




需求来源
在A公司总部,在一个B项目中需要公司旗下的分公司配合做上线支撑。针对每个分公司的不同需求都称为分公司的个性化需求。
分公司的业务部门认为一个dataset比较重要,不希望新系统上线之后让整个省份的用户都去重新选择一次,便把我们在其他分公司处理该数据集的成熟方案拒绝了。
该分公司的dataset都是存储在Oracle数据库中,但是新系统架构中考虑到成本问题选择的是mysql数据库,针对分公司Oracle数据库现有的近2亿数据量是无法支撑的。和分公司业务部磨皮了一段时间,大家相互退一步,分公司同意了不用全部dataset,改用了近一年的用户使用系统的dataset.
提取去重后也约有4500w左右,考虑到公司规定和性能,单表不能存较多的数据,所以对4500w的数据需要分表处理。按照一张表450w来存储,用10张表即可。
如何分表
分表是采用的是水平分表策略,使用场景只是单表的数据量太多,影响了SQL效率,加重了CPU负担,以至于成为瓶颈。当表的数据量少了,单次SQL执行效率高,自然减轻了CPU的负担。
例如:我有一张表user_info,里面数据太多我要分一下,分两张表user_info1和user_info2。
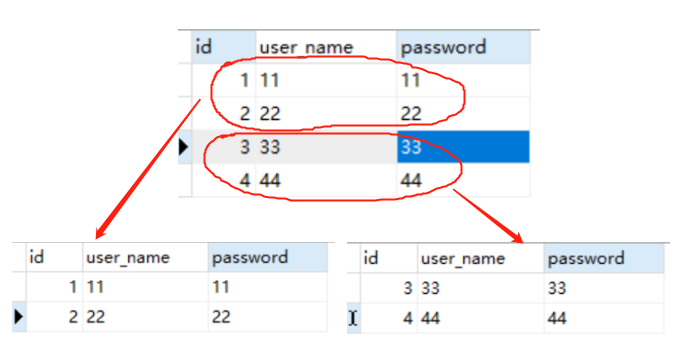
分表一般都是按照一定规范,将一张表的数据平均的分配到各表中。表的主键是手机号码,通过手机号码去进行分表。
要用到分表工具吗?暂时不用,毕竟不是相同数据库下的数据迁移。需要从Oracle库中取出近一年的活跃dataset文件,放在文件服务器上再进行处理才行。如何把手机号码做分表处理呢?
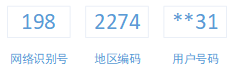
我国使用的号码为11位,其中各段有不同的编码方向:前3位为网络识别号;第4-7位是地区编码;第8-11位是用户号码。之后最后四位是随机生成的,前面7位都是规定的。
网上都是说自己搞个hash算法去对号码做hash运算均匀分配,或者通过不同号段(前三位)去分配。首先号段肯定是不行的,138号段和198号段的用户量根本就不是一个量级的,没法放在一个数量级上分配。用hash对4500w多个号码处理也是一个很大的任务量,也不实用。
最后考虑了一下,选择用最后两位做区分(一位随机性太大,三或四位随机性太小)。因为考虑到用户的习惯,“2”、“4”字不太受欢迎、“6”、“8”比较受欢迎,而且手机号码后四位是随机号码,从概率学角度可以认为是分配均匀的,又为了减少“4444”、“6666”等因素的影响,所以我们采用最后两位来进行划分。
| 尾号后两位 | 进表例子 | 不进表例子 |
| 00-09 | 198****9901 | 198****9941 |
| 10-19 | 198****9911 | 198****9941 |
| ...... | ...... | ...... |
| 80-89 | 198****9981 | 198****9931 |
| 90-99 | 198****9991 | 198****9931 |
public String judgeTable(String number) {
// 加一些判断number为不为空,长度是不是11位什么的
int lastNum = Integer.parseInt(number.substring(number.length()-2));
int result = lastNum / 10;
String tableName = "";
switch (result) {
case 0:
tableName = "table0";break;
case 1:
tableName = "table1";break;
case 3:
tableName = "table2";break;
// ...
case 9:
tableName = "table9";break;
default:
break;
}
return tableName;
}
本机Navicat记录mysql5.7数据库性能效果如下图,生产环境数据库的性能是要优于下表数据的。
|
InnoDB | ||
| 数据量 |
单条查询 |
单条修改 |
|
1000w |
0.031s |
0.047s |
|
2000w |
0.031s |
0.031s |
|
3000w |
0.031s |
0.046s |
|
4000w |
0.032s |
0.047s |
|
5000w |
0.032s |
0.062s |
|
6000w |
0.047s |
0.046s |
|
平均值 |
0.034s |
0.0465s |
因为InnoDB存储引擎底层结构是B+Tree结构,只要单表数据不过亿,各个数据量级的查询时间基本无太大差异。
数据入库
最后就是数据入库了,首先是把4500w的数据先用脚本,按照上面代码分成10个文件。实际效果是最少文件有440w行数据,最多文件有470w左右数据。差值还是可以接受的,证明了我们的方法可行。
代码首先把文件服务器上文件下载过来然后一个文件一个文件去读取,然后拼接sql入库。为了防止内存溢出,先设置BufferReader对象为200MB做缓存读取,然后先读2000行数据,用StringBuilder拼接一个sql做提交一次(减少多次提交所消耗的时间)。
代码在测试数据库执行一个文件约15-20min,晚上在生产上操作则是3-4min左右一个,时间还是可以的。关于大量数据插入数据库在网上也有很多教程,有所先对mysql表做一下配置,当数据全部插入完之后再让数据库的索引生效去排数据(小公司或个人应该可以使用这种方法,中大型公司的生产数据库你根本没权限乱动)。

三趾树懒
三趾树懒,是树懒科、树懒属的哺乳动物。三趾树懒头小而圆,体长50-60厘米,身上针毛长而粗糙。身上被毛原是灰棕色,后显绿色。三趾树懒终生在树上生活,在地面不能站立和行走,但能游泳,视觉和听觉差,主要靠嗅觉和触觉觅食,仅以几种桑科植物的嫩枝、幼叶及芽为食,是世界上行动最缓慢的动物之一。主要栖息于热带森林潮湿的树梢密叶中,分布于巴西、圭亚那、苏里南、委内瑞拉玻利瓦尔共和国。
种群分布不零散。1999年,在圭亚那,种群密度估计1.7只/平方公里。2008年,在巴西玛瑙斯,种群密度为221只/平方公里。2013,至少130只三趾树懒被发现生活在苏里南的一个0.07平方公里孤立的森林里。
列入《世界自然保护联盟》(IUCN)2014年濒危物种红色名录ver 3.1——无危(LC)。


















 1595
1595

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









