




 本文详细介绍了Spark与Kafka整合的两种方式:Receiver和Direct模式。Receiver模式中,receiver线程从Kafka接收数据并备份,但存在数据丢失风险,可通过WAL解决。Direct模式下,每个executor直接从Kafka获取数据,任务数量等于topic的partition数,更适用于有ACL验证的场景。在实际应用中,Direct模式更为常见。
本文详细介绍了Spark与Kafka整合的两种方式:Receiver和Direct模式。Receiver模式中,receiver线程从Kafka接收数据并备份,但存在数据丢失风险,可通过WAL解决。Direct模式下,每个executor直接从Kafka获取数据,任务数量等于topic的partition数,更适用于有ACL验证的场景。在实际应用中,Direct模式更为常见。
spark和kafka整合有2中方式
1、receiver
顾名思义:就是有一个线程负责获取数据,这个线程叫receiver线程
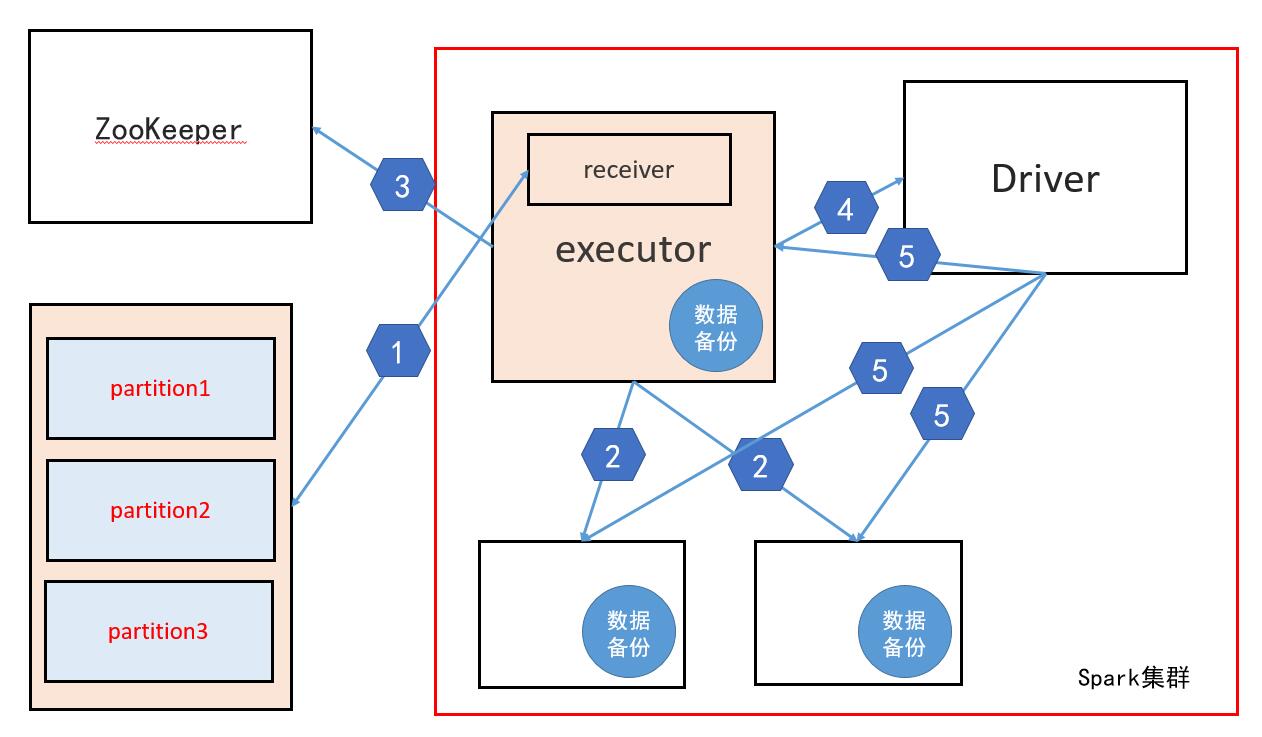
解释:
1、Spark集群中的某个executor中有一个receiver线程,这个线程负责从kafka中获取数据
注意:这里的获取数据并不是从kafka中拉(pull) 而是接收数据,具体原理是该receiver线程发送请求到kafka,这个请求包含对kafka中每个partition的消费偏移量(offset),然后由kafka主动的推送数据到spark中,再有该receiver线程负责接收数据
2、当receiver线程接收到数据后会做备份处理,即把数据备份到其他的executor中,也可能会备份到这个receiver线程所在节点的executor中
3、当备份完毕后该线程会把每个partition的消费偏移量在zookeeper中修改,(新版本的kafka的offset 保存在kafka集群中)
4、修改完offset后,该receiver线程会把"消费"的数据告诉Driver
5、Driver分发任务时会根据每个executor上的数据,根据数据本地性发送
问题:
当第三步执行完后,对于kafka来说这一批数据已经消费完成,那么如果此时Driver挂掉,那么这一批数据就会丢失,为了解决这个问题,有一个叫WAL逾写日志的概念,即把一部分数据存储在HDFS上,当Driver回复后可以从HDFS上获取这部分数据,但是开启WAL性能会受到很大的影响
2、dirct
直接连接:即每个executor直接取kafka获取数据
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 285
285

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









