




The prototype of this code comes from the book "Dive into Deep Learning" by Li Mu, Chapter 14.
d2l is a very excellent and convenient framework. However, I don't know how to use d2l to draw dynamic maps. Moreover, my computer always lags when running d2l's plotting library, so I plan to use matplotlib to draw dynamic graphs.
import torch
from torch import nn
import matplotlib.pyplot as plt
import numpy as np
import time
import torch.utils
# Define the device
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# Define the Generator and Discriminator networks
net_G = nn.Sequential(nn.Linear(2, 2)).to(device)
net_D = nn.Sequential(
nn.Linear(2, 5), nn.Tanh(),
nn.Linear(5, 3), nn.Tanh(),
nn.Linear(3, 1)
).to(device)
def update_D(X, Z, net_D, net_G, loss, trainer_D):
"""Update discriminator."""
batch_size = X.shape[0]
# ones and zeros : target labels for real and fake data
ones = torch.ones((batch_size,), device=X.device)
zeros = torch.zeros((batch_size,), device=X.device)
trainer_D.zero_grad()
pred_Y = net_D(X)
fake_X = net_G(Z)
fake_Y = net_D(fake_X.detach())
loss_D = (loss(pred_Y, ones.reshape(pred_Y.shape)) +
loss(fake_Y, zeros.reshape(fake_Y.shape))) / 2
loss_D.backward()
trainer_D.step()
return loss_D
def update_G(Z, net_D, net_G, loss, trainer_G):
"""Update generator."""
batch_size = Z.shape[0]
ones = torch.ones((batch_size,), device=Z.device)
trainer_G.zero_grad()
fake_X = net_G(Z)
fake_Y = net_D(fake_X)
loss_G = loss(fake_Y, ones.reshape(fake_Y.shape))
loss_G.backward()
trainer_G.step()
return loss_G
def train(net_D, net_G, data_iter, num_epochs, lr_D, lr_G, latent_dim, data):
loss = nn.BCEWithLogitsLoss(reduction='sum')
for w in net_D.parameters():
nn.init.normal_(w, 0, 0.02)
for w in net_G.parameters():
nn.init.normal_(w, 0, 0.02)
trainer_D = torch.optim.Adam(net_D.parameters(), lr=lr_D)
trainer_G = torch.optim.Adam(net_G.parameters(), lr=lr_G)
# For plotting
fig, axs = plt.subplots(2, 1, figsize=(5, 5))
axs[0].set_xlabel('Epoch')
axs[0].set_ylabel('Loss')
axs[1].set_xlabel('X1')
axs[1].set_ylabel('X2')
axs[1].set_xlim(-2, 2)
axs[1].set_ylim(-2, 2)
loss_D_list, loss_G_list = [], []
for epoch in range(num_epochs):
timer_start = time.time()
loss_D_total, loss_G_total, num_examples = 0.0, 0.0, 0
for X in data_iter:
X = X.to(device)
batch_size = X.shape[0]
# noise vector for a batch
Z = torch.normal(0, 1, size=(batch_size, latent_dim), device=device)
loss_D_total += update_D(X, Z, net_D, net_G, loss, trainer_D).item()
loss_G_total += update_G(Z, net_D, net_G, loss, trainer_G).item()
num_examples += batch_size
# Compute average losses
loss_D_avg = loss_D_total / num_examples
loss_G_avg = loss_G_total / num_examples
loss_D_list.append(loss_D_avg)
loss_G_list.append(loss_G_avg)
# Generate examples for visualization
# Z is the noise vector for creating synthetic data by Generator
Z = torch.normal(0, 1, size=(100, latent_dim), device=device)
fake_X = net_G(Z).detach().cpu().numpy()
axs[1].clear()
axs[1].scatter(data[:, 0], data[:, 1], label='Real')
axs[1].scatter(fake_X[:, 0], fake_X[:, 1], label='Generated')
axs[1].legend()
# Plot the loss
axs[0].clear()
axs[0].plot(range(1, epoch + 2), loss_D_list, label='Discriminator')
axs[0].plot(range(1, epoch + 2), loss_G_list, label='Generator')
axs[0].legend()
plt.draw()
plt.pause(0.1)
# Print loss and speed
examples_per_sec = num_examples / (time.time() - timer_start)
print(f'Epoch {epoch + 1}, loss_D {loss_D_avg:.3f}, loss_G {loss_G_avg:.3f}, {examples_per_sec:.1f} examples/sec')
plt.show()
X=torch.normal(0.0,1,(1000,2))
A = torch.tensor([[1, 2],
[-0.1, 0.5]])
b = torch.tensor([1, 2])
# data = torch.matmul(X, A) + b
# the label of each row vector is ONE
data = X @ A + b
batch_size=8
data_iter = torch.utils.data.DataLoader(data,batch_size=batch_size)
lr_D,lr_G,latent_dim,num_epochs = 0.05,0.005,2,20
train(net_D,net_G,data_iter,num_epochs,lr_D,lr_G,
latent_dim,data[:100].detach().numpy())
# Example data and parameters
# data = torch.tensor(np.random.randn(100, 2), dtype=torch.float32).to(device)
# data_iter = torch.utils.data.DataLoader(data, batch_size=16, shuffle=True)
# lr_D, lr_G, latent_dim, num_epochs = 0.05, 0.005, 2, 20
# train(net_D, net_G, data_iter, num_epochs, lr_D, lr_G, latent_dim, data.cpu().numpy())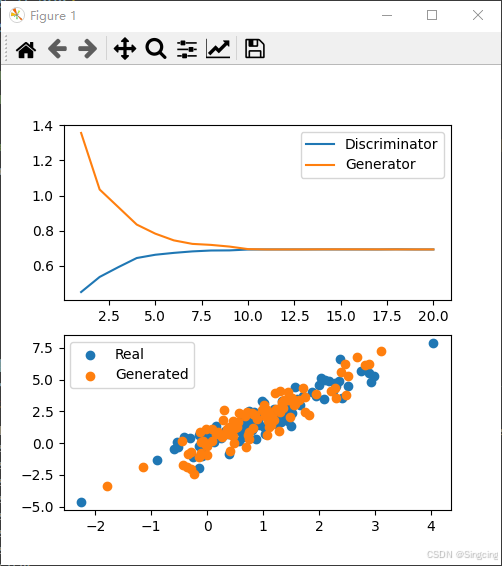


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









