




 本文提出了一种新的程序理解方法,利用图神经网络捕获程序的语法和语义信息,以解决变量命名和变量误用问题。
本文提出了一种新的程序理解方法,利用图神经网络捕获程序的语法和语义信息,以解决变量命名和变量误用问题。
题目: Learning to Represent Programs with Graphs
作者: Miltiadis Allamanis, Marc Brockschmidt, Mahmoud Khademi
单位: Microsoft Research, Simon Fraser University
出版: ICLR 2018
解决的问题
以往将深度学习与代码表达结合的工作更多只是抓住了代码浅层的文本结构信息。这样的模型错失了抓住代码丰富语义的机会。在这篇文章中我们通过增加两种信息在一定程度上弥补了这一损失:数据流和类型层级。我们将程序编码成图,图的边代表语法关系(前/后token)以及语义关系(上次在这里使用的变量,参数的形参叫做stream,等)。直接将这些语义作为结构化的机器学习模型输入能够减少对训练数据量的要求。
我们通过两个任务来说明方法的有效性,一是变量命名任务——给出一些源码,正确的变量名能够以一些子token的形式被推断出来。二是变量误用预测——网络用来推断哪个变量应该在程序的某个位置使用。
VarNaming
文中没有对问题下定义,给的参考文献里也没有明确的指出这是个什么问题。但是根据后面文中的做法来推断吧,应该就是对subtoken进行分类的,判断某个subtoken应不应该包含在这个变量名里。
VarMisuse
变量误用预测的任务就是预测出下图中标黄的clazz的用法是错的,实际上出现在这里的应该是first。具体对这个任务进行描述的话是:我们可以将一个源码文件视为一个token的序列 t 0 , . . . , t N t_0, ..., t_N t0,...,tN,其中一些token t λ 0 , t λ 1 , . . . t_{\lambda_0}, t_{\lambda_1}, ... tλ0,tλ1,...是变量。令 V t \mathbb{V}_t Vt为所有在位置 t t t可以出现的,不会导致编译错误的变量集合。我们将我们想要预测的某位置的token称为槽。我们为每个槽 t o k λ tok_\lambda tokλ分别定义任务:给出 t 0 , . . . t λ − 1 , t λ + 1 , . . . , t N t_0, ... t_{\lambda-1}, t_{\lambda+1}, ..., t_N t0,...tλ−1,tλ+1,...,tN,正确从 V t λ \mathbb{V}_{t_\lambda} Vtλ中选出 t λ t_\lambda tλ。在训练和实验评估过程中假设只有一个token符合要求,然而在实际应用中槽中正确的值可能不止一个(指向同一块内存的几个变量名可能都符合要求)。
方法
门控图神经网络(Li et al. 2015)
门控图神经网络中的图
G
=
(
V
,
E
,
X
)
\mathcal{G}=(\mathcal{V}, \mathbf{\mathcal{E}}, \boldsymbol{X})
G=(V,E,X)是由一系列结点
V
\mathcal{V}
V,结点特征
X
\boldsymbol{X}
X,以及一个有向边集合
E
=
(
E
1
,
⋯
 
,
E
K
)
\mathbf{\mathcal{E}}=(\mathcal{E}_1, \cdots, \mathcal{E}_K)
E=(E1,⋯,EK)组成,其中K是边的类型数量。我们将每个结点
v
∈
V
\mathcal{v} \in \mathcal{V}
v∈V的特征表示为一个实值向量
x
(
v
)
∈
R
D
\boldsymbol{x}^{(v)} \in \mathbb{R}^D
x(v)∈RD,也就是对结点字符串标签的一个编码。
我们又将每个结点
v
v
v与一个状态向量
h
(
v
)
\boldsymbol{h}^{(v)}
h(v)对应,用
x
(
v
)
\boldsymbol{x}^{(v)}
x(v)来初始化。状态向量和特征向量维度相同。为在图中传播信息,类型为k的消息可以通过每个结点v传播给它的邻居,消息是利用状态向量计算的,即
m
k
(
v
)
=
f
k
(
h
(
v
)
)
\boldsymbol{m}_k^{(v)} = f_k(\boldsymbol{h}^{(v)})
mk(v)=fk(h(v))。这里的
f
k
f_k
fk可以是任意函数。我们选择了一个线性的函数。通过在同一时间计算所有边的消息,所有的状态都同时被更新。特别地,结点v的新状态是通过聚集所有进入的消息来计算的。
m
~
(
v
)
=
g
(
{
m
k
(
u
)
}
∣
u
和
v
之
间
有
类
型
为
k
的
边
)
\tilde{m}^{(v)} = g(\{ \boldsymbol{m_k^{(u)} \} | u和v之间有类型为k的边 })
m~(v)=g({mk(u)}∣u和v之间有类型为k的边)
其中g是一个聚合函数,我们这里就是做了个简单加和。给出了聚合后的消息和当前状态向量,下一时刻的状态
h
′
(
v
)
=
G
R
U
(
m
~
(
v
)
,
h
(
v
)
)
\boldsymbol{h}^{'(v)} = GRU(\tilde{\boldsymbol{m}}^{(v)}, \boldsymbol{h}^{(v)})
h′(v)=GRU(m~(v),h(v)) ,GRU是门控循环单元。上面提到的过程会重复固定的时间步,然后我们将最后一步得到的状态向量当作结点的向量表示。
程序图
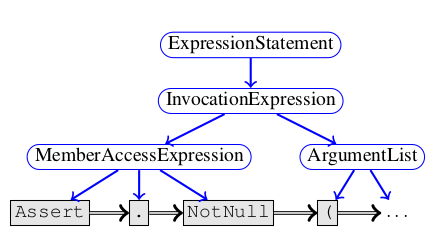
我们用程序图来表示token之间的语法和语义关系,并且用不同类型的边来模拟token间的语法和语义关系。程序图的骨架是程序的抽象语法树,叶子结点表示为源码中的token。我们利用Child边来连接结点。由于这样并没有对一个语法结点的孩子排序,我们又添加了一个NextToken边来连接每个语法token和它的兄弟。下图是一个例子:
为抓住控制流和数据流,我们为连接不同的与变量相关的语法token的应用和更新添加了额外的边。对于一个token
v
v
v,令
D
R
(
v
)
\mathcal{D}^{R}(v)
DR(v)为上次变量v用到的语法token集合。这一集合可能包含多个结点(例如在条件语句后变量在两个分支都有使用),甚至对于循环来说会包含它后面的token。类似地,用
D
W
(
v
)
\mathcal{D}^W(v)
DW(v)表示变量上次对变量进行写入的语法token的集合。利用这些,我们添加了LastRead边和LastWrite边。并且,无论何时我们观察到赋值语句 v = expr,我们将v用ComputedFrom边连接到所有expr中出现过的变量token。下面是一个例子:
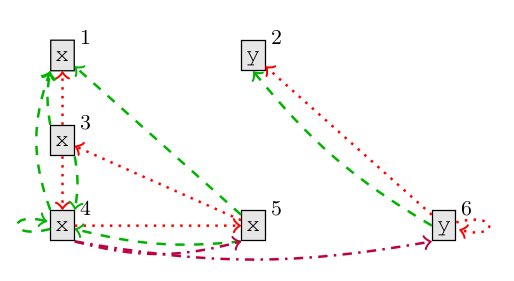
这张图是下面代码的数据流边,其中红色点线代表LastUse边,绿色线代表LastWrite边,深紫色(?)代表ComputedFrom边:
(x1, y2) = Foo();
while (x3 > 0)
x4 = x5 + y6
简单解释下这两部分,可以看到一个变量token是能够在语法树叶子结点中出现多次的,例如上面这段代码中的x出现了4次,y出现2次。以x4为例,这个token结点首先是以LastUse边指向了x5,是说x4上次用到了x5给它赋值。而x4又被x3用LastUse所指,就是说x3上次用到了x4,这个是什么时候呢?就是上一次循环结束时x取值x4,而本次循环条件判断时x3的取值就是x4。再看LastWrite,从x4分别有一条出边到x1和x4,表示x4上一次写入可能是x1,也可能是上一次循环的x4,我理解的写入就是这个变量上次被赋值的地方。所以x3和x5上一次被赋值也是上一次循环的x4。而ComputedFrom就比较好理解,x4是由x5和y6赋值得到的,所以x4有两条出边,指向x5和y6。我的理解是,LastUse和LastWrite是变量内部的事情,而ComputedFrom可以连接不同变量。
我们继续扩展这个图,通过LastLexicalUse边来连接对所有相同变量的使用。例如在if(...) {... v...} else {... v...}中,我们把两个v连接起来。我们也把返回值token用ReturnsTo边连接到方法的声明上。受Rice等的启发,我们用FormalArgName将方法调用里的实参连接到它们所对应的形参,也就是说我们看到一个方法调用Foo(bar)和方法声明Foo(InputStream stream)时,我们将token bar连接到token stream。最后,我们将所有与一个变量有关的token用边GuardedBy和GuardedByNegation连接为闭合的保护表达式。例如,对于if(x > y) {...x...} else {...y...},我们从x到与x > y相关的AST结点添加一条GuardedBy边,从y到与x > y相关的AST结点添加一条GuardedByNegation边。
最后,对于所有类型的边我们引入它们的后向边(相当于转置了图的邻接矩阵),把边的数量和种类都加倍。后向边有助于在GGNN中快速传播信息。
利用变量类型信息
我们假设有一种静态类型的语言,并且源码可以被编译,因此所有变量都有已知的类型 τ ( v ) \tau(v) τ(v),为利用这一信息,我们为所有已知类型定义一个可学习的embedding函数 r ( τ ) \boldsymbol{r}(\tau) r(τ),对所有未知的类型增加一个“UNKTYPE”。对于那些面向对象的语言, 我们也会利用它们丰富的层级结构。对于面向对象语言,我们将一个变量的类型 τ ( v ) \tau (v) τ(v)映射到它的父类,也就是说 τ ∗ ( v ) = { τ ( v ) 的 父 类 型 } ⋃ { τ ( v ) } \tau ^*(v) = \{ \tau(v) 的父类型\} \bigcup \{ \tau(v) \} τ∗(v)={τ(v)的父类型}⋃{τ(v)},然后我们计算这种表示的表达:对于变量 v v v,我们从 τ ∗ ( v ) \tau^*(v) τ∗(v) 集合中按位(每一维度)选择最大的 r ( τ ) \boldsymbol{r}(\tau) r(τ)作为它的表达。这是一种普通的最大池化思想。在训练期间,我们随机选择一个 τ ∗ ( v ) \tau^*(v) τ∗(v)的非空子集。这样的做法类似于dropout,使我们能够对所有的类型都学到好的表示。
初始化结点表示
我们将token的文本表示与它的类型相结合来计算结点的初始状态。具体地,我们利用驼峰表示和帕斯卡表示法将结点名字切分成subtoken,然后将每个subtoken的表示取平均来得到结点名字的表示。最后,我们把之前学习到的类型表示 τ ∗ ( v ) \tau^*(v) τ∗(v)与结点名字的表示连接起来,然后通过一个线性层来得到图中每个结点的最初表示。
针对VARNAMING的程序图
给出一个程序和一个变量 v v v,我们像上面那样构建一个程序图,并且将所有与 v v v相关的变量名替换成一个 < S L O T > <SLOT> <SLOT> token。为预测这个变量名,我们利用初始结点标签来运行GGNN 8 个时间步,计算出所有 < S L O T > <SLOT> <SLOT> token表示的平均值作为变量的表示。这个表示就被用作一个单层GRU的初始状态,以subtoken的形式预测目标名字。我们用极大似然来训练这种graph2seq结构。
针对VARMISUSE的程序图
为VARMISUSE建模我们需要修改这个图结构。首先,为了计算槽
t
t
t的上下文表示
c
(
t
)
\boldsymbol{c}(t)
c(t),我们在
t
t
t的位置插入一个新的结点
v
<
S
L
O
T
>
v_{<SLOT>}
v<SLOT>,当作这里有一个“洞”,然后将它与的剩下部分用除LastUse, LastWrite, LastLexicalUse和GuardedBy边之外的所有边相连。然后,为了计算目标槽的每个候选变量的表示
u
(
t
,
v
)
\boldsymbol{u}(t, v)
u(t,v),我们将每个
V
t
\mathbb{V}_t
Vt中的
v
v
v插入图中,然后为它们连LastUse, LastWrite, LastLexicalUse边。利用初始结点的表示加上一个额外为候选结点
v
t
,
v
v_{t, v}
vt,v设置的比特,我们运行GGNN 8次,最终得到了结点的最终状态。
c
(
t
)
=
h
(
v
<
S
L
O
T
>
)
,
u
(
t
,
v
)
=
h
(
v
t
,
v
)
\boldsymbol{c}(t) = \boldsymbol{h}^{(v_{<SLOT>})}, \boldsymbol{u}(t, v) = \boldsymbol{h}^{(v_{t, v})}
c(t)=h(v<SLOT>),u(t,v)=h(vt,v)
最后,这一位置的正确变量用法是这样计算的:
a
r
g
m
a
x
v
W
[
c
(
t
)
,
u
(
t
,
v
)
]
argmax_vW[\boldsymbol{c}(t), \boldsymbol{u}(t, v)]
argmaxvW[c(t),u(t,v)]
其中W是一个将c和u连接起来的线性层,我们利用max-margin objective来进行训练。
实现
介绍一些配置,GGNN开源。
评估
数据集
我们为VARMISUSE收集了一个开源
C
#
C^{\#}
C#数据集。我们挑选了Github上星最多的项目,过滤掉了其中不能完整编译的,最后我们的数据集中包含多个不同领域的29个项目,代码量共计290多万行。
对于检测变量误用,我们对所有使用变量的位置都进行了数据收集,过滤掉了变量声明。我们的任务就是从一些类型正确的变量中推断出某位置原本的变量。在我们的测试集中,每个槽平均有3.8个可选变量。
我们选择了两个项目作为我们的验证集。对于其他的项目,我们从中选择了三个作为UNSEENPROJECT,也就是说作为测试集并且其中包含从未见过的结构和类型。剩下的23个项目我们按6:1:3的比例划分为训练/验证/测试集,以文件为单位进行划分,这里的测试集我们叫做SEENPROJECT。
baseline
对于VARMISUSE,我们考虑两种基于双向RNN的方法作为baseline,分别称为LOC和AVGBIRNN。LOC是一个简单的两层双向GRU。对于baseline,
c
(
t
)
\boldsymbol{c}(t)
c(t)设置为由RNN算出的槽的表达,而每个变量的使用上下文
u
(
t
,
v
)
\boldsymbol{u}(t,v)
u(t,v)是名字和类型的映射,与GGNN的初始化标签用相同方法计算出来的。这个baseline的目的是评估上下文信息对任务的重要性。而AVGBIRNN是对LOC的一个改进,其中
u
(
t
,
v
)
\boldsymbol{u}(t, v)
u(t,v)是由另一个双层双向RNN计算的,然后对变量token v取平均。
对VARNAMING,我们用AVGLBL替代了LOC,它使用了log-bilinear模型。
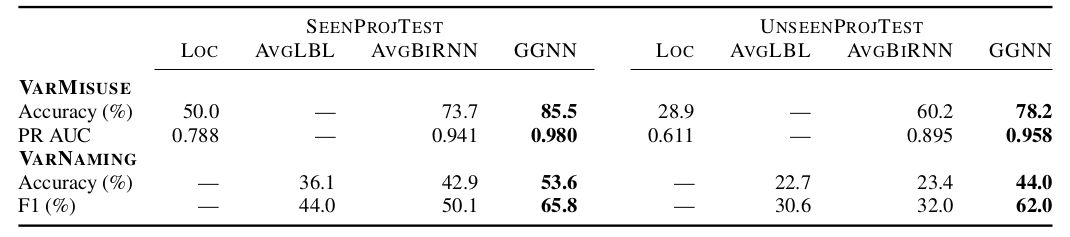
定量评估
下图是两个任务的评估结果:
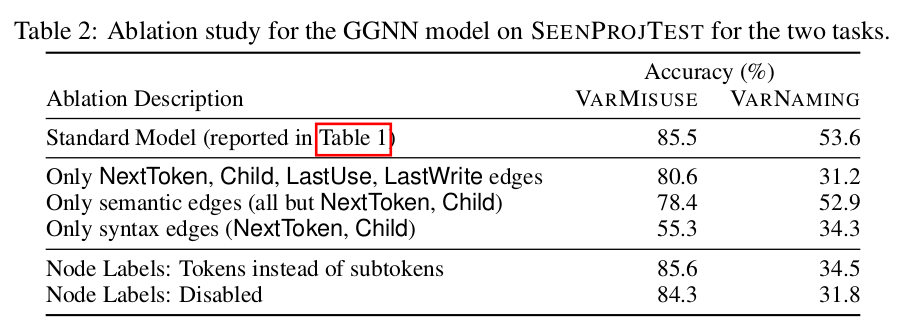
下图是不同边和结点表示对结果的影响。从表中可以看出如果只保留语法信息会对varNaming任务产生很大影响。
定性评估
下图是GGNN对一个代码片段中变量的预测结果:

查找变量误用bug
下图是GGNN找到的RavenDB中的bug,黄色部分应该是size而不是length。

问题记录
- 变量类型embedding的训练方法没交代,subtoken的embedding怎么来的也没有交代
按照文中这种完全没提的样子来看,这两部分embedding可能是随着模型参数一起训练的。那么数据集中变量有多少类型?有多少subtoken?如果数量庞大的话,作者用这个规模并进不很大的数据集是否会导致过拟合? - varmisuse部分的处理
按我的理解,作者在这边是先空出一个槽,用ComputedFrom等等的边学习出这个槽的表示。然后把所有候选词都作为结点加进这个网络中,再用LastWrite等等的边把这些结点连进这个图里。在GGNN跑了8个时间步后用槽和槽值(候选词)相乘,再做一个线性变换,取结果最大的那个候选词。我不确定我的理解是否正确,这种操作以前确实没有见过。并且槽的初始化是怎么做的呢?似乎文中也没有提及。

















 5189
5189

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









