





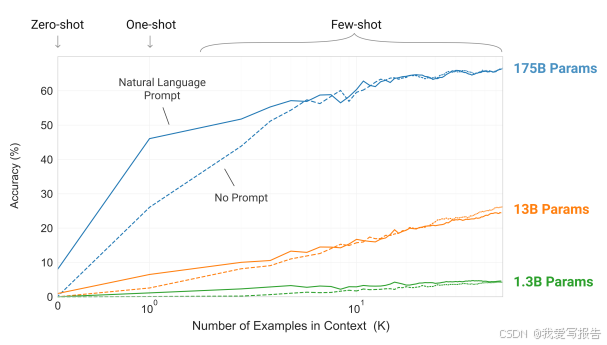
zero-shot, one-shot, few-shot, 上下文中example数, 有无prompt以及模型大小对模型性能的影响如上。
本文的主要工作是评估在不同的setting下GPT-3在各种任务中的评估结果如何。不同setting可以看作是模型依赖相关任务数据从多到少构成的一个系列,分别是fine-tune, few-shot, one-shot和zero-shot,它们的区别简单描述如下图所示:

模型
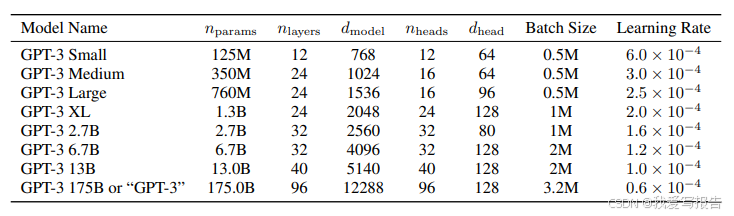
我们的模型基本沿用GPT-2,除了使用到了与Sparse Transformer类似的方法,在Transformer的各层交替使用密集attention和局部带状稀疏attention。为了研究ML性能和模型大小之间的相关性,我们训练了8个不同尺寸的模型,参数量从1.25亿到1750亿不等,其中最大的我们称为GPT-3。之前的研究表明,随着模型尺寸的增大,验证集的loss将会呈一个平滑的幂律曲线下降。下图是模型尺寸的详细说明。
训练数据
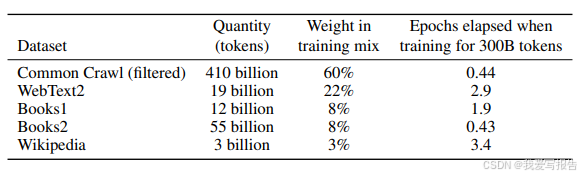
虽然CommonCrawl数据集中的token量就已经足够训练GPT3,但我们发现Common Crawl的质量不高。因此做了以下优化:1)我们根据一个高质量的reference集过滤了CommonCrawl的数据 2)对数据进行了文档层级的模糊去重,包括去掉了在验证集中出现过的文档以更好地评估模型是否过拟合 3)在CommonCrawl中加入了我们所知的高质量数据集。下表简单说明了我们数据集的组成。其中CommonCrawl过滤后的大小约为570GB,包含大约4000亿token。值得注意的是,在训练过程中数据集中的数据采样时高质量数据集会被采样得多一些。
模型
我们的模型基本沿用GPT-2,除了使用到了与Sparse Transformer类似的方法,在Transformer的各层交替使用密集attention和局部带状稀疏attention。为了研究ML性能和模型大小之间的相关性,我们训练了8个不同尺寸的模型,参数量从1.25亿到1750亿不等,其中最大的我们称为GPT-3。之前的研究表明,随着模型尺寸的增大,验证集的loss将会呈一个平滑的幂律曲线下降。下图是模型尺寸的详细说明。
训练过程
通过过往经验我们得知,更大的模型可以使用更大的batch size,然而需要更小的lr,我们通过度量训练期间的梯度噪声规模来决定batch size的选取。上面的表格展示了我们的参数设置。
评估
对于few-shot learning,我们从训练集里拿出K条样本作为条件,然后从测试集里采样1条或2条接在后面。对于没有专门训练集的任务,我们就从验证集里获取样本。

















 4174
4174

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









