




一、基本概念
- 同步:使用同步IO时,Java自己处理IO读写。(同步就是发起一个调用后,被调用者未处理完请求之前,调用不返回)
- 异步:使用异步IO时,Java会将IO读写委托给OS处理,需要将数据缓冲区地址和大小传给OS,OS需要支持异步IO操作API。(异步就是发起一个调用后,立即得到被调用者的回应表示已接收到请求,但是被调用者并没有返回结果,此时,我们可以处理其他请求,被调用者通常依靠事件,回调等机制来通知调用者其返回结果)
- 阻塞:使用阻塞IO时,Java调用会一直阻塞到读写完成才返回。(阻塞就是发起一个请求,调用者一直等待请求结果返回,也就是当前线程会被挂起,无法从事其他任务,只有当条件就绪才能继续)
- 非阻塞:使用非阻塞IO时,如果不能读写Java调用会立马返回,当IO事件分发器会通知可读写时再继续进行读写,不断循环知道读写完成。(非阻塞就是发起一个请求,调用者不用一直等着结果返回,可以先去干其他事情)
通俗理解:
- 同步:自己亲自出马持银行卡去银行取钱。
- 异步:委托一个小弟拿银行卡去银行取钱,然后给你。
- 阻塞:ATM排队取款,你只能等待。
- 非阻塞:柜台取款,取个号,然后坐在椅子上可以做其他事情,等号广播会通知你办理,没有号你就不能去,你可以不断问大堂经理排到了没有,大唐经理如果说还没有到你就不能去。
二、Linux中的五种IO模型
网络IO的本质就是socket的读取,socket在Linux系统中被抽象为流,IO可以理解为对流的操作。对于一次IO访问(以read为例),数据会先被拷贝到操作系统内核的缓冲区中,然后才会从操作系统内核的缓冲区拷贝到应用程序的地址空间。所以,当一次read操作发生时,它会经历两个阶段,第一个阶段是等待数据准备,第二个阶段是将数据从内核拷贝到进程中。对于socket流而言,第一阶段是等待网络上的数据分组到达,然后复试到内核的某个缓冲区,第二阶段是将数据从内核缓冲区复制到应用进程的缓冲区中。
分类:
- 阻塞IO模型
- 非阻塞IO模型
- IO复用模型
- 信号驱动IO模型
- 异步IO模型
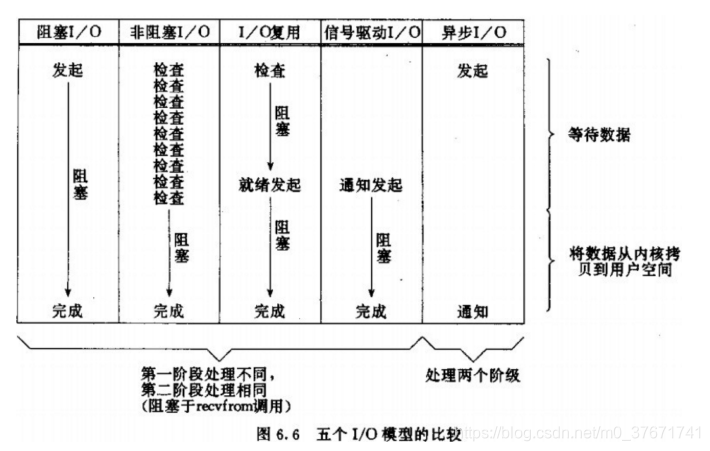
注意:阻塞IO模型,非阻塞IO模型,IO复用模型,信号驱动IO模型都属于同步,只有异步IO模型才属于异步。
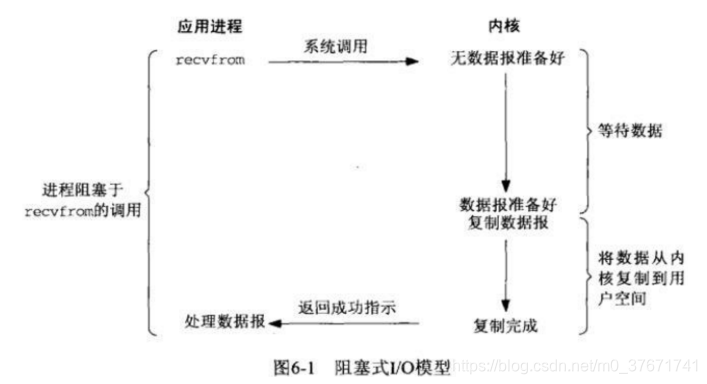
1、阻塞IO模型
进程会一直阻塞,直到数据拷贝完成。
阻塞IO模型中,用户空间的应用程序执行一个系统调用,这会导致应用程序阻塞,什么也不干,直到数据准备好,并且将数据从内核复制到用户进程,最后进程再处理数据,在等待数据到处理数据的两个阶段,整个进程都被阻塞,不能处理别的网络IO。
当用户进程调用了recv()/recvfrom()这个系统调用后,kernel就开始了IO的第一个阶段,准备数据(对于网络IO来说,很多时候数据在一开始还没有到达,例如,还没有收到完整的UDP包,这个时候kernel就要等待足够的数据到来)。这个过程需要等待,也就是说数据被拷贝到操作系统内核的缓冲区中是需要一个过程的。而在用户进程这边,整个进程会被阻塞(当然是进程自己选择的阻塞)。第二个阶段:当kernel一直等到数据准备好了,它就会将数据从kernel中拷贝到用户内存,然后kernel返回结果,用户进程才解除阻塞的状态,重新运行起来。
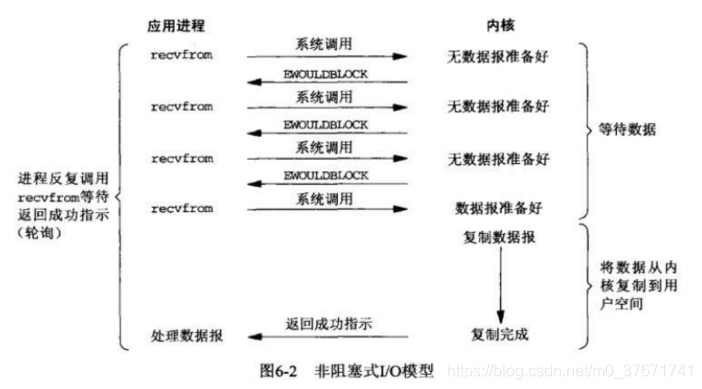
2、非阻塞IO模型
进程反复调用IO函数(多次系统调用,并马上返回),在数据拷贝过程中,进程是阻塞的。
非阻塞IO模型,用户空间的应用程序执行一个系统调用之后,进程没有被阻塞,内核马上返回给进程,如果数据还没有准备好,此时会返回一个error。进程再返回之后,可以干点别的事情,然后再发起recefrom系统调用。重复上面的进程,循环往复的进行recefrom系统调用。这个过程通常称为轮询。轮询发起系统调用,检查内核数据,知道数据准备好,再拷贝数据到进程,进行数据处理。
当用户进程发出read操作时,如果kernel中的数据还没有准备好,那么它不会阻塞用户进程,而是立即返回一个error。从用户进程角度讲,它发起一个read操作后,并不需要等待,而是马上得到了一个结果。用户进程判断结果是一个error时,它就知道数据还没有准备好,于是它可以再次发送read操作。一旦kernel中的数据准备好了,并且又再次收到了用户进程的system call(系统调用),那么它马上就将数据拷贝到用户内存,然后返回。
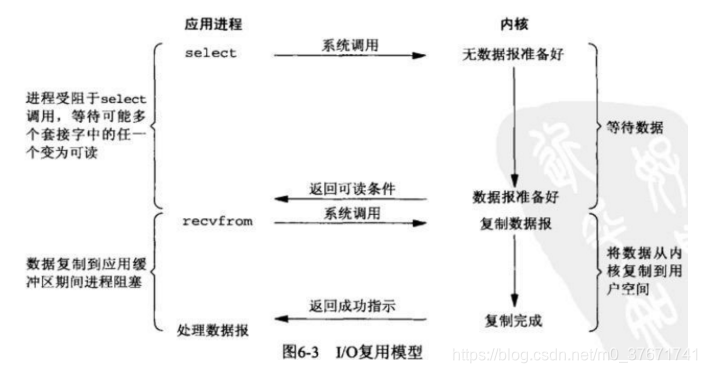
3、IO复用模型
同时对多个IO端口进行监视。
由于非阻塞IO模型需要不断主动轮询,轮询占据了很大一部分过程,轮询会消耗大量的CPU时间,而后台可能由多个任务在同时进行,人们就想到循环查询多个任务的完成状态,只有有一个任务完成,就去处理它。如果轮询不是进程的用户态,而是有人帮忙就好了(轮询在内核态),这就是所谓的IO复用模型。Linux下的select,poll,epoll都是干这个的。
例如select函数调用是内核级别的,select轮询相对非阻塞IO模型的轮询区别在于---select轮询可以等待多个socket,能实现同时对多个IO端口进行监听,当其中任何一个socket的数据准备好了,就能返回进行可读,然后进程再进行recvfrom系统调用,将数据由内核拷贝到用户进程,当然这个过程也是阻塞的。select调用之后,会阻塞进程,与阻塞IO模型不同在于,此时的select不是等到socket数据全部到达再处理,而是有一部分数据就会调用用户进程来处理。即:监视的事情交给了内核,内核负责数据到达的处理。
IO复用模型会用到select,poll,epoll函数,这几个函数也会使进程阻塞,但是和阻塞IO模型不同的是,这些函数可以同时阻塞多个IO操作。而且可以同时对多个读操作,多个写操作的IO函数进行检测,直到有数据可读或可写时,才真正调用IO操作函数。
IO复用模型,也就是我们说的select,poll,epoll,有些地方也称这种IO方式为事件驱动IO模型,通过把多个IO阻塞复用到同一个select的阻塞上,从而使得系统在单线程的情况下可以同时处理多个客户端的请求。select,poll,epoll的好处就在于单个线程就可以同时处理多个网络连接的IO。它的基本原理就是select,poll,epoll会不断轮询所负责的所有socket,当某个socket有数据到达了,就通知用户进程。即当用户进程调用了select,那么整个进程会被阻塞,而同时,kernel会监视所有select负责的socket,当任何一个socket中的数据准备好了,select就会返回。这个时候,用户进程再调用read操作,将数据从kernel拷贝到用户进程。(监视方式分为select,poll,epoll三种方式)
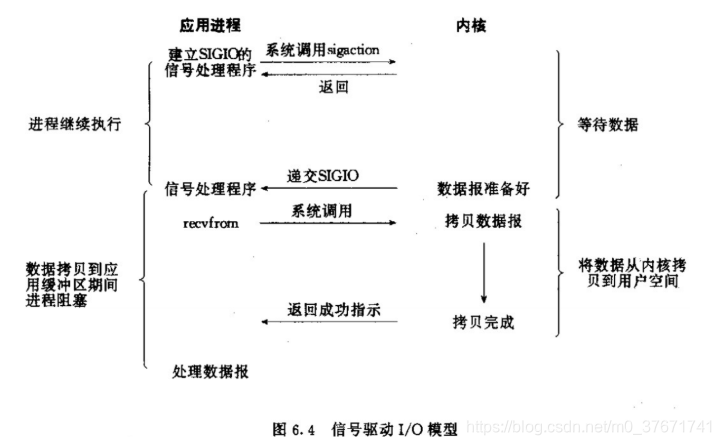
4、信号驱动IO模型
信号驱动IO模型,首先我们允许socket进行信号驱动IO,并安装一个信号处理函数,进程继续运行并不阻塞。当数据准备好后,进程就会收到一个sigIO信号,可以在信号处理函数中调用IO操作函数处理数据。
5、异步IO模型
数据拷贝的时候进程无需阻塞。
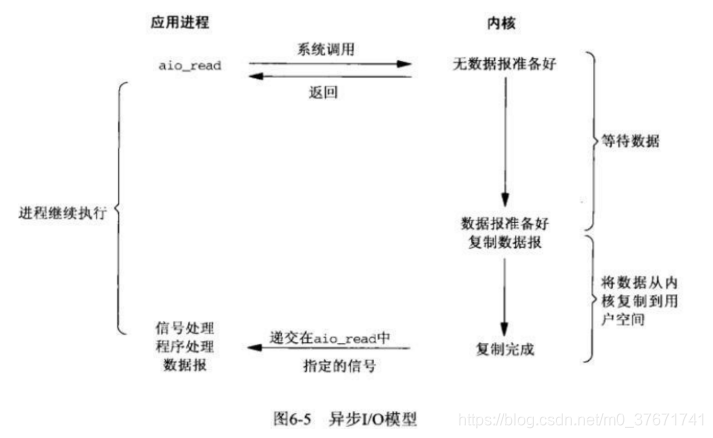
用户进程发起aio_read操作之后,立即就可以开始去做其他的事。而另一方面,从kernel的角度,当它收到一个异步read之后,首先它会立刻返回,所以不会对用户进程产生任何阻塞。然后,kernel会等待数据准备完成,然后将数据拷贝到用户内存,当这一切都完成之后,kernel会给用户进程发送一个signal或执行一个基于线程的回调函数来完成这次IO处理过程,告诉它read操作完成了。
总结:
- 阻塞IO模型:在内核将数据准备好之前,系统调用会一直等待所有的套接字,默认的是阻塞方式。
- 非阻塞IO模型:每个客户询问内核是否有数据准备好,即文件描述符缓冲区是否就绪,当有数据报准备好时,就进行拷贝数据报的操作。当没有数据报准备好时,也不阻塞程序,内核直接返回未准备好的信号,等待用户程序的下一个轮询。(轮询 对于cpu来说是较大的浪费)
- IO复用模型:IO复用模型是多了一个select函数,select函数有一个参数是文件描述符集合,对这些文件描述符进行循环监听,当某个文件描述符就绪时,就对这个文件描述符进行处理。(select只负责等,recvfrom只负责拷贝,IO复用模型属于阻塞IO,但可以对多个文件描述符进行阻塞监听,所以效率较阻塞IO的高)
- 信号驱动IO模型:信号驱动IO模型,应用进程告诉内核:当数据报准备好的时候,给我发送一个信号,对SIGIO信号进行捕捉,并且调用我的信号处理函数来获取数据报。
- 异步IO模型:当应用程序调用aio_read时,内核一方面去取数据报内容返回,另一方面将进程控制权还给应用进程,应用进程继续处理其他事情,是一种非阻塞的状态。当内核中有数据报就绪时,由内核将数据拷贝到应用程序中,返回aio_read中定义好的函数处理程序。
参考文献:
https://www.jianshu.com/p/486b0965c296(简书:猿码架构)
https://mp.weixin.qq.com/s?__biz=Mzg3MjA4MTExMw==&mid=2247484746&idx=1&sn=c0a7f
9129d780786cabfcac0a8aa6bb7&source=41&scene=21#wechat_redirect(漫画编程)
三、select,poll,epoll解析
IO多路复用出现的场景是:我们要设计一个高性能的网络服务器,这个服务器可以供多个客户端同时进行连接,并且能处理这些客户端传上来的请求。如何解决这个设计问题呢?
第一种方案是为了应对并发,写一个多线程的程序,每个传上来的请求都是一个线程,例如现在很多RPC的框架也是应用这种多线程的方式,但是多线程的方式存在一个很大的弊端,那就是cpu需要上下文切换,当客户端的连接非常多的时候,上下文的切换带来的代价是非常的高,因而多线程并不是一种最好的解决方案。
第二种方案是利用单线程,解决大量的客户端连接。我们知道在Linux系统中,一切都是文件,每一个网络连接在内核中都是以文件描述符(FD)来表示。利用单线程,写一个网络服务器,伪代码如下:
while(1){
//假设服务器有5个网络连接,分别是A,B,C,D,E
//依次遍历5个网络连接,即遍历5个文件描述符
for(FDx in (FDA-FDE)){
if(FDx 有数据){
读取FDx中的数据;
对FDx中的数据进行处理;
}
}
}这样简单粗暴的方式,可以解决该问题。但是,这种方式仍然有弊端,因为在判断文件描述符是否有数据的时候,是通过我们的应用程序来进行判断,这样的效率是比较低的。
1、select解析
select源码:

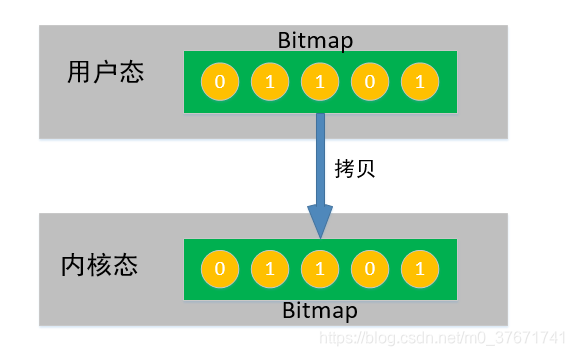
select函数接收的第二个参数:rset代表读文件描述符,但是rest不是直接接收文件描述符(FD)的集合,而是接收了文件描述符(FD)集合的bitmap,bitmap用来表征哪一个文件描述符是被启用的或被监听的。例如,我们的文件描述符集合分别是1,2,5,7,9,则对应的bitmap表示为:0110010101000000.....其中被监听的文件描述符对应的bitmap为1,未被监听的文件描述符对应的bitmap为0。(其中bitmap的默认大小是1024位,在需要被监听的文件描述符那一位置1,在不需要被监听的文件描述符那一位置0,及bitmap中涵盖了文件描述符(FD)集合中的所有信息)
select在执行中被传入bitmap,即rset。其中select函数的执行流程如下:
我们的程序中,有一个bitmap用来记录所监听的文件描述符,而我们的程序运行在用户态空间。但是select函数在运行时,会将用户态空间的bitmap拷贝到内核态空间,并且由内核负责判断每个文件描述符是否有数据到来。相比于上面简单粗暴的方式,select将判断文件描述符是否有数据的任务交给了内核,内核判断的效率肯定比用户态判断的效率要要,主要是因为:用户态在判断的时候,也是要询问内核,因此有一个用户态和内核态的切换,并且每一次判断都需要进行用户态和内核态的切换。select函数将bitmap全量的拷贝到内核态,并且由内核直接判断哪个文件描述符有数据到来,如果没有数据,内核态会一直判断,整个程序呈阻塞状态,即select函数是一个阻塞函数,如果一直没有数据到来,程序会一直阻塞在select函数这一行。如果有数据到来,内核会将有数据的文件描述符在bitmap中置位(表征该文件描述符有数据到来),接下来select函数会返回,不再阻塞,即程序会运行到下面的一行。
优点:
- select将bitmap从用户态拷贝到内核态,并由内核负责判断哪个文件描述符有数据到达,当其中任何一个或多个有数据的时候,select函数会返回。
缺点:
- select函数中bitmap的默认大小是1024,大小有限
- 若文件描述符有数据到来,对应的bitmap置位,导致bitmap不可重用
- bitmap从用户态拷贝到内核态,仍然需要一定的开销
- select函数返回后,只知道bitmap中至少有一位被置位了,但并不知道是哪一位甚至哪几位被置位了,需要再次遍历
2、poll解析
poll源码:

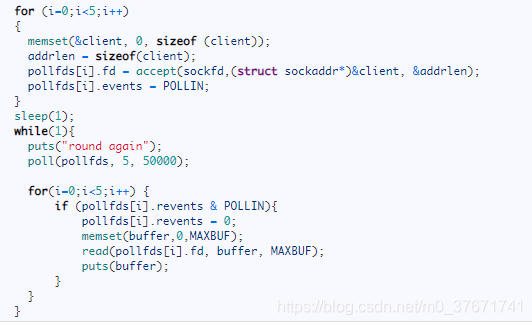
poll的工作原理与select类似,其改进之处在于:没有采用bitmap,而是采用了一种结构体pollfd。第一个字段fd代表文件描述符(FD),第二个字段events代表pollfd在意的事件,比如读的话在意pollin事件,写的话在意pollout事件,读和写都在意的话就是两者的与,第三个字段revents代表对events的回馈,初始状态是0,若有读事件,将其置位为POLLIN,若有写事件,将其置位为POLLOUT。
poll也是以一个阻塞函数,当有一个或多个文件描述符有数据的时候,内核将polldf中revents字段置位,并且poll函数会返回,不再阻塞。poll函数返回后,同样进行判断,判断revents是否被置位,若被置位,则说明有数据到来,在读数据,处理数据之前,会将revents恢复为0,以供下一轮循环的重复使用,即重用pollfds数组(包含多个pollfd结构体)。
优点:(poll相对于select的改进)
- poll函数使用pollfd结构体数组代替了bitmap,因而没有大小限制。
- poll函数利用pollfd结构体,每次置位revents字段,在读取的时候恢复初始化,因此pollfds可以重用。
缺点:
- 文件描述符信息从用户态拷贝到内核态,仍然需要一定的开销
- poll函数返回后,只知道pollfds中至少有一位被置位了,但并不知道是哪一位甚至哪几位被置位了,需要再次遍历
3、epoll解析
epoll源码:
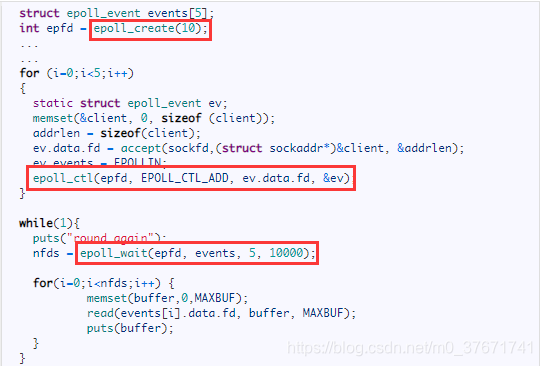
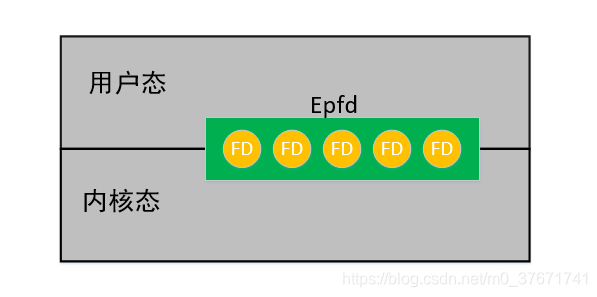
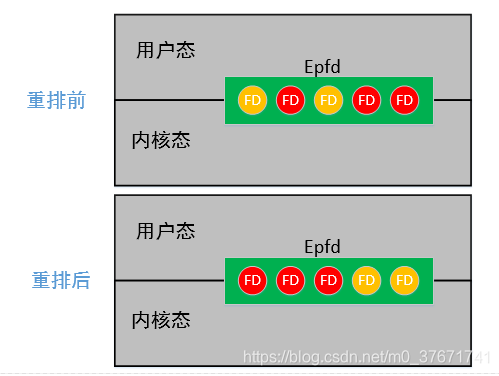
epoll函数分为三步:第一步使用epoll_create创建epfd;第二步使用epoll_ctl对epfd进行配置(添加fd-events),即若有五个文件描述符需要被监控,需要在epfd上添加五个fd-events字段;第三步使用epoll_wait,epfd在用户态和内核态是共享的(省去了select和poll中的拷贝),同时内核负责判断哪个文件描述符有数据到来。epoll_wait和select,poll函数一样,都是阻塞函数,当有数据到来,select和poll都会置位并返回,而epoll_wait通过"重排"置位,并返回有数据的文件描述符(FD)总数。此时,只需遍历数组的前面若干元素即可。
优点:(epoll相对于select的改进)
- epoll函数使用epfd数组,因而没有大小限制。
- epoll函数利用epfd“重排”置位,因此epfd可以重用。
- epoll函数的epfd在用户态和内核态共享,无需拷贝操作
- epoll函数对epfd进行“重排”置位,并返回有数据的文件描述符数量。在遍历读数据和处理时候,只需遍历重排后的前面若干元素即可。
epoll函数的应用:
- Redis
- Nginx
- Java NIO/(Linux系统中)

















 1035
1035

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









