




 Pinpoint是一款用于大型分布式系统跟踪的平台,具备分布式事务跟踪、自动检测应用拓扑、字节码增强等功能。它通过javaagent技术进行插桩,收集并存储数据到HBase,Pinpoint Web展示应用的详细信息。文章介绍了Pinpoint的性能影响、巡检机制以及插件支持,指出其在性能优化方面采用采样、二进制格式和异步上报等策略。
Pinpoint是一款用于大型分布式系统跟踪的平台,具备分布式事务跟踪、自动检测应用拓扑、字节码增强等功能。它通过javaagent技术进行插桩,收集并存储数据到HBase,Pinpoint Web展示应用的详细信息。文章介绍了Pinpoint的性能影响、巡检机制以及插件支持,指出其在性能优化方面采用采样、二进制格式和异步上报等策略。
1. 笔记
1.1 介绍
[1]Pinpoint是一个韩国人开源的大型分布式系统的n层架构跟踪平台。特点有五:
- 分布式事物跟踪用于跟踪分布式应用的消息;
- 自动检测应用拓扑帮助理解应用架构;
- 可水平扩展支持大规模集群;
- 提供代码级可见功能以便发现问题和瓶颈;
- 字节码增强技术添加功能无需修改代码。
[5][6]架构
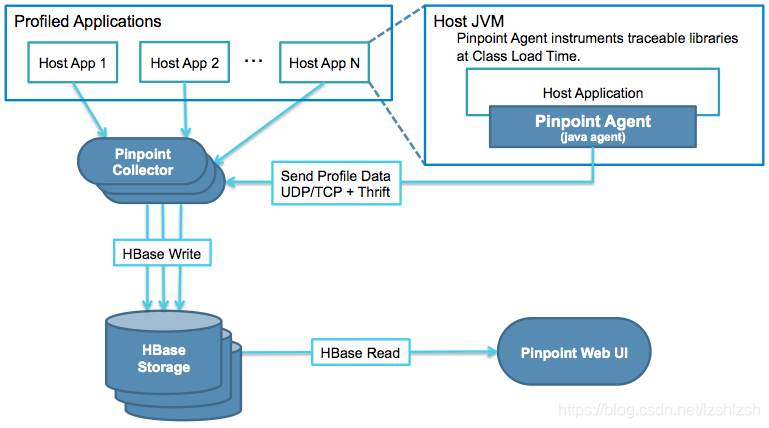
- Pinpoint agent使用javaagent技术对java应用插桩,对于标记了需要插桩的class,class装载时在预先定义的方法前后插入代码收集数据并发送到pinpoint collector。收集的数据包括trace数据、应用数据(包括jvm参数、装载的库、cpu内存使用、gc信息)
- Pinpoint collector接收agent的数据写入到HBase
- Pinpoint Web展示应用的拓扑结构,调用链,以及应用的其他信息
1.1.1 分布式事物跟踪
- 基于Google的Dapper论文。Dapper对rpc插桩传递span id和trace id,Pinpoint则在调用header中添加类似信息。
- 与Dapper的术语差异。Pinpoit统称span id、transaction id(Dapper的traceid)、parent span id为trace id
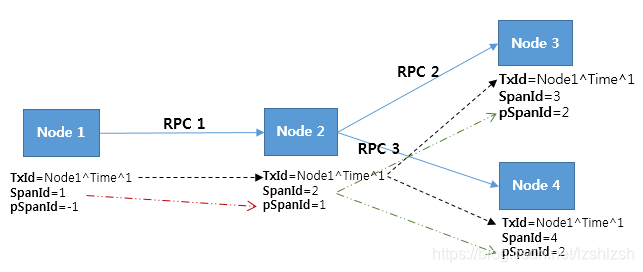
- TxId由三部分组成:AgentId(例如Node1)、JVM startup time、Sequence Number。Dapper以及twitter的Zipkin则为随机数,有冲突的可能性。
1.1.2 字节码增强
- 使用字节码增强的自动插桩技术的原因:长期收益大;隐藏API,可自由修改而无需受到用户的限制;方便开启和禁用
-javaagent:$AGENT_PATH/pinpoint-bootstrap-$VERSION.jar
-Dpinpoint.agentId=<Agent's UniqueId>
-Dpinpoint.applicationName=<The name indicating a same service (AgentId collection)>
1.1.3 Pinpoint agent性能优化
- 使用二进制格式提高编码效率。可以减少数据量提高网络使用效率,缺点是使用和调试困难。
- 使用变长编码,例如使用时间偏移减少单个时间占用的字节数。
- 使用常量表替换重复的Api、Sql、字符串等信息。在HBase存储其映射的Id,记录时只需记录ID。这里的ID 如何获取???
- 采样方法:计数采样,例如请求数计数到10时采样一次。
- 采用独立的线程异步上报数据,通过UDP上报。数据上报接口是分离的,可轻易替换为其他实现。
1.1.4 Pinpoint 示例
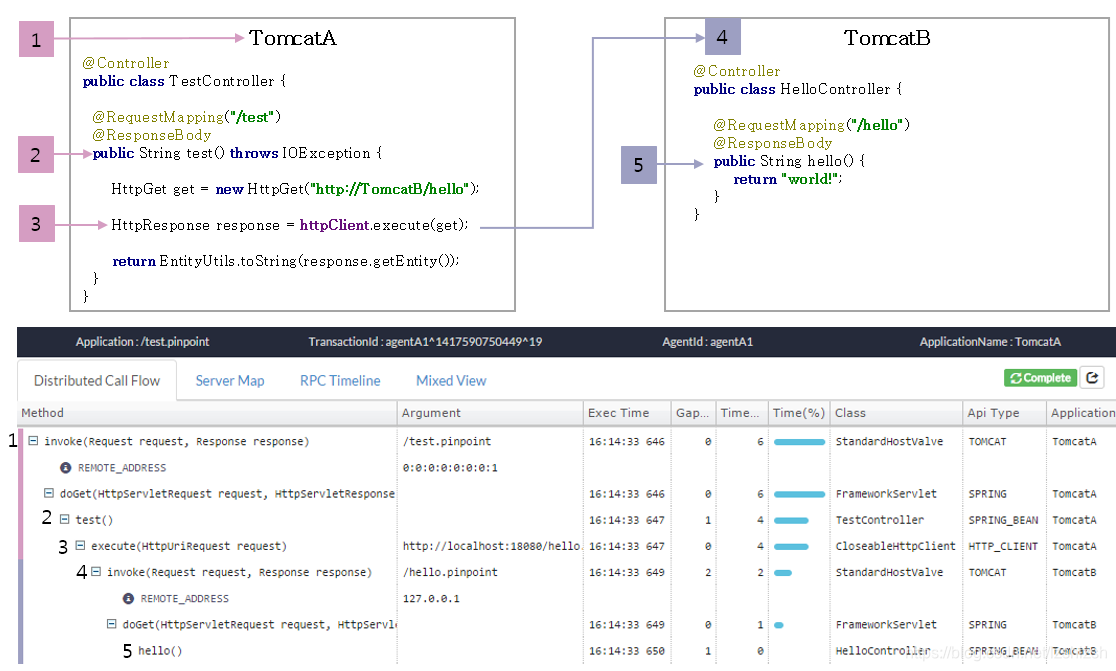
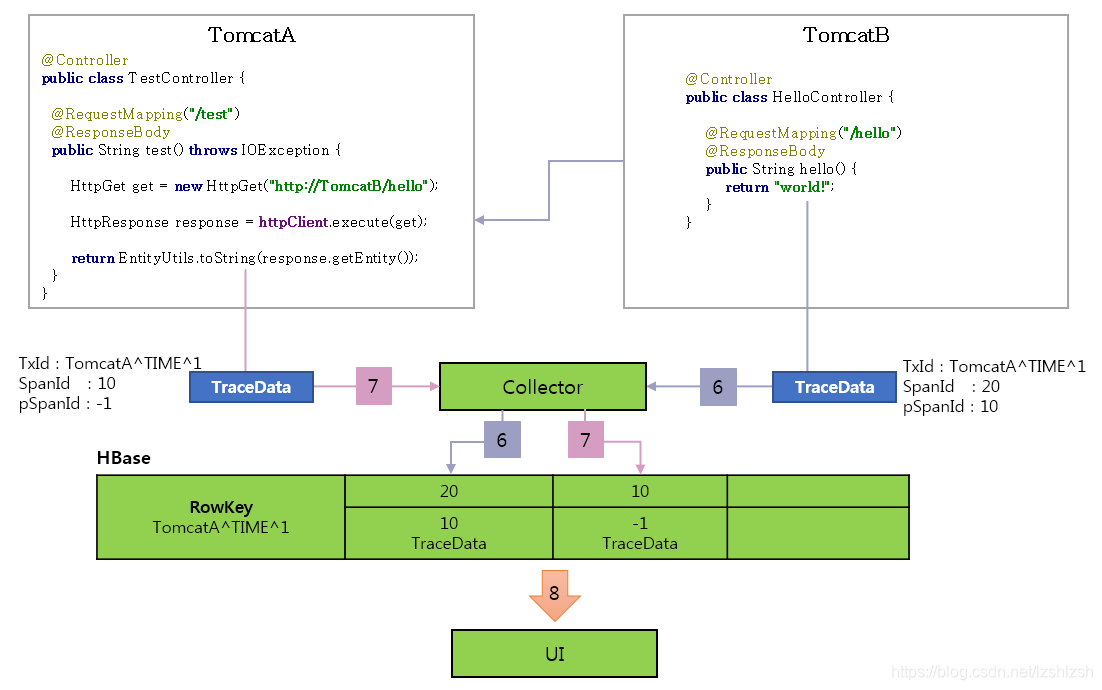
用户请求TomcatA,TomcatA调用TomcatB,形成一颗高度为2的调用树。要构建出这么一个树形结构,按如下过程记录信息[2]:
- 用户请求到达TomcatA。Tomcat已被javaagent字节码增强技术插桩,检查http header里是否有traceid信息,这里没有,因此生成traceid信息:
TxId:TomcatA^TIME^1、SpanId:10、parentid:-1。并记录start时间,整个请求结束时记录end时间 test函数被javaagent的字节码增强技术插桩,开始执行前和执行完成后可记录一些信息。httpClient.execute被插桩,在请求TomcatB前生成traceid信息(TxId:TomcatA^TIME^1、SpanId:20、parentid:10)并加入http header。这里会记录一些时间信息:client send、client recv- TomcatB的插桩与TomcatA一致,检查到http header里有traceid信息,直接取用。记录时间信息:
server recv即为本span的start,结束时记录server send即为本span的end hello函数记录一些信息。如果hello也有调用其他服务,那么同步骤3,会生成子span的traceid信息以及时间信息- TomcatB发送trace数据到Pinpoint collector,存储到HBase,每次请求对应一行数据,rowkey为txid,collumn为spanid,值为span的trace数据[2],包括:
span name、parent id、start、client send、server recv、server send、client recv、end、可选的kv格式的annotation。 - TomcatA发送trace数据到Pinpoint collector
- UI根据trace数据构建出调用链树,并可计算出每个部分的耗时。
1.2 性能
[4]对性能和内存的影响在3%以内。遇到性能问题时的检查点
- Pinpoint日志级别,默认为DEBUG
- JVM参数,建议使用G1GC,堆内存4G(
-Xms4G -Xmm4G) - 开启采样,大请求量场景1~2%的采样足够了
1.3 巡检
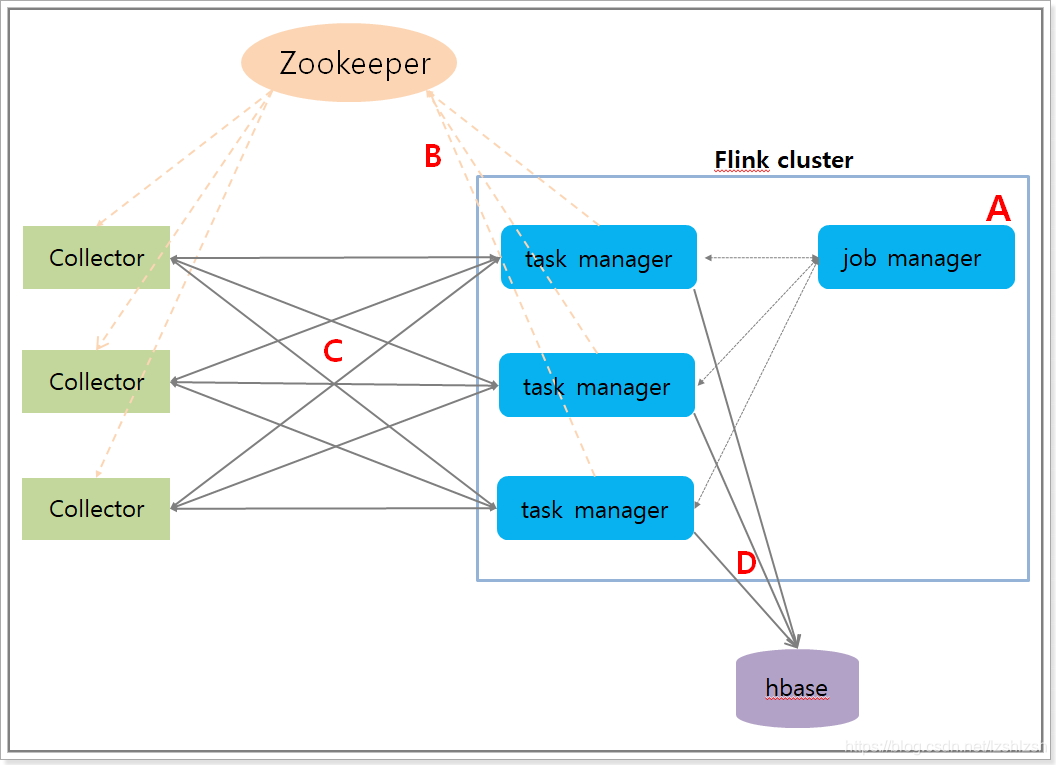
[7]应用巡检提供了应用的指标的聚合信息,包括CPU、内存、TPS、连接数等等。如下图所示,flink流式任务的task manager在zookeeper中注册,pinpoint collector从zookeeper中获得task manager信息,发送数据到flink,flink聚合数据并写入HBase。
1.4 插件
Pinpoint支持的组件[3]有限,参考[8]可开发自己的插件支持更多的组件。

















 1397
1397

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









