






描述
输入一颗二叉树的根节点root和一个整数expectNumber,找出二叉树中结点值的和为expectNumber的所有路径。
1.该题路径定义为从树的根结点开始往下一直到叶子结点所经过的结点
2.叶子节点是指没有子节点的节点
3.路径只能从父节点到子节点,不能从子节点到父节点
4.总节点数目为n
如二叉树root为{10,5,12,4,7},expectNumber为22
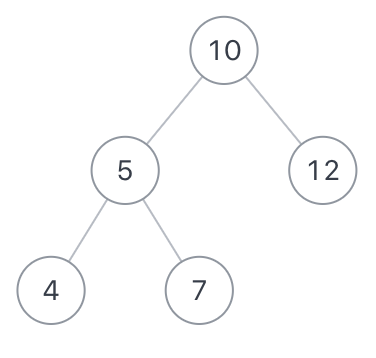
则合法路径有[[10,5,7],[10,12]]
数据范围:
树中节点总数在范围 [0, 5000] 内
-1000 <= 节点值 <= 1000
-1000 <= expectNumber <= 1000
示例1
输入:
{10,5,12,4,7},22
复制返回值:
[[10,5,7],[10,12]]
复制说明:
返回[[10,12],[10,5,7]]也是对的
示例2
输入:
{10,5,12,4,7},15
复制返回值:
[]
小白也能懂】二叉树中和为某一值的路径
发表于 2020-02-09 20:11:05
题目描述
输入一颗二叉树的跟节点和一个整数,打印出二叉树中结点值的和为输入整数的所有路径。路径定义为从树的根结点开始往下一直到叶结点所经过的结点形成一条路径。(注意: 在返回值的list中,数组长度大的数组靠前)
- 首先我们可以发现,我们需要遍历整个二叉树,所以我们需要一个辅助function来帮助我们遍历每个节点。在此时我们可以运用DFS
- 然后,我们需要注意的是,我们同时需要一个Arraylist帮助我们储存我们来到遍历的当前节点之前的路径
- 接着,我们需要一个Arraylist<ArrayList<integer>>来作为我们最后需要返回的结果,来储存所有2里符合条件的Arraylist</integer>
这题有一个重点,就是 路径定义为从树的根结点开始往下一直到叶结点所经过的结点形成一条路径, 所以我们要确保最后一个加进去Arraylist的节点为叶节点,即确保当前遍历的节点无左孩子也无右孩子。
完整java解析如下:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 |
|

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









