




 本文详细介绍了Spring Cloud Ribbon作为客户端负载均衡工具的工作原理和使用方式,包括随机、轮询等均衡策略及重试机制。此外,文章还深入探讨了Hystrix的熔断流程,解释了其如何在服务响应慢或失败时提供故障隔离和降级策略,以确保系统的稳定性和可用性。
本文详细介绍了Spring Cloud Ribbon作为客户端负载均衡工具的工作原理和使用方式,包括随机、轮询等均衡策略及重试机制。此外,文章还深入探讨了Hystrix的熔断流程,解释了其如何在服务响应慢或失败时提供故障隔离和降级策略,以确保系统的稳定性和可用性。
Ribbon
我们首先对Ribbon 进行一个介绍。
Spring Cloud Ribbon 是一个基于 HTTP 和 TCP的客户端负载均衡工具, 它不同于Nginx的服务端负载均衡,他侧重于将需要的访问清单从服务注册中心中取出,放在自己的访问服务器列表(ServerList)中,当需要访问某一台具体的服务器的时候,他会经过不同的轮询策略去访问相应的负载均衡设备。Ribbon适合于日访问量并不高的系统中。
同时他也不同于硬件设施的负载均衡,硬件设施经常通过配置citrix netscaler, 负载均衡路由器,或者实现可循环的DNS 从而实现轮询算法,分配流量给各个节点。软件端的负载均衡,包括Nginx或者Ribbon,他们通过用代码实现轮询算法的策略,从而实现小规模的任务分配,软件的负载均衡具有可重用,费用低和易维护等特点,当然,他的缺点也很明显,只能实现小规模的负载均衡,换句话说只能小打小闹,而不能对性能做一个跨越性的提升。
Ribbon 在Spring Cloud中的使用
Ribbon在Spring Cloud 可以通过@LoadBalanced 服务端接口,实现客户端的负载均衡,当客户端发起对服务端的请求访问的时候,可以通过Ribbon的负载均衡,选择不那么繁忙的服务器去进行请求处理。
LoadBalaced注解采用了RestTemplate 的服务访问模式,因为是RestTemplate,所以它可以选择返回是Response 对象,还是一个已经被申明属性的对象,或者直接是一个URI。RestTemplate 有四种常用访问方法,get,post,delete和put。
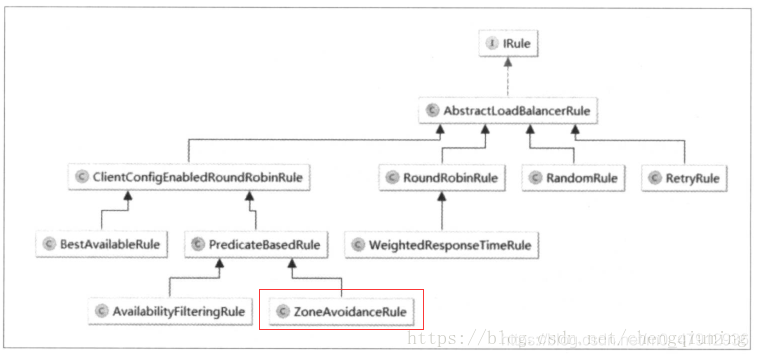
Ribbon 负载均衡策略
-
随机均衡( random Rule):随机均衡是指 Ribbon 可以从ServerList 中随机选取服务器进行分配任务,这种选择方法实现起来简单,但很容易因为取不到服务器而陷入死循环中。
-
Ribbon 轮询均衡 (Round Ribbon Rule)该策略实现了按照线性轮询的方式去访问服务器,每个服务器的访问次数几乎相等,对于任务时间长度相差不大的情况下,这种轮询策略不耗费时间,当然缺点也很明显,容易因为取不到服务器而陷入到死循环中。
-
重试均衡(Retry Rule)重试均衡本质上实现了Ribbon轮询均衡的算法,不同点是他定义了一个TimeOut的时间,首先使用轮询均衡取得服务器,如果取不了,则重新选取,过了一个规定的时间阈值后仍然取不了,则宣告访问失败,返回null值。
-
权重响应时间均衡(weighted Response Time Rule) 这个策略每30秒计算一次服务器响应时间,以响应时间作为权重,响应时间越短的服务器被选中的概率越大。
-
最空闲均衡(Best Available Rule) 他首先遍历所有的服务器,通过遍历找出并发量最小的哪一个,再把任务分配给这个服务器。
-
预测均衡(PredictedBased Rule) 虽然叫做预测算法,但是实际上跟预测关系不大,他是线过滤一轮服务器,将高并发的服务器排除在外,然后实现前面的轮询均衡算法,也就是线性选择服务器。
-
可用过滤均衡(availablityFilteringRule)他继承了预测均衡,同时在预测均衡的基础条件上,增加了两个基本过滤条件,第一是判断断路器Hystrix 是否生效断开,第二是判断并发请求数是否大于阈值
-
区域避免均衡 (zoneAvoidance Rule)该策略主要是在在多区的条件下使用,选择出最佳区域的实例访问。他首先使用ZoneAvoidancePredicate 进行过滤,此为主过滤,同时他也使用AvailbilityPredicate 作为次要过滤条件,作为次要过滤。
负载均衡策略等级关系图:
Ribbon负载均衡的重试机制
因为Eureka 的限制,Spring Cloud 很难达到所有分片一致,于是他们整合Spring retry 机制来增强RestTemplate 的重试能力,尽量达到分片一致。
Spring retry 基本配置如下:
spring.cloud.loadbalancer.retry.enabled=true //开启retry
hystrix.command.default.execution.isolation.thread.timeoutInMilliseconds=10000
//断路器的超时时间
sf-springcloud-service.ribbon.ConnectTimeout=250
sf-springcloud-service.ribbon.ReadTimeout=1000
sf-springcloud-service.ribbon.OkToRetryOnAllOperations=true
// 所有操作请求是否都采用重试
sf-springcloud.ribbon.MaxAutoRetriesNextServer=2
// 切换实例的最大次数
sf-springcloud.ribbon.MaxAutoRetries=1
//当前实例重试的最大次数
Hystrix
Hystrix 是由Martin Fowler提出的,他指的是当一个服务器存在响应缓慢或者响应失败的情况下,Hystrix能够及时发现并返回错误响应,而不是长时间的等待。所以Hystrix 涉及两个动作,发现故障,返回错误响应。
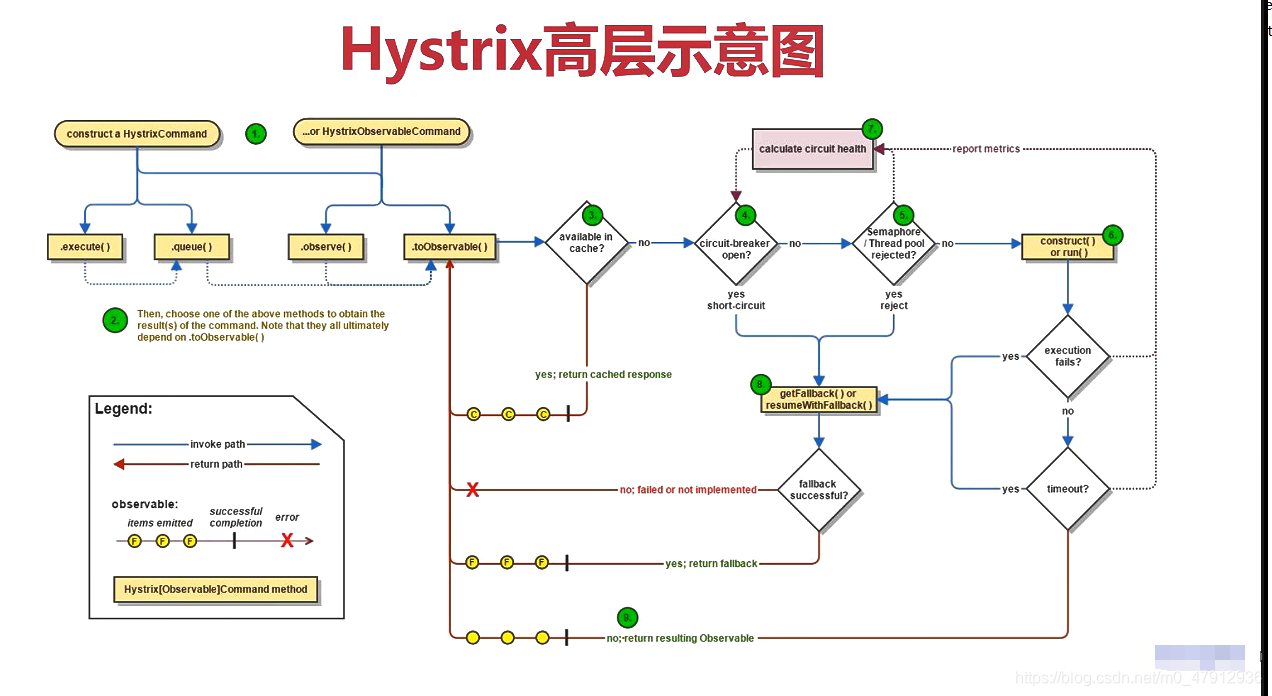
Hystrix 流程图
-
Hystrix 通过HystrixCommand 或者HystrixObservableCommand 对象实现对于熔断的依赖。HystrixCommand 和HystrixObservableCommand 是不同的操作,HystrixCommand 用在依赖的服务返回单个操作结果, 而HystrixObservableCommand 用在以来的服务返回多个操作结果的时候。
-
下一层代表的是命令执行方式:
Execute() 同步执行
Queue() 异步执行,返回一个Future对象
Observe() 返回Observable对象,返回HotObservable
ToObserve() 执行也是返回一个Observable 对象,但是返回的是cold Observable
Hot Observable 是指无论有没有观察者进行订阅,事件始终都会发生,他与订阅者是一对多的关系,当存在多个Observable的时候,事件不独立。Cold Observable 是指观察者订阅后,才会进行发射数据流,他与订阅者是一对一的关系,并且是独立的。 -
判断是否存在缓存中
-
检测断路器是否打开,如果断路器打开了,则跳转到fallback进行操作,如果没有,则进行判断断路器没有打开的原因
-
判断断路器是否因为线程池/请求队列和信号量的原因没有打开。 Hystrix它采用的是舱壁模式,所以此处判断的线程池,不是容器的线程池,而是每一个依赖服务特有的容器池
-
请求依赖服务
-
主要是计算服务器是否需要熔断或重新开启,他通过四种状态与短路器沟通,成功,失败,拒绝和超时。
-
如果熔断,执行fallback服务降级,服务降级就是一般是从整体来进行考虑,因为服务器熔断后,将不再被调用,此时候客户端可以自己准备一个default value 的fallback 返回调用,虽然不太准确,但可以确保服务还可用,不至于影响其他回调。能够触发降级调用的事件有三件,分别是依赖是否开启,断路器是否打开,线程池/请求队列或信号量是否占满。
-
返回正确结果
Hystrix 依赖隔离
依赖隔离的目标是避免系统某一部分发生故障,从而使整个系统瘫痪。 该词语最先来自将船舶划分为单独的水密舱室以避免将单个船体破损淹没整艘船舶的船舶;
依赖隔离可以通过线程和信号量来实现,Hystrix为所有依赖都建立线程池,使得依赖之间互相隔离,同时通过限制他们的并发访问次数来达到阻塞扩张的目的。线程可以通过重要度来进行权限分配,这使得重要的依赖可以最优先被响应,每一部分的依赖出现了问题,也不会影响其他依赖的使用资源。
信号量隔离是指在访问服务器之前,得到准许,如果没有准许则不可以访问。

















 167万+
167万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









