在同一个集群内只能实现迁移任务的串行。对于集群内已经实现多个资源组物理隔离的情况,由于各资源组不会相互影响,但是却不能友好的进行并行的提交迁移任务,迁移效率有点低下,这种不足直到2.6.0版本才得以解决。如果需要实现并发数据迁移,可以选择升级Kafka版本或者修改Kafka源码。
1.2.4 终止数据迁移
当前Kafka开源版本(2.1.1版本)提供的副本迁移工具“bin/kafka-reassign-partitions.sh”在启动迁移任务后,无法终止迁移。当迁移任务对集群的稳定性或者性能有影响时,将变得束手无策,只能等待迁移任务执行完毕(成功或者失败),这种不足直到2.6.0版本才得以解决。如果需要实现终止数据迁移,可以选择升级Kafka版本或者修改Kafka源码。
1.3 流量限制
1.3.1 生产消费流量限制
经常会出现一些突发的,不可预测的异常生产或者消费流量会对集群的IO等资源产生巨大压力,最终影响整个集群的稳定与性能。那么我们可以对用户的生产、消费、副本间数据同步进行流量限制,这个限流机制并不是为了限制用户,而是避免突发的流量影响集群的稳定和性能,给用户可以更好的服务。
如下图所示,节点入流量由140MB/s左右突增到250MB/s,而出流量则从400MB/s左右突增至800MB/s。如果没有限流机制,那么集群的多个节点将有被这些异常流量打挂的风险,甚至造成集群雪崩。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 664
664

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









