




 本文详细介绍了反向传播(BP)算法在神经网络中的应用,以及如何利用梯度下降、MomentumOptimizer和AdamOptimizer进行参数优化。反向传播通过计算损失函数的梯度来更新权重,以最小化损失。文章还讨论了如何根据训练过程选择合适的优化器,以提高模型的训练效率和性能。
本文详细介绍了反向传播(BP)算法在神经网络中的应用,以及如何利用梯度下降、MomentumOptimizer和AdamOptimizer进行参数优化。反向传播通过计算损失函数的梯度来更新权重,以最小化损失。文章还讨论了如何根据训练过程选择合适的优化器,以提高模型的训练效率和性能。
一、什么是反向传播?
反向传播(英语:Backpropagation,缩写为BP)是“误差反向传播”的简称,是一种与最优化方法(如梯度下降法)结合使用的,用来训练人工神经网络的常见方法。该方法计算对网络中所有权重计算损失函数的梯度。这个梯度会反馈给最优化方法,用来更新权值以最小化损失函数。 在神经网络上执行梯度下降法的主要算法。该算法会先按前向传播方式计算(并缓存)每个节点的输出值,然后再按反向传播遍历图的方式计算损失函数值相对于每个参数的偏导数。
二、反向传播有什么作用?
该方法对网络中所有权重计算损失函数的梯度。这个梯度会反馈给最优化方法,用来更新权值以最小化损失函数。
反向传播要求有对每个输入值期望得到的已知输出,来计算损失函数的梯度。因此,它通常被认为是一种监督式学习方法,虽然它也用在一些无监督网络(如自动编码器)中。它是多层前馈网络的Delta规则的推广,可以用链式法则对每层迭代计算梯度。反向传播要求人工神经元(或“节点”)的激励函数可微。
三、反向传播是怎么运作的?
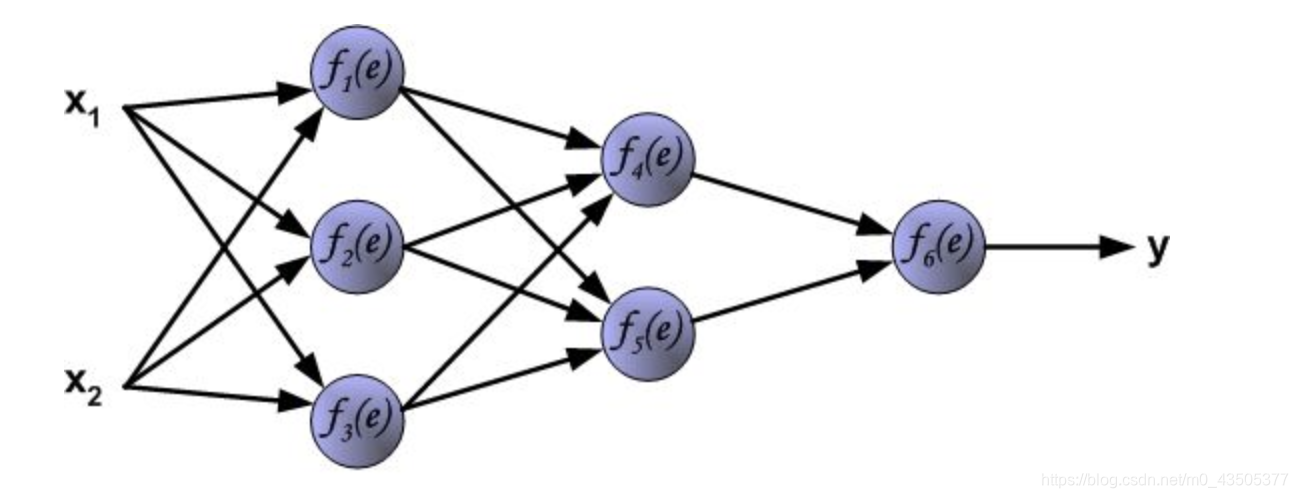
BP网络的结构降法的基础上。BP网络的输入输出关系实质上是一种映射关系:一个 输入m输出的BP神经网络所完成的功能是从 一维欧氏空间向m维欧氏空间中一有限域的连续映射,这一映射具有高度非线性。它的信息处理能力来源于简单非线性函数的多次复合,因此具有很强的函数复现能力。这是BP算法得以应用的基础。
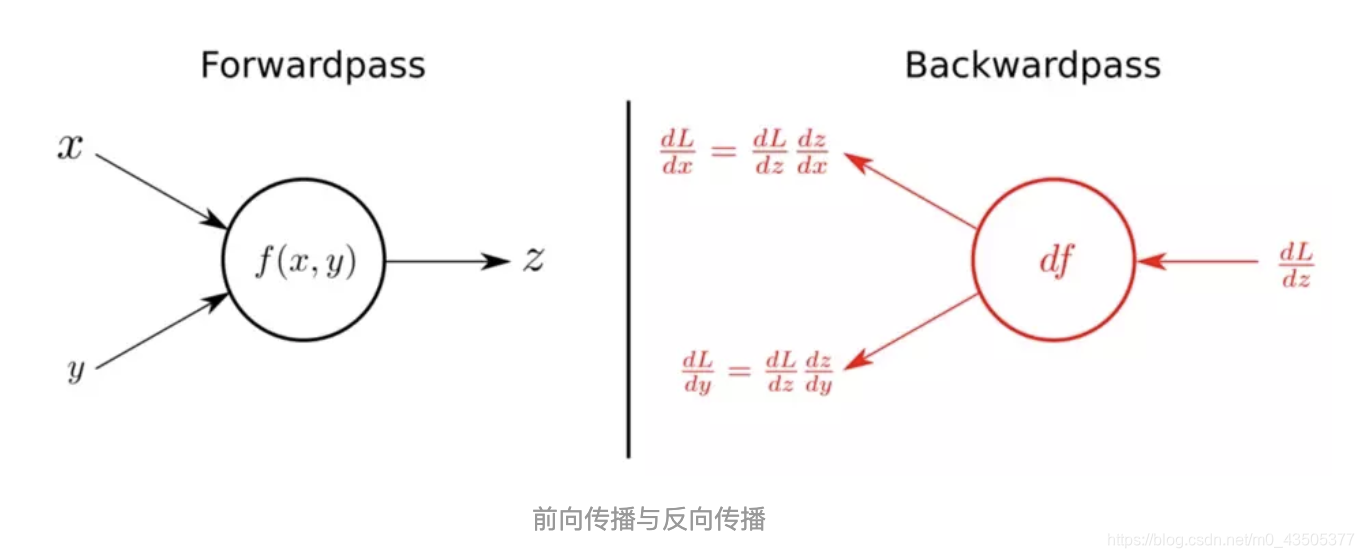
反向传播算法主要由两个环节(激励传播、权重更新)反复循环迭代,直到网络的对输入的响应达到预定的目标范围为止。
BP算法的学习过程由正向传播过程和反向传播过程组成。在正向传播过程中,输入信息通过输入层经隐含层,逐层处理并传向输出层。如果在输出层得不到期望的输出值,则取输出与期望的误差的平方和作为目标函数,转入反向传播,逐层求出目标函数对各神经元权值的偏导数,构成目标函数对权值向量的梯量,作为修改权值的依据,网络的学习在权值修改过程中完成。误差达到所期望值时,网络学习结束。
每次迭代中的传播环节包含两步:
- (前向传播阶段)将训
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2335
2335

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









