




 本文介绍如何使用Python爬虫下载喜马拉雅平台上的音频文件。通过关键字搜索专辑,提取HTML信息,获取专辑ID和音频下载链接,然后下载并按专辑创建目录存储音频。代码包括获取页面源码、专辑信息、页面数、下载音频和建立目录等步骤。
本文介绍如何使用Python爬虫下载喜马拉雅平台上的音频文件。通过关键字搜索专辑,提取HTML信息,获取专辑ID和音频下载链接,然后下载并按专辑创建目录存储音频。代码包括获取页面源码、专辑信息、页面数、下载音频和建立目录等步骤。
点击上方"Python知识圈",选择"置顶公众号"
第一时间关注 Python 技术干货!
阅读文本大概需要 5 分钟
学习,是一个长期的过程。学习的方式也是有很多种的,在家里时间有空闲时间的话可以选择读书,如今在手机上看电子书也方便。pk哥最近看电子书比较多,感觉自己的视力明显下降了。停下来不学习又不行,我想到用听的方式去学习,如今各平台上音频文件还是比较丰富的。大家听得比较多的应该就是喜马拉雅这个平台了。今天我用 Python 把喜马拉雅的音频通过输入关键字查询出来并下载保存在本地。
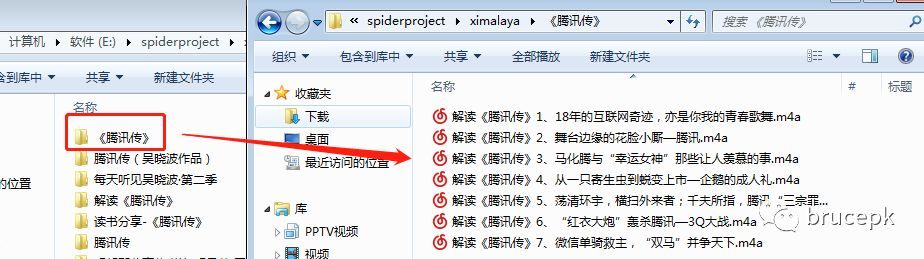
保存效果
我通过「腾讯传」关键字查询出 6 个音频专辑,以下为其中一个专辑里的 7 个音频文件。
项目环境
语言:Python3
编辑器:Pycharm
程序结构
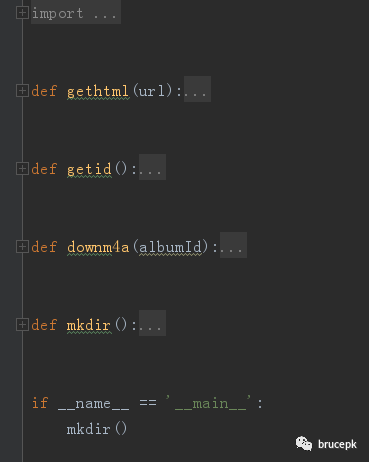
程序主要由四部分组成:
gethtml():提取页面 html 信息。
getid():获取通过关键字搜索的音
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1078
1078




 到【灌水乐园】发言
到【灌水乐园】发言







