




接上文一步步教你如何使用用福昕低代码平台(一):实现PDF文档拆分,我们来看看如何用福昕低代码平台完成PDF中的图片提取,干脆继续原来的web工程,我把根目录改名成pdftools如下:
splitDemo/
├── public/
│ ├── index.html
│ ├── script.js
│ └── styles.css
├── server.js
└── package.json
要实现的功能
选择一个PDF文件,并提取指定页面范围内的图片,压缩到一个zip包下载。
工作流创建
进入福昕低代码平台创建一个工作流,包含三个组件,
Http触发器,ExtractPDF动作组件,DownloadPDF组件,
设置如下:
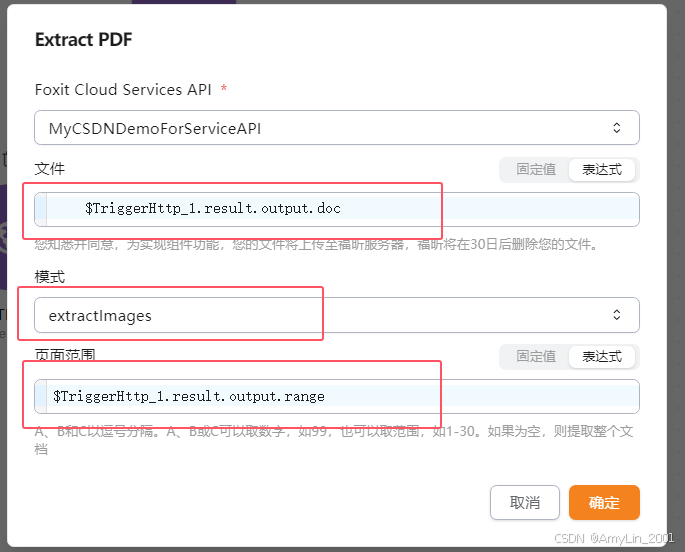
ExtractPDF组件设置
文件以及页面范围参数,均从触发器获取
- 文件:$TriggerHttp_1.result.output.doc
- 页面范围:$TriggerHttp_1.result.output.range
- 模式:extractImages
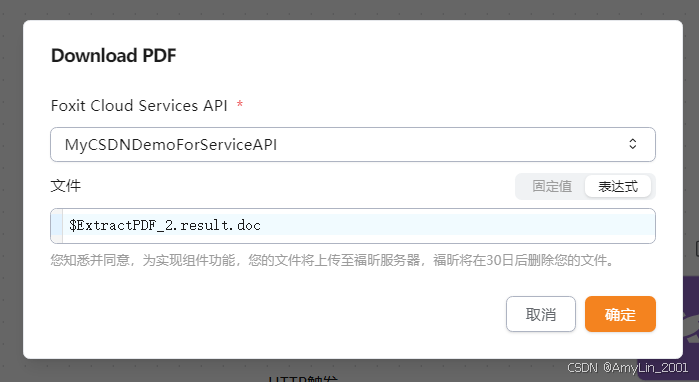
Download组件设置
我们下载组件生成的结果文档
文件:$ExtractPDF_2.result.doc
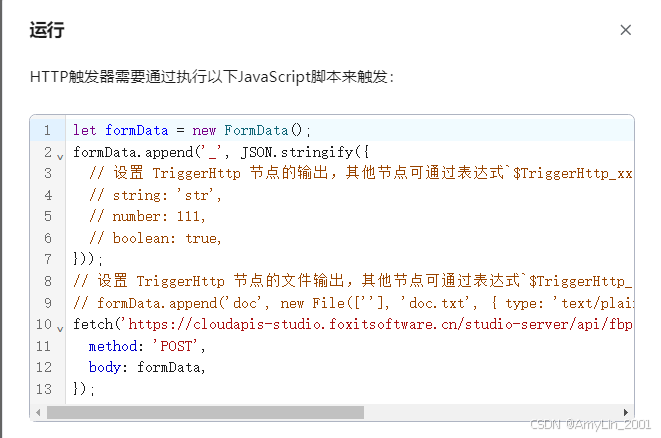
到这里,工作流创建完成,我们运行看看结果情况.
运行
Web网页的实现
前端HTML页面需要增加的内容
很简单,我增加一个文件选择器,一个用于输入页码范围的文本框,以及提取按钮如代码如下:
<h1>PDF图片提取小工具</h1>
<input type="file" id="pdfExtractImg" accept="application/pdf">
<input type="text" id="pageRange" placeholder="输入页码范围 (例如: 1-3)">
<button id="extractImgButton">提取图片</button>
<div id="extractResult"></div>
在这个HTML中,我们添加了一个新的文件选择器<input type="file" id="pdfExtractImg" accept="application/pdf">,一个用于输入页码范围的文本框<input type="text" id="pageRange" placeholder="输入页码范围 (例如: 1-3)">,以及一个提取按钮<button id="extractImgButton">提取图片</button>。
接下来,我们需要在script.js中添加相应的JavaScript代码来处理PDF图片提取
处理图片提取的JS代码
以下代码是"提取图片"按钮的实现代码,加入到原来的script.js后面
document.getElementById('extractImgButton').addEventListener('click', function() {
const fileInput = document.getElementById('pdfExtractImg');
const file = fileInput.files[0];
const pageRange = document.getElementById('pageRange'). 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









