



 本文介绍了余弦距离和余弦相似度的概念,通过向量空间中的角度来衡量两个字符串或向量的相似程度,尤其在非直角三角形和多维空间中的应用。通过实际例子和代码展示了如何使用CosineSimilarity计算文本相似度。
本文介绍了余弦距离和余弦相似度的概念,通过向量空间中的角度来衡量两个字符串或向量的相似程度,尤其在非直角三角形和多维空间中的应用。通过实际例子和代码展示了如何使用CosineSimilarity计算文本相似度。
实现两个字符串内容的相似度
概念:余弦距离,也称为余弦相似度,是用向量空间中两个向量夹角的余弦值作为衡量两个个体间差异的大小的度量。余弦值越接近1,就表明夹角越接近0度,也就是两个向量越相似,这就叫"余弦相似性"。
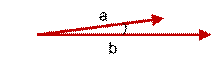
上图两个向量a,b的夹角很小可以说a向量和b向量有很高的的相似性,极端情况下,a和b向量完全重合。如下图:

如上图二:可以认为a和b向量是相等的,也即a,b向量代表的文本是完全相似的,或者说是相等的。如果a和b向量夹角较大,或者反方向。如下图
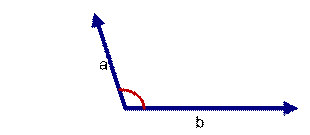
如上图三: 两个向量a,b的夹角很大可以说a向量和b向量有很低的的相似性,或者说a和b向量代表的文本基本不相似。
想到余弦公式,最基本计算方法就是初中的最简单的计算公式,计算夹角
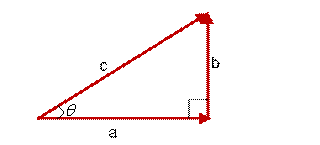
图(4)
的余弦定值公式为:

但是这个是只适用于直角三角形的,而在非直角三角形中

图(5)
三角形中边a和b的夹角 的余弦计算公式为:
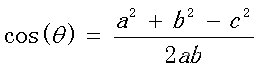
公式(2)
在向量表示的三角形中,假设a向量是(x1, y1),b向量是(x2, y2),那么可以将余弦定理改写成下面的形式:
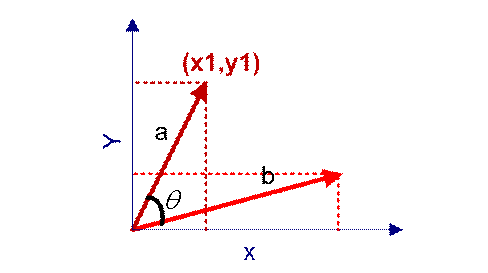
图(6)
向量a和向量b的夹角 的余弦计算如下
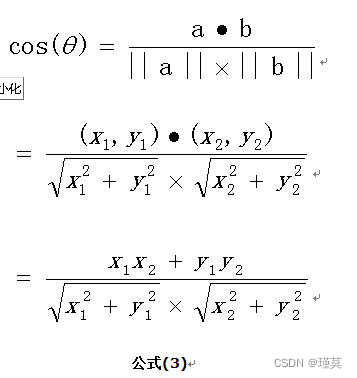
扩展,如果向量a和b不是二维而是n维,上述余弦的计算法仍然正确。假定a和b是两个n维向量,a是 ,b是 ,则a与b的夹角 的余弦等于:
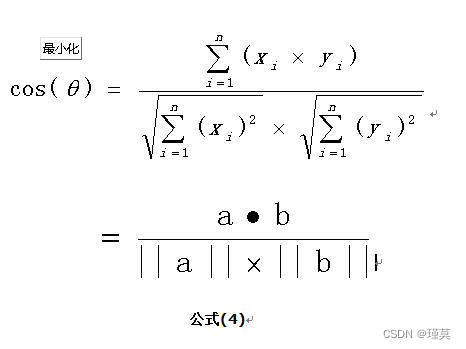
余弦值越接近1,就表明夹角越接近0度,也就是两个向量越相似,夹角等于0,即两个向量相等,这就叫"余弦相似性"。
另外:余弦距离使用两个向量夹角的余弦值作为衡量两个个体间差异的大小。相比欧氏距离,余弦距离更加注重两个向量在方向上的差异。
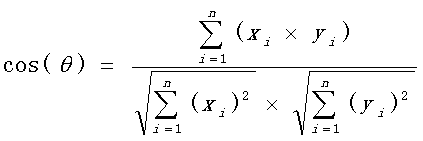
计算公式
公式计算事例如下:
句子A:(1,1,2,1,1,1,0,0,0)
句子B:(1,1,1,0,1,1,1,1,1)
运用上面的公式:计算如下:
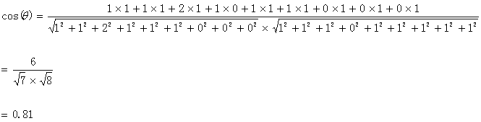
计算结果中夹角的余弦值为0.81非常接近于1,所以,上面的句子A和句子B是基本相似的
代码事例如下:
/**
-
计算两个字符串的相识度
*/public class Similarity {public static final String content1=“今天A和B一起去爬山,A说今天太阳真热,山下比山上买水价格便宜多了”;
public static final String content2=“今天A和C一起去爬山,C说今天太阳真热,山上比山下买水价格还贵”;
public static void main(String[] args) {
double score=CosineSimilarity.getSimilarity(content1,content2); System.out.println("相似度:"+score); score=CosineSimilarity.getSimilarity(content1,content1); System.out.println("相似度:"+score);}
}
CosineSimilarity(相似率具体实现工具类)
import com.jincou.algorithm.tokenizer.Tokenizer;
import com.jincou.algorithm.tokenizer.Word;
import org.apache.commons.lang3.StringUtils;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.util.CollectionUtils;
import java.math.BigDecimal;
import java.util.*;
import java.util.concurrent.ConcurrentHashMap;
import java.util.concurrent.atomic.AtomicInteger;
public class CosineSimilarity {
protected static final Logger LOGGER = LoggerFactory.getLogger(CosineSimilarity.class);
public static double getSimilarity(String text1, String text2) {
if (StringUtils.isBlank(text1) && StringUtils.isBlank(text2)) {
return 1.0;
}
if (StringUtils.isBlank(text1) || StringUtils.isBlank(text2)) {
return 0.0;
}
List<Word> words1 = Tokenizer.segment(text1);
List<Word> words2 = Tokenizer.segment(text2);
return getSimilarity(words1, words2);
}
public static double getSimilarity(List<Word> words1, List<Word> words2) {
double score = getSimilarityImpl(words1, words2);
score = (int) (score * 1000000 + 0.5) / (double) 1000000;
return score;
}
public static double getSimilarityImpl(List<Word> words1, List<Word> words2) {
taggingWeightByFrequency(words1, words2);
Map<String, Float> weightMap1 = getFastSearchMap(words1);
Map<String, Float> weightMap2 = getFastSearchMap(words2);
Set<Word> words = new HashSet<>();
words.addAll(words1);
words.addAll(words2);
AtomicFloat ab = new AtomicFloat();// a.b
AtomicFloat aa = new AtomicFloat();// |a|的平方
AtomicFloat bb = new AtomicFloat();// |b|的平方
words.parallelStream().forEach(word -> {
Float x1 = weightMap1.get(word.getName());
Float x2 = weightMap2.get(word.getName());
if (x1 != null && x2 != null) {
float oneOfTheDimension = x1 * x2;
ab.addAndGet(oneOfTheDimension);
}
if (x1 != null) {
float oneOfTheDimension = x1 * x1;
aa.addAndGet(oneOfTheDimension);
}
if (x2 != null) {
float oneOfTheDimension = x2 * x2;
bb.addAndGet(oneOfTheDimension);
}
});
double aaa = Math.sqrt(aa.doubleValue());
double bbb = Math.sqrt(bb.doubleValue());
BigDecimal aabb = BigDecimal.valueOf(aaa).multiply(BigDecimal.valueOf(bbb));
double cos = BigDecimal.valueOf(ab.get()).divide(aabb, 9, BigDecimal.ROUND_HALF_UP).doubleValue();
return cos;
}
protected static void taggingWeightByFrequency(List<Word> words1, List<Word> words2) {
if (words1.get(0).getWeight() != null && words2.get(0).getWeight() != null) {
return;
}
Map<String, AtomicInteger> frequency1 = getFrequency(words1);
Map<String, AtomicInteger> frequency2 = getFrequency(words2);
words1.parallelStream().forEach(word -> word.setWeight(frequency1.get(word.getName()).floatValue()));
words2.parallelStream().forEach(word -> word.setWeight(frequency2.get(word.getName()).floatValue()));
}
private static Map<String, AtomicInteger> getFrequency(List<Word> words) {
Map<String, AtomicInteger> freq = new HashMap<>();
words.forEach(i -> freq.computeIfAbsent(i.getName(), k -> new AtomicInteger()).incrementAndGet());
return freq;
}
private static String getWordsFrequencyString(Map<String, AtomicInteger> frequency) {
StringBuilder str = new StringBuilder();
if (frequency != null && !frequency.isEmpty()) {
AtomicInteger integer = new AtomicInteger();
frequency.entrySet().stream().sorted((a, b) -> b.getValue().get() - a.getValue().get()).forEach(
i -> str.append("\t").append(integer.incrementAndGet()).append("、").append(i.getKey()).append("=")
.append(i.getValue()).append("\n"));
}
str.setLength(str.length() - 1);
return str.toString();
}
protected static Map<String, Float> getFastSearchMap(List<Word> words) {
if (CollectionUtils.isEmpty(words)) {
return Collections.emptyMap();
}
Map<String, Float> weightMap = new ConcurrentHashMap<>(words.size());
words.parallelStream().forEach(i -> {
if (i.getWeight() != null) {
weightMap.put(i.getName(), i.getWeight());
} else {
LOGGER.error("no word weight info:" + i.getName());
}
});
return weightMap;
}
}
AtomicFloat原子类
import java.util.concurrent.atomic.AtomicInteger;
/**
-
jdk没有AtomicFloat,写一个
*/
public class AtomicFloat extends Number {private AtomicInteger bits;
public AtomicFloat() {
this(0f);
}public AtomicFloat(float initialValue) {
bits = new AtomicInteger(Float.floatToIntBits(initialValue));
}public final float addAndGet(float delta) {
float expect;
float update;
do {
expect = get();
update = expect + delta;
} while (!this.compareAndSet(expect, update));return update;}
public final float getAndAdd(float delta) {
float expect;
float update;
do {
expect = get();
update = expect + delta;
} while (!this.compareAndSet(expect, update));return expect;}
public final float getAndDecrement() {
return getAndAdd(-1);
}public final float decrementAndGet() {
return addAndGet(-1);
}public final float getAndIncrement() {
return getAndAdd(1);
}public final float incrementAndGet() {
return addAndGet(1);
}public final float getAndSet(float newValue) {
float expect;
do {
expect = get();
} while (!this.compareAndSet(expect, newValue));return expect;}
public final boolean compareAndSet(float expect, float update) {
return bits.compareAndSet(Float.floatToIntBits(expect), Float.floatToIntBits(update));
}public final void set(float newValue) {
bits.set(Float.floatToIntBits(newValue));
}public final float get() {
return Float.intBitsToFloat(bits.get());
}@Override
public float floatValue() {
return get();
}@Override
public double doubleValue() {
return (double) floatValue();
}@Override
public int intValue() {
return (int) get();
}@Override
public long longValue() {
return (long) get();
}@Override
public String toString() {
return Float.toString(get());
}
}
Word(封装分词结果
import lombok.Data;
import java.util.Objects;
/**
-
封装分词结果*/
@Data
public class Word implements Comparable {// 词名
private String name;
// 词性
private String pos;
// 权重,用于词向量分析
private Float weight;public Word(String name, String pos) {
this.name = name;
this.pos = pos;
}@Override
public int hashCode() {
return Objects.hashCode(this.name);
}@Override
public boolean equals(Object obj) {
if (obj == null) {
return false;
}
if (getClass() != obj.getClass()) {
return false;
}
final Word other = (Word) obj;
return Objects.equals(this.name, other.name);
}@Override
public String toString() {
StringBuilder str = new StringBuilder();
if (name != null) {
str.append(name);
}
if (pos != null) {
str.append(“/”).append(pos);
}return str.toString();}
@Override
public int compareTo(Object o) {
if (this == o) {
return 0;
}
if (this.name == null) {
return -1;
}
if (o == null) {
return 1;
}
if (!(o instanceof Word)) {
return 1;
}
String t = ((Word) o).getName();
if (t == null) {
return 1;
}
return this.name.compareTo(t);
}
}
Tokenizer(分词工具类)
import com.hankcs.hanlp.HanLP;
import com.hankcs.hanlp.seg.common.Term;
import java.util.List;
import java.util.stream.Collectors;
/**
-
中文分词工具类*/
public class Tokenizer {public static List segment(String sentence) {
List<Term> termList = HanLP.segment(sentence); System.out.println(termList.toString()); return termList.stream().map(term -> new Word(term.word, term.nature.toString())).collect(Collectors.toList());}
}


















 2930
2930

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











