







集合
集合框架概述
- 使用集合存储数据具有一些弊端,如:(1)数组在初始化后,长度就不可变了,不便于扩展。(2)数组中提供的属性和方法少,不易于进行增删改操作,且效率不高,无法获得存储元素的个数(3)数组的存储结构单一,是有序的可重复的。
- 所以我们就需要使用java集合类来进行数据的存储,java集合就像一种容器,可以动态的吧多个对象的引用放到容器中,不仅可以存储数量不等的多个对象,还可以保存具有映射关系的关联数组。
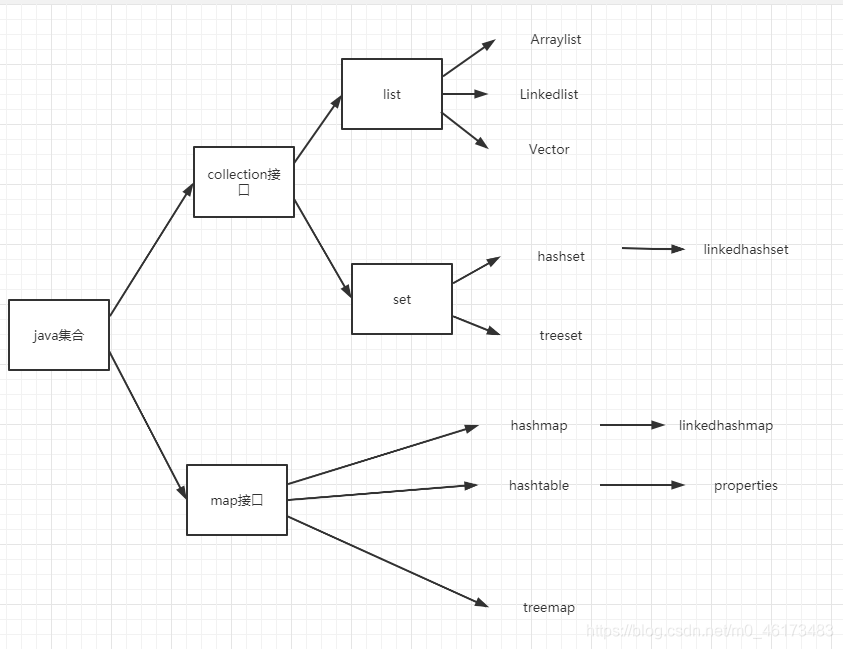
java集合可以分为collection和map两种体系
- collection接口的实现类用来存放单列数据,定义了存储一组数据的集合,其中又分为list接口和set接口
- list接口:存放有序的,可重复的结合 set接口:存放无序的不可重复的集合
- map接口的实现类用来存放单列数据,保存具有映射关系“key-value”对的集合
其中的关系结构如下图:
collection接口
- Collection接口的主要方法(这里用ArrayList作为实现类)
简单的方法这里不作展示,演示一下遍历方法 - 遍历有两种方式,采用迭代器iterator或者使用foreach循环遍历
- 采用迭代器iterator
Iterator iterator = coll.iterator();
while(iterator.hasNext()){
System.out.println(iterator.next());
}
- 采用foreach循环
for(Object o :coll){
System.out.println(o);
}
均可遍历集合
List接口
- List集合类中元素有序且可重复,集合中的每个元素都有其索引,可以根据序号存取容器中的元素
- 主要实现类有Arraylist,linkedarraylist,vector
- 这三个主要实现类有什么异同呢?
- 同:三个都是list接口的实现类,用来存放有序的,可重复的数据
- 异:Arraylist是线程不安全的,效率高,底层用数组存储 linkedlist是用双向链表存储的,当需要频繁的插入删除的时候,效率比Arraylist高 vector是list的古老的实现类,线程安全,效率低
- 这边主要写一下Arraylist的主要方法,list是collection的子接口,所以collection的方法都可以用,除了这些方法,list接口还有自己的方法
set接口
- set接口是collection的子接口,set接口没有另外提供方法
- set集合不允许包含相同的元素,如果试着把相同的元素加入同一个set集合中,则添加操作失败
- set判断两个对象相等是否相同不是用的 == 运算符,而是根据equals方法
- 主要实现类有hashset,linkedhashset,treeset
- 这三个实现类有什么异同呢
- 同:都是set接口的实现类,用来存放无序的不可重复的数据
- 异:hashset是主要实现类,是线程不安全的,可以存储null值 linkedhashset:使用双向链表维护数据的次序,使得遍历的时候,能按照插入的顺序遍历 TreeSet 可以按照添加对象的指定属性进行排序
- 无序性和不可重复性如何理解
- 无序性:不等于随机性,指的是数据插入时的索引是无序的,根据数据的hash值来决定
- 不可重复性:不能添加重复的数据
hashset的数据添加过程:
- 通过数据的hash值通过某种算法得到数据在hashset底层数组中应该存放的位置,并判断当前位置上是否有数据,如果没有,则添加成功,如果已经有数据,需要判断数据是否相同,先比较hash值,如果hash值不同,则添加成功,如果相同,则继续比较equals方法,放回true,添加失败,返回false 添加成功
- 对于同一索引多个数据采用链表存储,jdk7中新的指向旧的,jdk8中旧的指向新的
- 所以在王set中添加的数据类,需要重写equals方法和hashcode方法
map接口
- 存放双列数据,key-value的键值对
- 主要实现类有hashmap,linkedhashmap,hashtable,properties,treemap
- hashmap作为map的主要实现类,是线程不安全的,效率高,可以存储null的key和value
- linkedhashmap保证在遍历时,按照添加顺序遍历
- treemap,保证按照添加的key-value对进行排序,实现排序遍历,此时考虑key的自然排序和定制排序,底层使用红黑树
- hashtable作为古老的实现类,线程安全,但是效率低,不能存储null类型的key和value
- properties常用来处理配置文件,key和value都是string类型,在jdbc连接数据库的时候使用过。durid.priperties文件存放配置信息。
- 对key-value的理解:key是不能重复且无序的,所以可以看成用set存储的,value是可以重复的,用collection存储,一对key-value是一个entry对象,是无序不可重复的 使用set存储所有的entry
haspmap的数据添加过程: - 通过key所在类的hashcode方法计算hash值,在通过hash值得到entry在数组中应该存放的位置,如果该位置为空,则添加成功,如果该位置不为空(意味着该索引有一个或多个数据以链表的形式存在),比较key和已经存在的数据的hash值,如果不相同则添加成功,如果相同,继续比较key所在类的equals,如果返回true则插入失败,返回false,插入成功。以链表的形式存储,jdk7新的指向旧的,jdk8旧的指向新的
- 在不断的添加过程中,会设计到扩容问题,扩容因子0.75,会默认扩容为原来的两倍,并将原来的数据复制过来


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









