




 本文详细解析了ReduceByKey与GroupByKey在Spark中的工作原理与性能差异。ReduceByKey通过在Map端进行本地聚合,有效减少了数据的磁盘IO、网络传输量及Reduce端的内存占用,提升了整体执行效率。
本文详细解析了ReduceByKey与GroupByKey在Spark中的工作原理与性能差异。ReduceByKey通过在Map端进行本地聚合,有效减少了数据的磁盘IO、网络传输量及Reduce端的内存占用,提升了整体执行效率。
reduceByKey相较于普通的shuffle操作一个显著的特点就是会进行map端的本地聚合,map端会先对本地的数据进行combine操作,然后将数据写入给下个stage的每个task创建的文件中,也就是在map端,对每一个key对应的value,执行reduceByKey算子函数。reduceByKey算子的执行过程如图
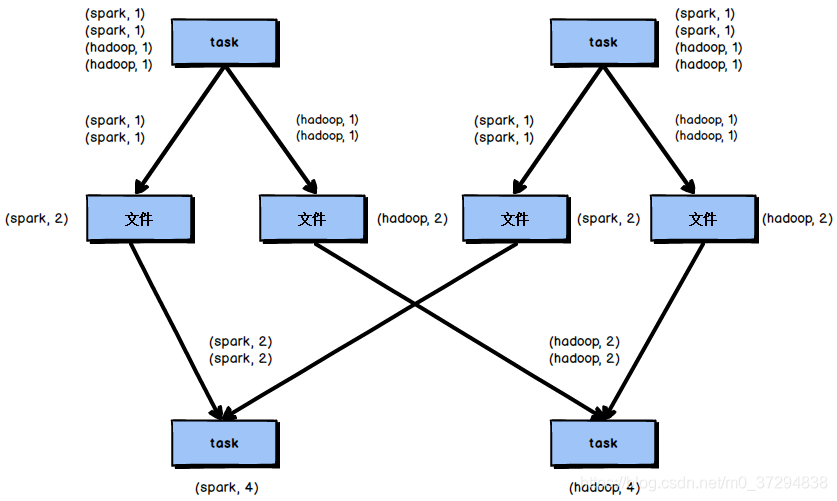
使用reduceByKey对性能的提升如下:
- 本地聚合后,在map端的数据量变少,减少了磁盘IO,也减少了对磁盘空间的占用;
- 本地聚合后,下一个stage拉取的数据量变少,减少了网络传输的数据量;
- 本地聚合后,在reduce端进行数据缓存的内存占用减少;
- 本地聚合后,在reduce端进行聚合的数据量减少。
基于reduceByKey的本地聚合特征,我们应该考虑使用reduceByKey代替其他的shuffle算子,
groupByKey不会进行map端的聚合,而是将所有map端的数据shuffle到reduce端,然后在reduce端进行数据的聚合操作。由于reduceByKey有map端聚合的特性,使得网络传输的数据量减小,因此效率要明显高于groupByKey。

















 2818
2818

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









