




从报错中学习:为何url和jdbc-url让我焦头烂额
踩坑记录:最近有一个项目需要分库分表,我在测试多数据源操作数据库的时候,由于对连接池和数据源配置存在盲区,报错频繁报错
jdbcUrl is required with driverClassName.。经过排查,发现是连接池属性配置错误。本文还原完整排查过程。
一、诡异报错现场
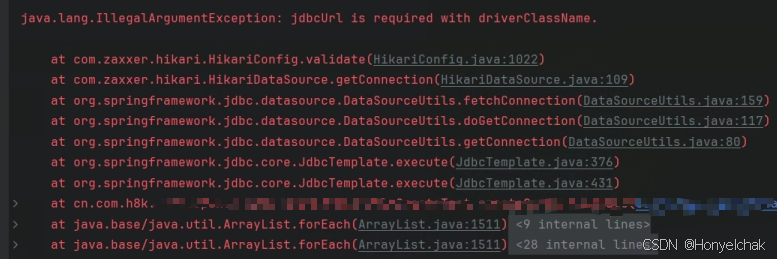
错误堆栈关键片段:
java.lang.IllegalArgumentException: jdbcUrl is required with driverClassName.
at com.zaxxer.hikari.HikariConfig.validate(HikariConfig.java:1022)
at com.zaxxer.hikari.HikariDataSource.getConnection(HikariDataSource.java:109)
at org.springframework.jdbc.datasource.DataSourceUtils.fetchConnection(DataSourceUtils.java:159)
at org.springframework.jdbc.datasource.DataSourceUtils.doGetConnection(DataSourceUtils.java:117)
at org.springframework.jdbc.datasource.DataSourceUtils.getConnection(DataSourceUtils.java:80)
at org.springframework.jdbc.core.JdbcTemplate.execute(JdbcTemplate.java:376)
at org.springframework.jdbc.core.JdbcTemplate.execute(JdbcTemplate.java:431)
at cn.com.h8k.onecoupon.engine.UserCouponTableCreateTest.createCouponTemplate(UserCouponTableCreateTest.java:64)
at java.base/java.util.ArrayList.forEach(ArrayList.java:1511)
at java.base/java.util.ArrayList.forEach(ArrayList.java:1511)
at com.intellij.rt.junit.JUnitStarter.main(JUnitStarter.java:55)
最迷惑的配置:
#错误配置!同时出现jdbc-url和url会怎样?
spring:
datasource:
url: jdbc:mysql://localhost:3306/test
jdbc-url: jdbc:mysql://localhost:3306/real_db
username: root
password: 123456
二、为什么不能混用?
HikariCP的潜规则- 底层逻辑:Spring Boot优先识别jdbc-url
- 冲突后果:url会被自动忽略
- 致命陷阱:如果同时配置HikariCP&Druid
type: com.alibaba.druid.pool.DruidDataSource # 实际用的是Druid! jdbc-url: ... # Druid不识别这个字段!
- 不同连接池的命名差异
| HikariCP | Druid | Tomcat JDBC | |
|---|---|---|---|
| 连接地址 | jdbc-url | url | url |
| 超时配置 | connection-timeout | maxWait | max-wait |
- SpringBoot版本适配
| 版本 | 默认连接池 |
|---|---|
| 1.x | Tomcat Pool |
| 2.x以后包括3.x | HikariCP |
三、正确配置模板
- 使用HikariCP连接池的数据库配置
spring:
datasource:
# 核心配置(必须用jdbc-url)
jdbc-url: "jdbc:mysql://${MYSQL_HOST:localhost}:3306/core_db?characterEncoding=UTF-8"
username: app_user
password: ${DB_PASSWORD}
driver-class-name: com.mysql.cj.jdbc.Driver
# Hikari专属配置
hikari:
pool-name: OrderAPIPool
maximum-pool-size: 20
connection-timeout: 1000
- 使用Druid连接池的配置
spring:
datasource:
# 此处必须用url!
url: "jdbc:mysql://db-prod.example.com:3306/finance?useSSL=true"
username: dr_admin
password: ${PROD_DB_PWD}
driver-class-name: com.mysql.cj.jdbc.Driver
# Druid专属配置
druid:
initial-size: 5
max-active: 20
filters: stat,wall # 启用防火墙
四、高频踩坑场景
场景1:直接复制代码导致冲突
# 错误的示范(来自某网课代码)
spring:
datasource:
url: jdbc:mysql://localhost:3306/test # 被下面覆盖
jdbc-url: jdbc:mysql://localhost:3306/real # Hikari优先使用
type: com.alibaba.druid.pool.DruidDataSource # Druid不认识jdbc-url!
#现象:Druid无法获取连接地址,启动时报URL未配置
场景2:多数据源配置混淆
datasource:
order:
jdbc-url: ... # 正确
user:
url: ... # 错误!应该保持命名统一
#后果:第二个数据源初始化失败
四、多数据源架构实现(生产配置范例)
配置规范:
- 使用独立命名空间区分数据源
- 主库标记@Primary注解
- 配置隔离:事务管理器与JPA实体分开绑定
# 读写主库
spring.datasource.primary.jdbc-url=jdbc:mysql://master-db:3306/core
spring.datasource.primary.hikari.connection-init-sql=SET NAMES utf8mb4
# 报表从库
spring.datasource.replica.jdbc-url=jdbc:mysql://replica-db:3306/report
spring.datasource.replica.hikari.read-only=true
核心Java配置段
@Configuration
@EnableTransactionManagement
public class MultiDataSourceConfig {
@Primary
@Bean(name = "primaryDS")
@ConfigurationProperties(prefix = "spring.datasource.primary")
public DataSource masterDataSource() {
return DataSourceBuilder.create().build(); // Hikari连接池写这个
return DruidDataSourceBuilder.create().build(); // Druid连接池写这个
}
@Bean(name = "replicaDS")
@ConfigurationProperties(prefix = "spring.datasource.replica")
public DataSource replicaDataSource() {
return DataSourceBuilder.create().build(); // Hikari连接池写这个
return DruidDataSourceBuilder.create().build(); // Druid连接池写这个
}
}


















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











