




经常你会看到在代码中出现随着迭代步数的增加学习速率降低的步骤,这是因为越到收敛点学习速率越快的话可能会导致越过收敛点,导致发散的情况。
下面我将介绍两种学习速率的降低函数:
一、tf.train.exponential_decay()
函数原型:
tf.train.exponential_decay(
learning_rate,
global_step,
decay_steps,
decay_rate,
staircase=False,
name=None
)
learning_rate:一个整数,类型为float32,float64张量,或者是一个Python数字,初始化的学习速率
global_step:一个整数,类型为int32,int64张量,或者是一个Python数字。不能为负数
decay_steps:一个整数,类型为float32,float64张量或者是一个python数字,衰减速率。
staircase:布尔型,如果为True,不连续的区间进行学习率的衰减
name:操作的名字,可选,默认的是'ExponentialDecay'.
这个函数应用一个指数衰减在最初的学习速率上,需要global_step这个参数来计算衰减的学习率。你需要传递一个tensorflow的变量来在每一个训练步骤上进行增加。函数返回的是衰减的学习率。
计算公式:
decayed_learning_rate = learning_rate *
decay_rate ^ (global_step / decay_steps)
如果参数staircase是True,那么global_step/decay_steps是一个整数除,通俗的说就是每decay_steps才更新一次参数。
官网的例子:每一步都衰减,初始学习速率是0.1,
...
global_step = tf.Variable(0, trainable=False)
starter_learning_rate = 0.1
learning_rate = tf.train.exponential_decay(starter_learning_rate, global_step,
100000, 0.96, staircase=True)
# Passing global_step to minimize() will increment it at each step.
learning_step = (
tf.train.GradientDescentOptimizer(learning_rate)
.minimize(...my loss..., global_step=global_step)
)
代码:参考的是博客:https://blog.youkuaiyun.com/wuguangbin1230/article/details/77658229
import tensorflow as tf
from tensorflow.python.ops import math_ops,array_ops
import numpy as np
import matplotlib.pyplot as plt
learning_rate = 0.1
decay_rate = 0.96
global_steps = 5000
decay_steps = 100
global_ = tf.Variable(tf.constant(0))
c = tf.train.exponential_decay(learning_rate, global_, decay_steps, decay_rate, staircase=True)
d = tf.train.exponential_decay(learning_rate, global_, decay_steps, decay_rate, staircase=False)
T_C = []
F_D = []
with tf.Session() as sess:
for i in range(global_steps):
T_c = sess.run(c,feed_dict={global_: i})
T_C.append(T_c)
F_d = sess.run(d,feed_dict={global_: i})
F_D.append(F_d)
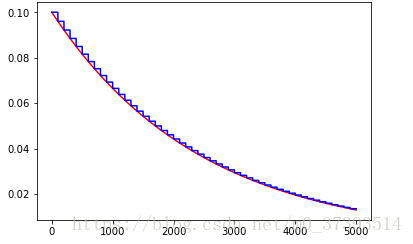
plt.figure(1)
plt.plot(range(global_steps), F_D, 'r-')
plt.plot(range(global_steps), T_C, 'b-')
plt.show() 结果:可以发现红色的试试staircase=False的情况,你会看到学习率每一步都在降低,staircase为True的情况,你会发现每隔100步衰减一次,你可以将global_step设置为1000看看结果!
二、tf.train.piecewise_constant()
函数原型:
tf.train.piecewise_constant(
x,
boundaries,
values,
name=None
)
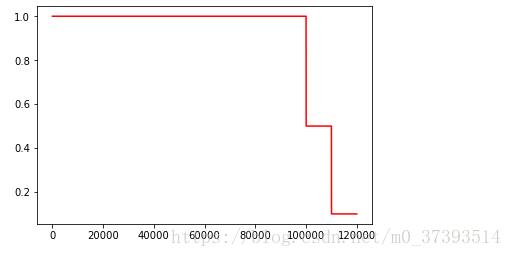
官网的例子:在开始的100001步学习率为1.0,接下来的10000步学习率为0.5,之后的步骤全部为0.1.
global_step = tf.Variable(0, trainable=False)
boundaries = [100000, 110000]
values = [1.0, 0.5, 0.1]
learning_rate = tf.train.piecewise_constant(global_step, boundaries, values)
# Later, whenever we perform an optimization step, we increment global_step.
参数:
x:一个0-D的整数张量,必须是下面的类型之一,float32,float64,uint8,int8,int16,int32,int64.
boundaries:一个张量的列表或者严格递增的int或者float组成的列表,当然了所有的元素的类型都必须跟x相同。
values:一个张量的列表,或者是float或者int组成的列表,指定由boundaries定义的区间的学习率。应该比boundaried元素多一个,且没个元素都有相同的类型。
name:可选的,操作的名字,默认为'PiecewiseConstant'.
返回:
一个0-D的张量;当x <= boundaries[0],学习率为values[0];当x > boundaries[0]且x <= boundaries[1],学习率为values[1] ..., 当 x > boundaries[-1],学习率是values[-1].
代码:
import tensorflow as tf
from tensorflow.python.ops import math_ops,array_ops
import numpy as np
import matplotlib.pyplot as plt
global_ = tf.Variable(0, trainable=False)
boundaries = [100000, 110000]
values = [1.0, 0.5, 0.1]
global_step=120000
learning_rate = tf.train.piecewise_constant(global_, boundaries, values)
res=[]
with tf.Session() as sess:
for i in range(global_step):
result = sess.run(learning_rate,feed_dict={global_: i})
res.append(result)
plt.figure(1)
plt.plot(range(global_step), res, 'r-')
plt.show() 结果;

















 6786
6786

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









