




 本文介绍如何使用Python爬虫结合tkinter模块,爬取有道翻译内容并窗口化显示。首先,分析有道翻译网页的XHR请求,找到变化的参数salt、ts和e。然后,模拟浏览器行为,通过获取这些参数构造请求,实现翻译结果的爬取。最后,展示主爬虫程序代码和窗口制作过程。
本文介绍如何使用Python爬虫结合tkinter模块,爬取有道翻译内容并窗口化显示。首先,分析有道翻译网页的XHR请求,找到变化的参数salt、ts和e。然后,模拟浏览器行为,通过获取这些参数构造请求,实现翻译结果的爬取。最后,展示主爬虫程序代码和窗口制作过程。
目录
爬取有道翻译,获取翻译结果
通过python爬虫代码,结合tkinter模块,将爬虫的内容进行窗口化显示
项目最终的效果

本次爬虫所用到的库
import requests
import time
import random
import hashlib
import tkinter as tk
开始爬虫!!!
第一步进入:有道翻译界面:http://fanyi.youdao.com/
使用谷歌浏览器,右击鼠标点击检查,点击Network
输入内容点击翻译后查看XHR,这里有向服务器发送的表单内容
获取向服务器提交的表单Form,后续通过向服务器提交Form 获取翻译结果

多次尝试翻译不同内容,每翻译一次都会出现一个表单,表示浏览器向服务器提交过我们翻译的内容

结果打开每一个表单,查看下面的内容,发现有3个参数不断在变化,那么我们就需要对这3个参数进行获取后,就可以通过爬虫和浏览器一样对服务器发送表单请求,最终获取翻译结果
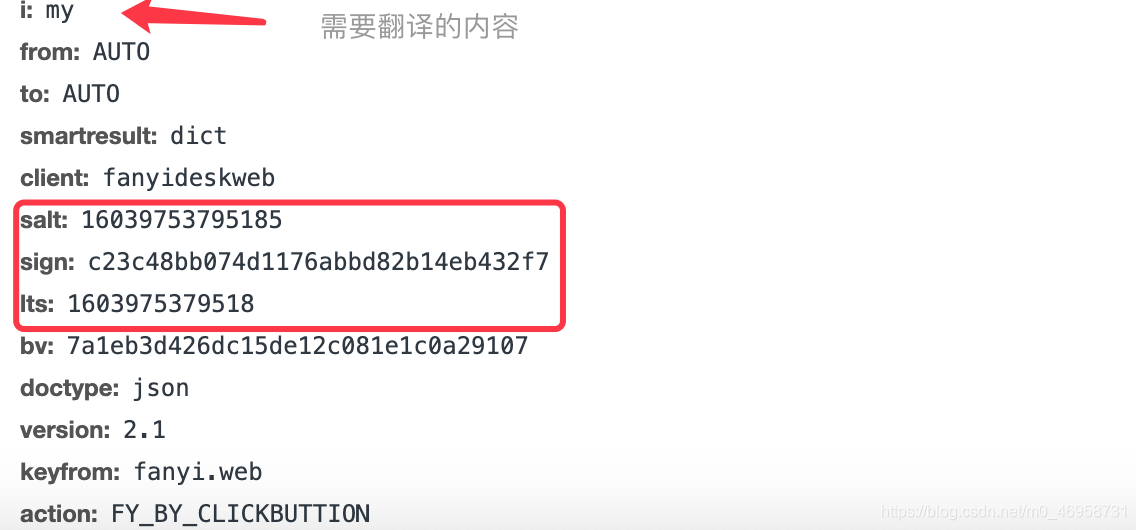
变动参数进行获取
先对salt参数进行搜索,发现以下:
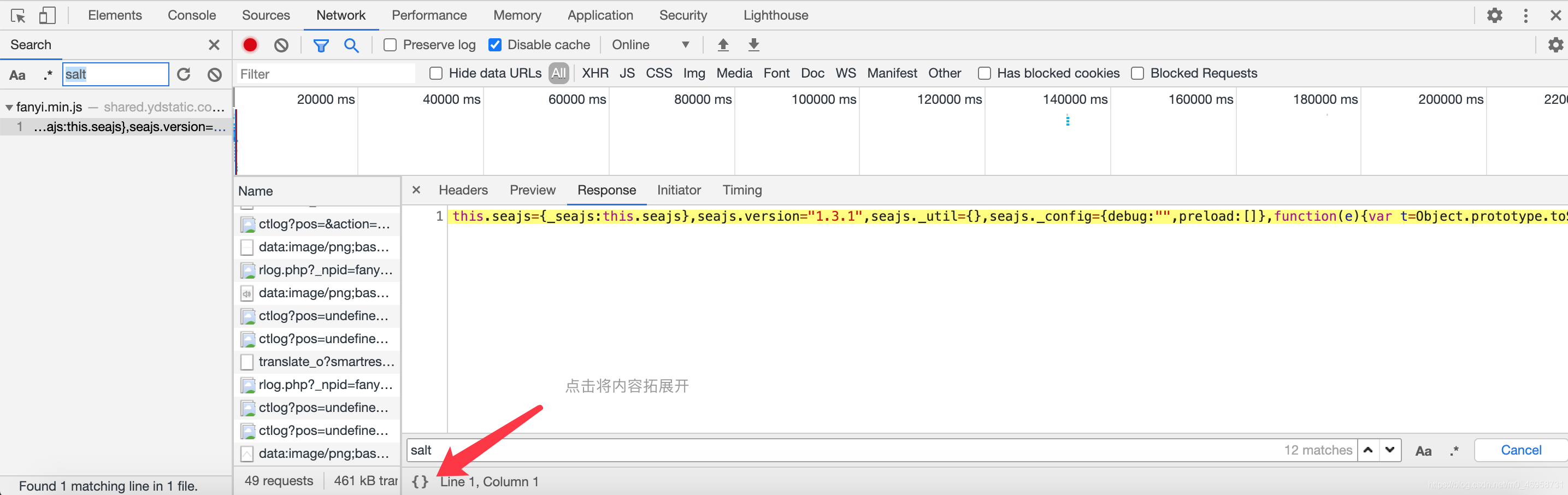
查询到 salt 参数的来源,观察下面的salt 它来自一个叫 i的变量
这里我们还发现一个叫ts ,对!它就是前面表单里面变动的3个参数之一 lts,它来自变量r,那么我们根据它们的写法,我们通过python实现出来
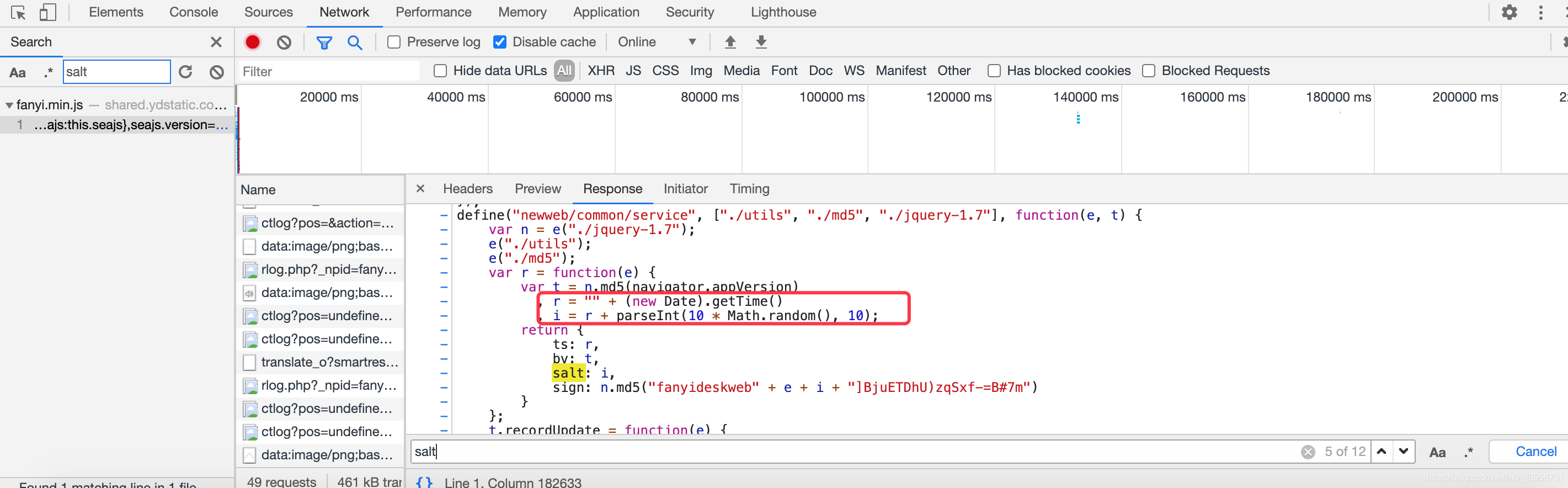
使用python代码进行实现 get_ts这个函数 r变量模拟出来
# 获取时间戳
def get_ts(): # lts 参数
return str(int(time.time()) * 1000) # 它获取的就是一个时间戳
# 获取salt参数
def get_salt(ts): # 模拟网页的写法,
return str(int(ts) + 10 * int(random.random() * 10))
ts = get_ts()
salt = get_salt(ts)
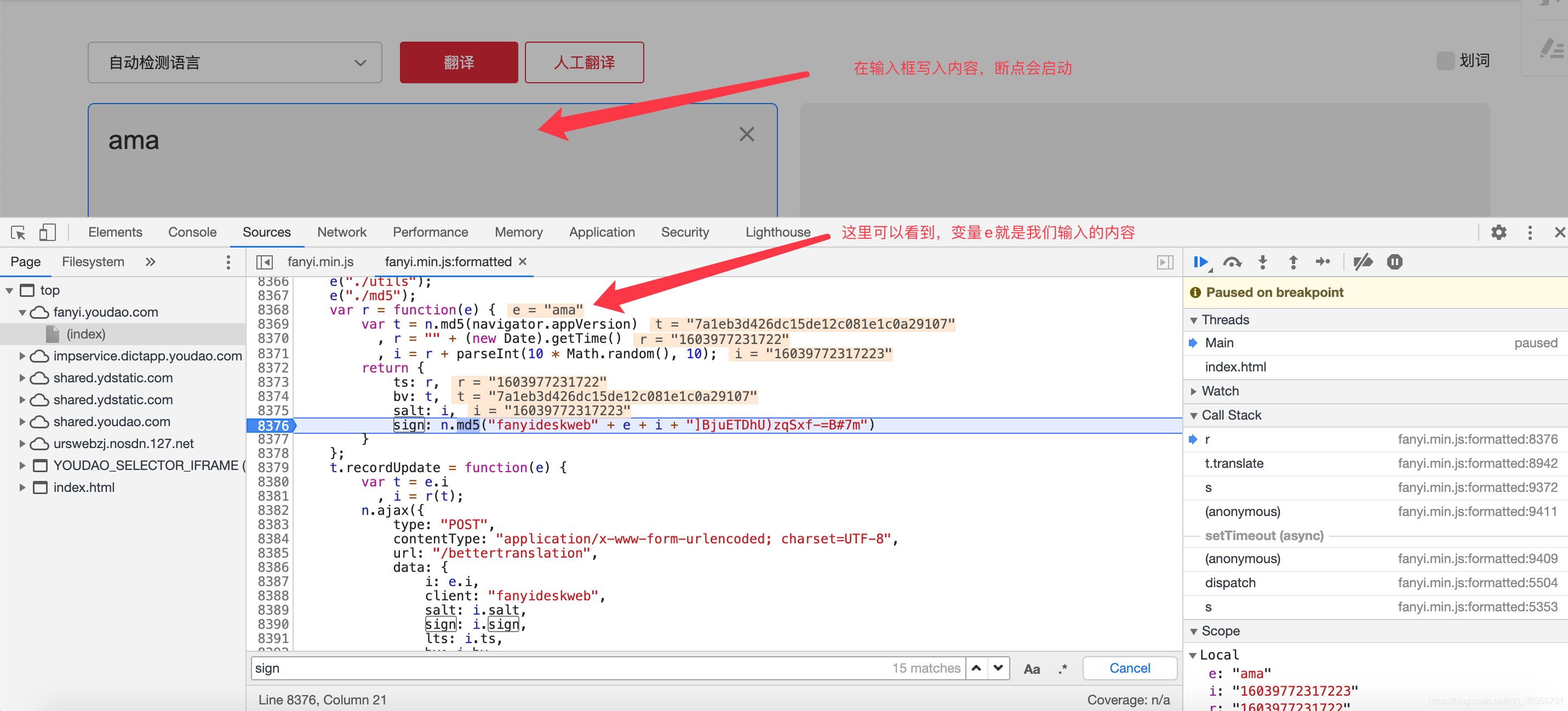
目前只需要获取sign就完成了参数的收集,sigin 里面的变量 i 我们已经获取出来,那么就差获取变量e了,

只要找到变量e 按照它的写法可以完成拼接
通过查询找到相关文件以后,右击鼠标打开它的源码

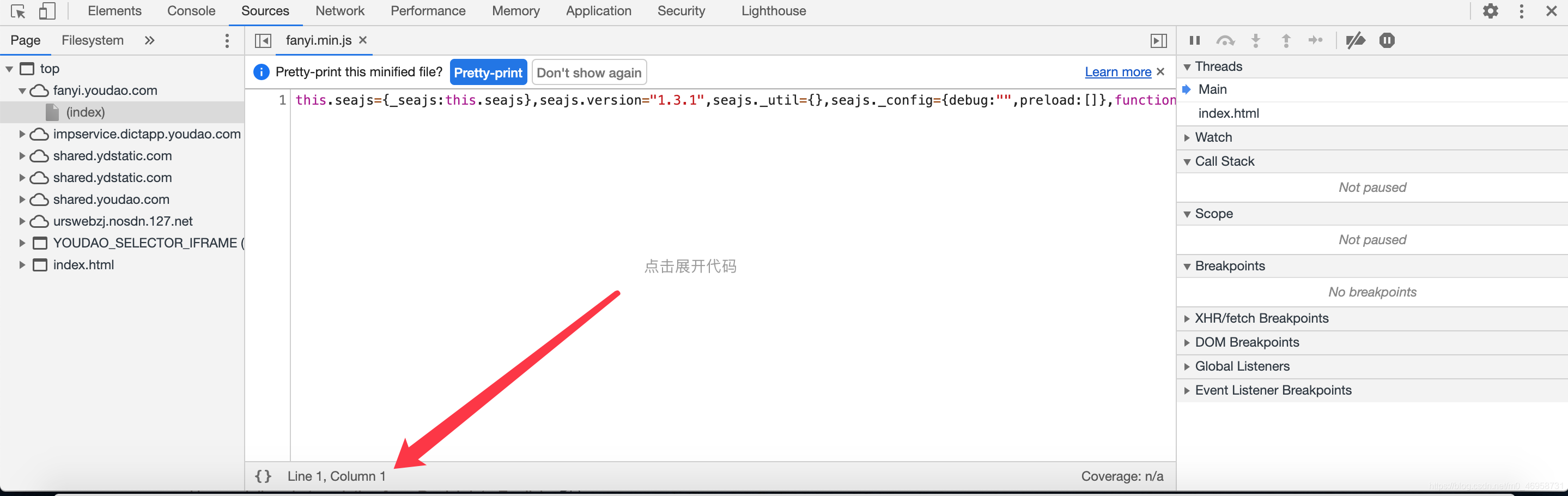
这里获取变量e 需要进入断点模式
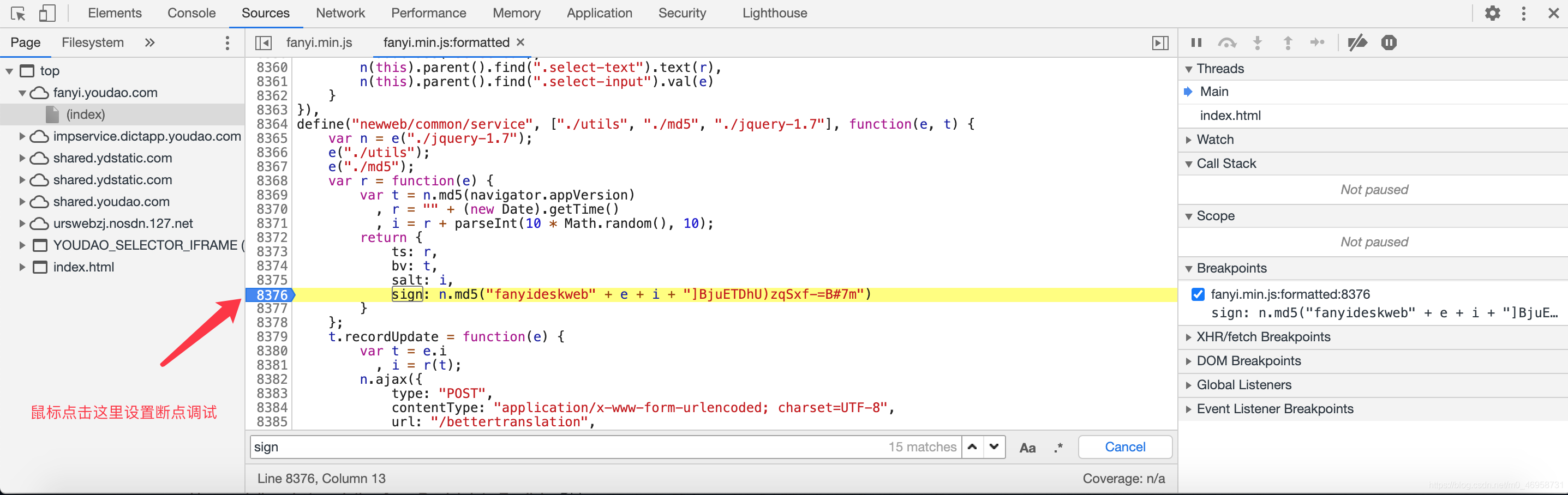
会根据网页变动,随后自动进入断点模式
到这里需要提交的参数就收集完毕了,附上代码
# 获取时间戳
def get_ts():
return str(int(time.time()) * 1000)
# 获取salt参数
def get_salt(ts):
return str(int(ts) + 10 * int(random.random() * 10))
# 获取sign参数
def get_sign(salt):
str1 = text1.get() # 待会我们手动输入的内容
# 根据网页一样对数据进行拼接,将我们知道的参数放进去
str_data = "fanyideskweb" + str(str1) + str(salt) + "]BjuETDhU)zqSxf-=B#7m"
m = hashlib.md5() # 和web一样,通过md5加密
m.update(str_data.encode('utf-8'))  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 962
962

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









